 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning by Watching: Physical Imitation of Manipulation Skills from Human Videos
Paper and Code
Jan 18, 2021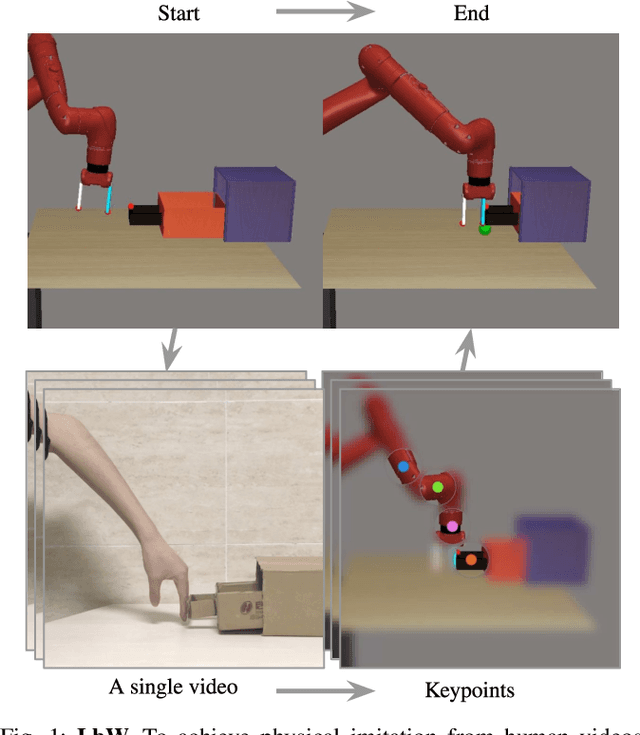
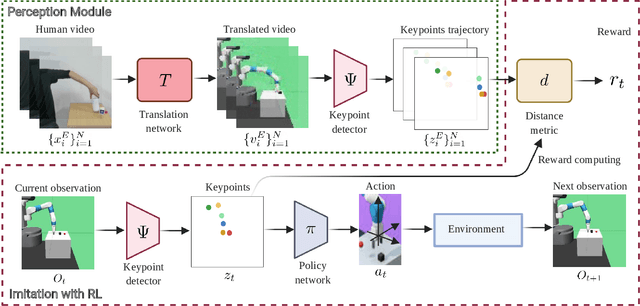
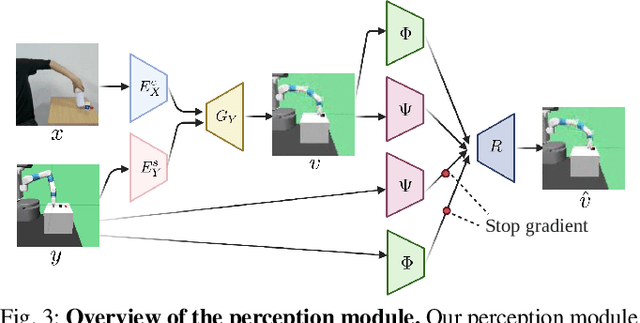

We present an approach for physical imitation from human videos for robot manipulation tasks. The key idea of our method lies in explicitly exploiting the kinematics and motion information embedded in the video to learn structured representations that endow the robot with the ability to imagine how to perform manipulation tasks in its own context. To achieve this, we design a perception module that learns to translate human videos to the robot domain followed by unsupervised keypoint detection. The resulting keypoint-based representations provide semantically meaningful information that can be directly used for reward computing and policy learning. We evaluate the effectiveness of our approach on five robot manipulation tasks, including reaching, pushing, sliding, coffee making, and drawer closing. Detailed experimental evaluations demonstrate that our method performs favorably against previous approaches.