 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction valuation of on- and off-ball soccer players based on multi-agent deep reinforcement learning
May 29, 2023



Analysis of invasive sports such as soccer is challenging because the game situation changes continuously in time and space, and multiple agents individually recognize the game situation and make decisions. Previous studies using deep reinforcement learning have often considered teams as a single agent and valued the teams and players who hold the ball in each discrete event. Then it was challenging to value the actions of multiple players, including players far from the ball, in a spatiotemporally continuous state space. In this paper, we propose a method of valuing possible actions for on- and off-ball soccer players in a single holistic framework based on multi-agent deep reinforcement learning. We consider a discrete action space in a continuous state space that mimics that of Google research football and leverages supervised learning for actions in reinforcement learning. In the experiment, we analyzed the relationships with conventional indicators, season goals, and game ratings by experts, and showed the effectiveness of the proposed method. Our approach can assess how multiple players move continuously throughout the game, which is difficult to be discretized or labeled but vital for teamwork, scouting, and fan engagement.
Adaptive action supervision in reinforcement learning from real-world multi-agent demonstrations
May 22, 2023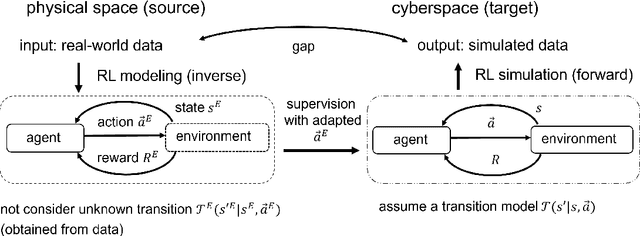
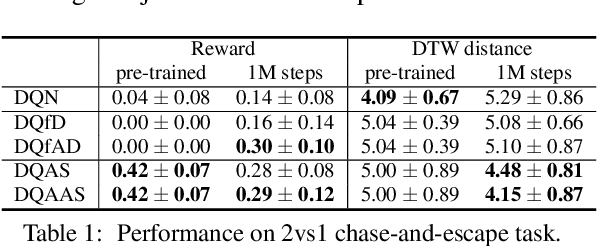
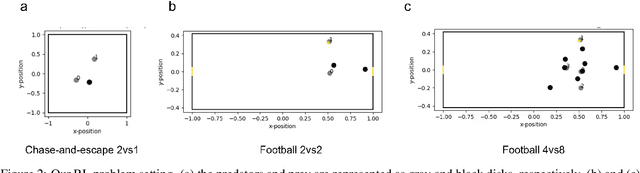

Modeling of real-world biological multi-agents is a fundamental problem in various scientific and engineering fields. Reinforcement learning (RL) is a powerful framework to generate flexible and diverse behaviors in cyberspace; however, when modeling real-world biological multi-agents, there is a domain gap between behaviors in the source (i.e., real-world data) and the target (i.e., cyberspace for RL), and the source environment parameters are usually unknown. In this paper, we propose a method for adaptive action supervision in RL from real-world demonstrations in multi-agent scenarios. We adopt an approach that combines RL and supervised learning by selecting actions of demonstrations in RL based on the minimum distance of dynamic time warping for utilizing the information of the unknown source dynamics. This approach can be easily applied to many existing neural network architectures and provide us with an RL model balanced between reproducibility as imitation and generalization ability to obtain rewards in cyberspace. In the experiments, using chase-and-escape and football tasks with the different dynamics between the unknown source and target environments, we show that our approach achieved a balance between the reproducibility and the generalization ability compared with the baselines. In particular, we used the tracking data of professional football players as expert demonstrations in football and show successful performances despite the larger gap between behaviors in the source and target environments than the chase-and-escape task.
Estimating the Effect of Team Hitting Strategies Using Counterfactual Virtual Simulation in Baseball
Jun 04, 2022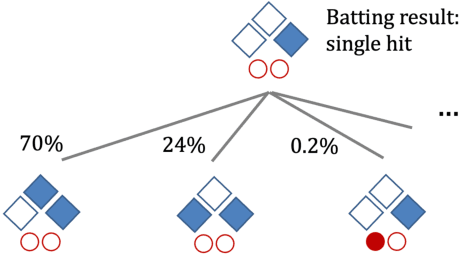
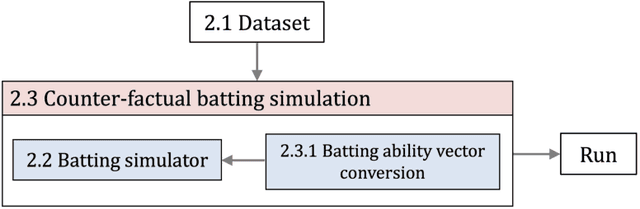
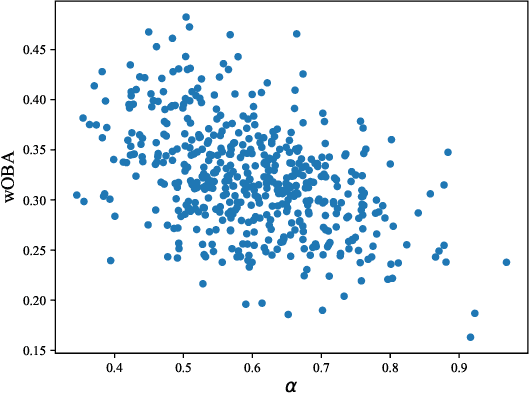
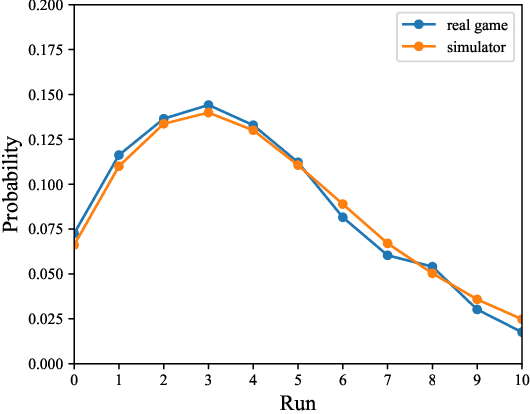
In baseball, every play on the field is quantitatively evaluated and has an effect on individual and team strategies. The weighted on base average (wOBA) is well known as a measure of an batter's hitting contribution. However, this measure ignores the game situation, such as the runners on base, which coaches and batters are known to consider when employing multiple hitting strategies, yet, the effectiveness of these strategies is unknown. This is probably because (1) we cannot obtain the batter's strategy and (2) it is difficult to estimate the effect of the strategies. Here, we propose a new method for estimating the effect using counterfactual batting simulation. To this end, we propose a deep learning model that transforms batting ability when batting strategy is changed. This method can estimate the effects of various strategies, which has been traditionally difficult with actual game data. We found that, when the switching cost of batting strategies can be ignored, the use of different strategies increased runs. When the switching cost is considered, the conditions for increasing runs were limited. Our validation results suggest that our simulation could clarify the effect of using multiple batting strategies.