 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEqOD: Symmetry-Informed Stability Selection for PDE Identification
May 12, 2026Data-driven identification of partial differential equations (PDEs) relies on sparse regression over a candidate library of differential operators, where larger libraries inflate false positives under observation noise and smaller libraries risk missing true terms. We introduce Equivariant Operator Discovery (EqOD), a fully automatic method combining two library reduction mechanisms. When Galilean invariance is detected from trajectory data via a weak-form structural test, EqOD uses the symmetry-reduced library, eliminating terms that our Galilean exclusion result proves to be absent from the governing equation. Otherwise, it applies randomized LASSO stability selection guided by classical false-positive bounds. A residual-based fallback prevents degradation below the full-library baseline. On 8 PDEs at 4 noise levels, EqOD attains $F_1 = 1.000 \pm 0.000$ on Heat at $20\%$ noise, where WF-LASSO obtains $0.475 \pm 0.181$, official PySINDy 2.0 obtains $0.000$, and the WSINDy reimplementation obtains $0.789$. Under the strict criterion that the mean F1 difference exceeds the larger of the two standard deviations, EqOD wins 7 of 32 cells. WF-LASSO wins none, and the remaining 25 cells are ties. Across all 32 cells, EqOD outperforms PySINDy 2.0.0 in 23 of 32 cells, and all 5 PySINDy wins occur on reaction PDEs. External validation on WeakIdent and PINN-SR datasets gives $F_1 = 1.000$ on all 5 clean benchmarks. NLS, 2D, coupled-system, and cylinder-wake extensions are reported. The Galilean library reduction is proved under explicit autonomy and library assumptions. The stability-selection step is motivated by classical false-positive bounds, while formal guarantees for correlated PDE design matrices remain open.
Per-Loss Adapters for Gradient Conflict in Physics-Informed Neural Networks
May 11, 2026Physics-informed neural networks (PINNs) train a single neural approximation by minimizing multiple physics- and data-derived losses, but the gradients of these losses often interfere and can stall optimization. Existing remedies typically treat this pathology either through scalar loss balancing or full-parameter-space gradient surgery, leaving it unclear which intervention is most appropriate. We show that PINN gradient conflict is not a uniform failure mode with one universal remedy. Instead, we identify distinct PINN gradient-conflict regimes, each associated with a different intervention class. Persistent directional conflict may require separate loss-indexed parameter subspaces, magnitude imbalance often favors scalar reweighting, and low or transient conflict may require no extra mitigation. To select between scalar reweighting and a lightweight architectural intervention, we propose a diagnostic-first framework. It profiles a 1000-step unmodified PINN run and, when intervention is warranted, uses one low-rank adapter per loss to create explicit loss-indexed parameter subspaces attached to a shared PINN trunk, providing each loss with a direct gradient pathway. Across more than 60 PDE configurations, including forward, inverse, multi-physics, parameter-varying, and high-dimensional problems up to 50D, persistent directional conflict dominates standard forward $K=3$ benchmarks and a natural $K=4$ thermoelastic system, where adapters combined with reweighting yield significant improvements. In contrast, $K=3$ inverse problems and natural $K=5$ and $K=6$ multi-physics systems are largely magnitude-dominated and often favor reweighting alone, while full-parameter-space gradient surgery can fail on heterogeneous parameter spaces.
Residual Koopman Spectral Profiling for Predicting and Preventing Transformer Training Instability
Feb 26, 2026Training divergence in transformers wastes compute, yet practitioners discover instability only after expensive runs begin. They therefore need an expected probability of failure for a transformer before training starts. Our study of Residual Koopman Spectral Profiling (RKSP) provides such an estimate. From a single forward pass at initialization, RKSP extracts Koopman spectral features by applying whitened dynamic mode decomposition to layer-wise residual snapshots. Our central diagnostic, the near-unit spectral mass, quantifies the fraction of modes concentrated near the unit circle, which captures instability risk. For predicting divergence across extensive configurations, this estimator achieves an AUROC of 0.995, outperforming the best gradient baseline. We further make this diagnostic actionable through Koopman Spectral Shaping (KSS), which reshapes spectra during training. We empirically validate that our method works in practice: RKSP predicts divergence at initialization, and when RKSP flags high risk, turning on KSS successfully prevents divergence. In the challenging high learning rate regime without normalization layers, KSS reduces the divergence rate from 66.7% to 12.5% and enables learning rates that are 50% to 150% higher. These findings generalize to WikiText-103 language modeling, vision transformers on CIFAR-10, and pretrained language models, including GPT-2 and LLaMA-2 up to 7B, as well as emerging architectures such as MoE, Mamba-style SSMs, and KAN.
Radial Müntz-Szász Networks: Neural Architectures with Learnable Power Bases for Multidimensional Singularities
Feb 09, 2026Radial singular fields, such as $1/r$, $\log r$, and crack-tip profiles, are difficult to model for coordinate-separable neural architectures. We show that any $C^2$ function that is both radial and additively separable must be quadratic, establishing a fundamental obstruction for coordinate-wise power-law models. Motivated by this result, we introduce Radial Müntz-Szász Networks (RMN), which represent fields as linear combinations of learnable radial powers $r^μ$, including negative exponents, together with a limit-stable log-primitive for exact $\log r$ behavior. RMN admits closed-form spatial gradients and Laplacians, enabling physics-informed learning on punctured domains. Across ten 2D and 3D benchmarks, RMN achieves 1.5$\times$--51$\times$ lower RMSE than MLPs and 10$\times$--100$\times$ lower RMSE than SIREN while using 27 parameters, compared with 33,537 for MLPs and 8,577 for SIREN. We extend RMN to angular dependence (RMN-Angular) and to multiple sources with learnable centers (RMN-MC); when optimization converges, source-center recovery errors fall below $10^{-4}$. We also report controlled failures on smooth, strongly non-radial targets to delineate RMN's operating regime.
Discovering Scaling Exponents with Physics-Informed Müntz-Szász Networks
Jan 30, 2026Physical systems near singularities, interfaces, and critical points exhibit power-law scaling, yet standard neural networks leave the governing exponents implicit. We introduce physics-informed M"untz-Sz'asz Networks (MSN-PINN), a power-law basis network that treats scaling exponents as trainable parameters. The model outputs both the solution and its scaling structure. We prove identifiability, or unique recovery, and show that, under these conditions, the squared error between learned and true exponents scales as $O(|μ- α|^2)$. Across experiments, MSN-PINN achieves single-exponent recovery with 1--5% error under noise and sparse sampling. It recovers corner singularity exponents for the two-dimensional Laplace equation with 0.009% error, matches the classical result of Kondrat'ev (1967), and recovers forcing-induced exponents in singular Poisson problems with 0.03% and 0.05% errors. On a 40-configuration wedge benchmark, it reaches a 100% success rate with 0.022% mean error. Constraint-aware training encodes physical requirements such as boundary condition compatibility and improves accuracy by three orders of magnitude over naive training. By combining the expressiveness of neural networks with the interpretability of asymptotic analysis, MSN-PINN produces learned parameters with direct physical meaning.
Temperature-Free Loss Function for Contrastive Learning
Jan 29, 2025As one of the most promising methods in self-supervised learning, contrastive learning has achieved a series of breakthroughs across numerous fields. A predominant approach to implementing contrastive learning is applying InfoNCE loss: By capturing the similarities between pairs, InfoNCE loss enables learning the representation of data. Albeit its success, adopting InfoNCE loss requires tuning a temperature, which is a core hyperparameter for calibrating similarity scores. Despite its significance and sensitivity to performance being emphasized by several studies, searching for a valid temperature requires extensive trial-and-error-based experiments, which increases the difficulty of adopting InfoNCE loss. To address this difficulty, we propose a novel method to deploy InfoNCE loss without temperature. Specifically, we replace temperature scaling with the inverse hyperbolic tangent function, resulting in a modified InfoNCE loss. In addition to hyperparameter-free deployment, we observed that the proposed method even yielded a performance gain in contrastive learning. Our detailed theoretical analysis discovers that the current practice of temperature scaling in InfoNCE loss causes serious problems in gradient descent, whereas our method provides desirable gradient properties. The proposed method was validated on five benchmarks on contrastive learning, yielding satisfactory results without temperature tuning.
Stochastic Subsampling With Average Pooling
Sep 25, 2024
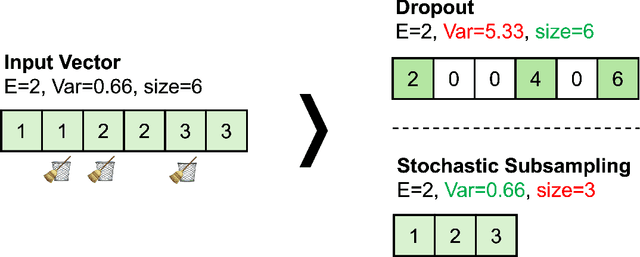
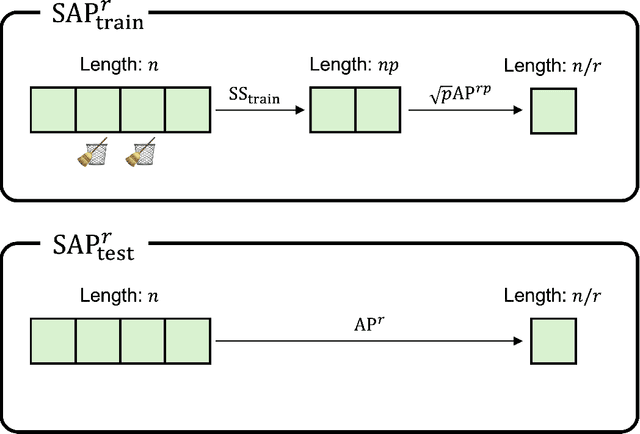

Regularization of deep neural networks has been an important issue to achieve higher generalization performance without overfitting problems. Although the popular method of Dropout provides a regularization effect, it causes inconsistent properties in the output, which may degrade the performance of deep neural networks. In this study, we propose a new module called stochastic average pooling, which incorporates Dropout-like stochasticity in pooling. We describe the properties of stochastic subsampling and average pooling and leverage them to design a module without any inconsistency problem. The stochastic average pooling achieves a regularization effect without any potential performance degradation due to the inconsistency issue and can easily be plugged into existing architectures of deep neural networks. Experiments demonstrate that replacing existing average pooling with stochastic average pooling yields consistent improvements across a variety of tasks, datasets, and models.
The Disappearance of Timestep Embedding in Modern Time-Dependent Neural Networks
May 23, 2024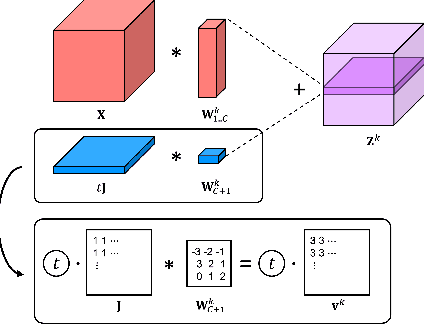
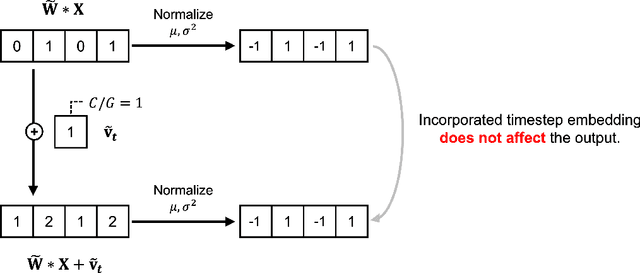
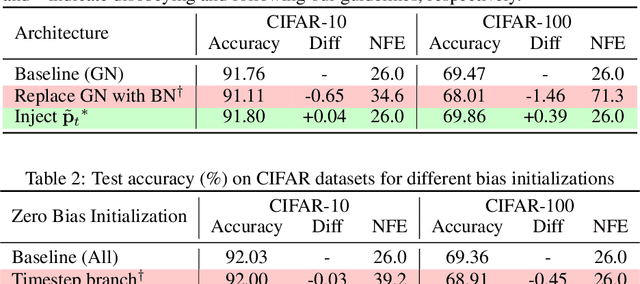
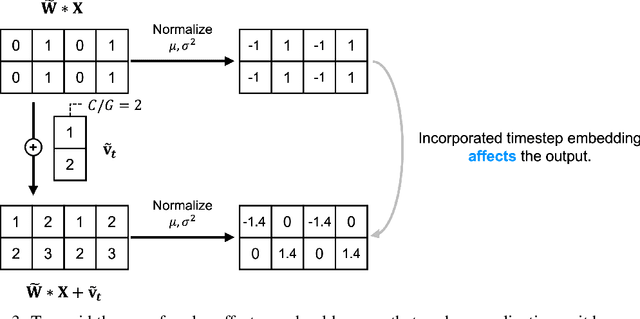
Dynamical systems are often time-varying, whose modeling requires a function that evolves with respect to time. Recent studies such as the neural ordinary differential equation proposed a time-dependent neural network, which provides a neural network varying with respect to time. However, we claim that the architectural choice to build a time-dependent neural network significantly affects its time-awareness but still lacks sufficient validation in its current states. In this study, we conduct an in-depth analysis of the architecture of modern time-dependent neural networks. Here, we report a vulnerability of vanishing timestep embedding, which disables the time-awareness of a time-dependent neural network. Furthermore, we find that this vulnerability can also be observed in diffusion models because they employ a similar architecture that incorporates timestep embedding to discriminate between different timesteps during a diffusion process. Our analysis provides a detailed description of this phenomenon as well as several solutions to address the root cause. Through experiments on neural ordinary differential equations and diffusion models, we observed that ensuring alive time-awareness via proposed solutions boosted their performance, which implies that their current implementations lack sufficient time-dependency.
Configuring Data Augmentations to Reduce Variance Shift in Positional Embedding of Vision Transformers
May 23, 2024



Vision transformers (ViTs) have demonstrated remarkable performance in a variety of vision tasks. Despite their promising capabilities, training a ViT requires a large amount of diverse data. Several studies empirically found that using rich data augmentations, such as Mixup, Cutmix, and random erasing, is critical to the successful training of ViTs. Now, the use of rich data augmentations has become a standard practice in the current state. However, we report a vulnerability to this practice: Certain data augmentations such as Mixup cause a variance shift in the positional embedding of ViT, which has been a hidden factor that degrades the performance of ViT during the test phase. We claim that achieving a stable effect from positional embedding requires a specific condition on the image, which is often broken for the current data augmentation methods. We provide a detailed analysis of this problem as well as the correct configuration for these data augmentations to remove the side effects of variance shift. Experiments showed that adopting our guidelines improves the performance of ViTs compared with the current configuration of data augmentations.
Scale Equalization for Multi-Level Feature Fusion
Feb 02, 2024Deep neural networks have exhibited remarkable performance in a variety of computer vision fields, especially in semantic segmentation tasks. Their success is often attributed to multi-level feature fusion, which enables them to understand both global and local information from an image. However, we found that multi-level features from parallel branches are on different scales. The scale disequilibrium is a universal and unwanted flaw that leads to detrimental gradient descent, thereby degrading performance in semantic segmentation. We discover that scale disequilibrium is caused by bilinear upsampling, which is supported by both theoretical and empirical evidence. Based on this observation, we propose injecting scale equalizers to achieve scale equilibrium across multi-level features after bilinear upsampling. Our proposed scale equalizers are easy to implement, applicable to any architecture, hyperparameter-free, implementable without requiring extra computational cost, and guarantee scale equilibrium for any dataset. Experiments showed that adopting scale equalizers consistently improved the mIoU index across various target datasets, including ADE20K, PASCAL VOC 2012, and Cityscapes, as well as various decoder choices, including UPerHead, PSPHead, ASPPHead, SepASPPHead, and FCNHead.