 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Use Dropout Correctly on Residual Networks with Batch Normalization
Paper and Code
Feb 13, 2023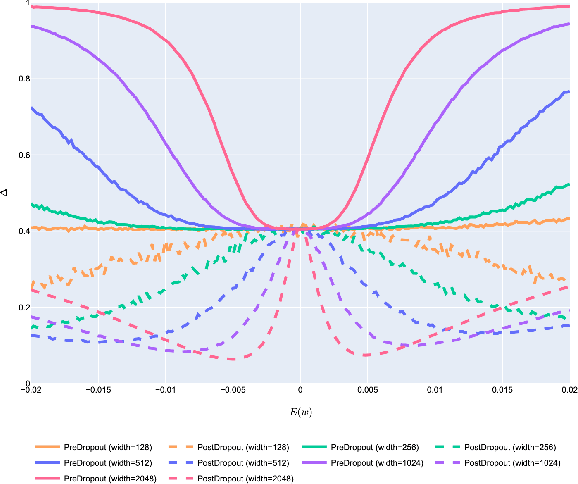
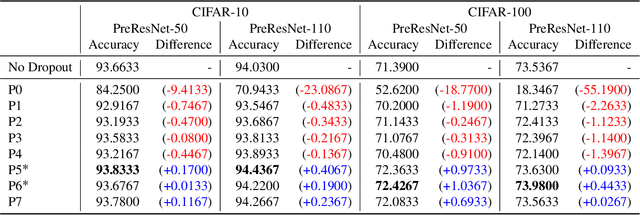
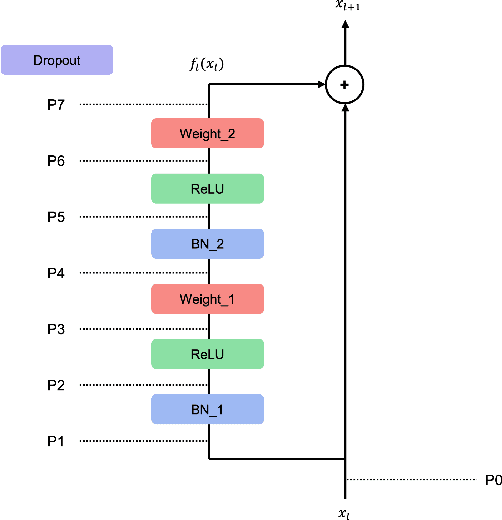

For the stable optimization of deep neural networks, regularization methods such as dropout and batch normalization have been used in various tasks. Nevertheless, the correct position to apply dropout has rarely been discussed, and different positions have been employed depending on the practitioners. In this study, we investigate the correct position to apply dropout. We demonstrate that for a residual network with batch normalization, applying dropout at certain positions increases the performance, whereas applying dropout at other positions decreases the performance. Based on theoretical analysis, we provide the following guideline for the correct position to apply dropout: apply one dropout after the last batch normalization but before the last weight layer in the residual branch. We provide detailed theoretical explanations to support this claim and demonstrate them through module tests. In addition, we investigate the correct position of dropout in the head that produces the final prediction. Although the current consensus is to apply dropout after global average pooling, we prove that applying dropout before global average pooling leads to a more stable output. The proposed guidelines are validated through experiments using different datasets and models.