 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolution-Aware Design of Atrous Rates for Semantic Segmentation Networks
Jul 26, 2023



DeepLab is a widely used deep neural network for semantic segmentation, whose success is attributed to its parallel architecture called atrous spatial pyramid pooling (ASPP). ASPP uses multiple atrous convolutions with different atrous rates to extract both local and global information. However, fixed values of atrous rates are used for the ASPP module, which restricts the size of its field of view. In principle, atrous rate should be a hyperparameter to change the field of view size according to the target task or dataset. However, the manipulation of atrous rate is not governed by any guidelines. This study proposes practical guidelines for obtaining an optimal atrous rate. First, an effective receptive field for semantic segmentation is introduced to analyze the inner behavior of segmentation networks. We observed that the use of ASPP module yielded a specific pattern in the effective receptive field, which was traced to reveal the module's underlying mechanism. Accordingly, we derive practical guidelines for obtaining the optimal atrous rate, which should be controlled based on the size of input image. Compared to other values, using the optimal atrous rate consistently improved the segmentation results across multiple datasets, including the STARE, CHASE_DB1, HRF, Cityscapes, and iSAID datasets.
Understanding Gaussian Attention Bias of Vision Transformers Using Effective Receptive Fields
May 08, 2023



Vision transformers (ViTs) that model an image as a sequence of partitioned patches have shown notable performance in diverse vision tasks. Because partitioning patches eliminates the image structure, to reflect the order of patches, ViTs utilize an explicit component called positional embedding. However, we claim that the use of positional embedding does not simply guarantee the order-awareness of ViT. To support this claim, we analyze the actual behavior of ViTs using an effective receptive field. We demonstrate that during training, ViT acquires an understanding of patch order from the positional embedding that is trained to be a specific pattern. Based on this observation, we propose explicitly adding a Gaussian attention bias that guides the positional embedding to have the corresponding pattern from the beginning of training. We evaluated the influence of Gaussian attention bias on the performance of ViTs in several image classification, object detection, and semantic segmentation experiments. The results showed that proposed method not only facilitates ViTs to understand images but also boosts their performance on various datasets, including ImageNet, COCO 2017, and ADE20K.
How to Use Dropout Correctly on Residual Networks with Batch Normalization
Feb 13, 2023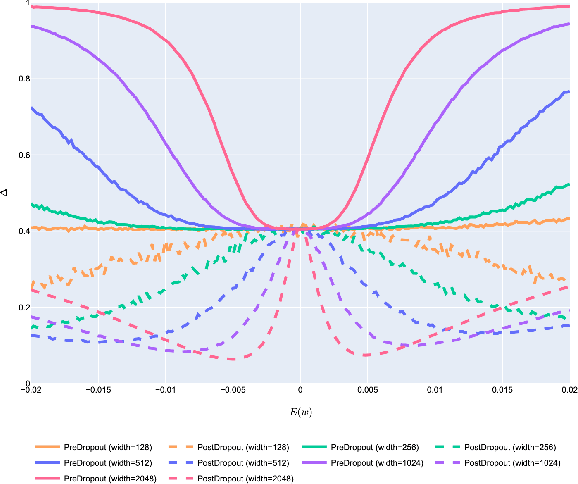
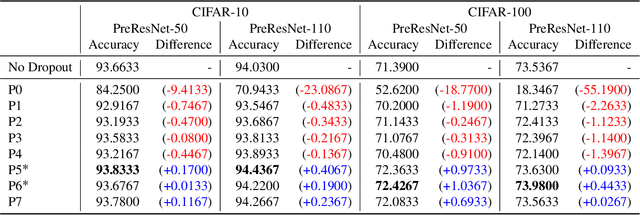
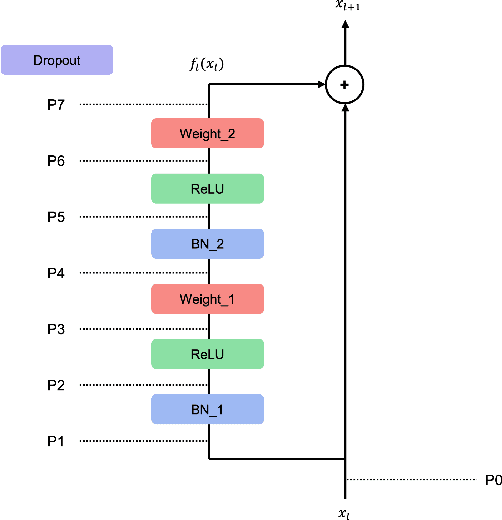

For the stable optimization of deep neural networks, regularization methods such as dropout and batch normalization have been used in various tasks. Nevertheless, the correct position to apply dropout has rarely been discussed, and different positions have been employed depending on the practitioners. In this study, we investigate the correct position to apply dropout. We demonstrate that for a residual network with batch normalization, applying dropout at certain positions increases the performance, whereas applying dropout at other positions decreases the performance. Based on theoretical analysis, we provide the following guideline for the correct position to apply dropout: apply one dropout after the last batch normalization but before the last weight layer in the residual branch. We provide detailed theoretical explanations to support this claim and demonstrate them through module tests. In addition, we investigate the correct position of dropout in the head that produces the final prediction. Although the current consensus is to apply dropout after global average pooling, we prove that applying dropout before global average pooling leads to a more stable output. The proposed guidelines are validated through experiments using different datasets and models.
On the Ideal Number of Groups for Isometric Gradient Propagation
Feb 07, 2023Recently, various normalization layers have been proposed to stabilize the training of deep neural networks. Among them, group normalization is a generalization of layer normalization and instance normalization by allowing a degree of freedom in the number of groups it uses. However, to determine the optimal number of groups, trial-and-error-based hyperparameter tuning is required, and such experiments are time-consuming. In this study, we discuss a reasonable method for setting the number of groups. First, we find that the number of groups influences the gradient behavior of the group normalization layer. Based on this observation, we derive the ideal number of groups, which calibrates the gradient scale to facilitate gradient descent optimization. Our proposed number of groups is theoretically grounded, architecture-aware, and can provide a proper value in a layer-wise manner for all layers. The proposed method exhibited improved performance over existing methods in numerous neural network architectures, tasks, and datasets.
Guidelines for the Regularization of Gammas in Batch Normalization for Deep Residual Networks
May 15, 2022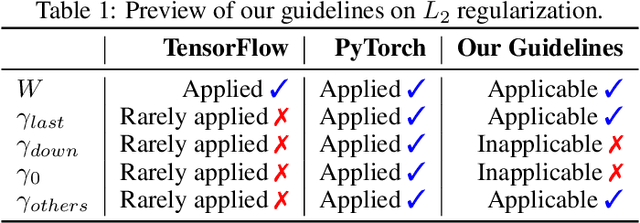
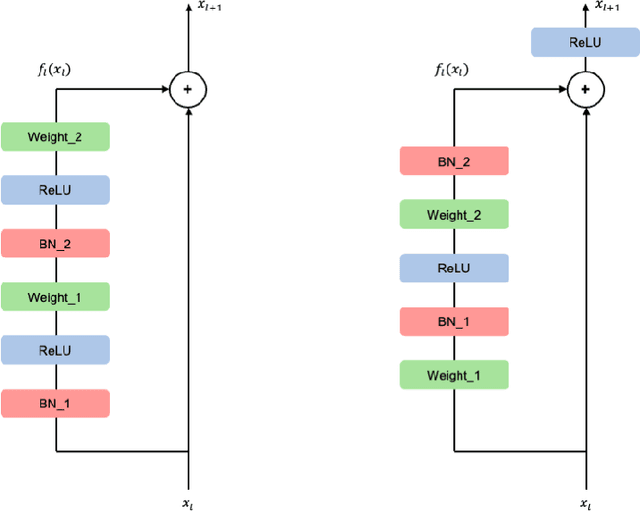
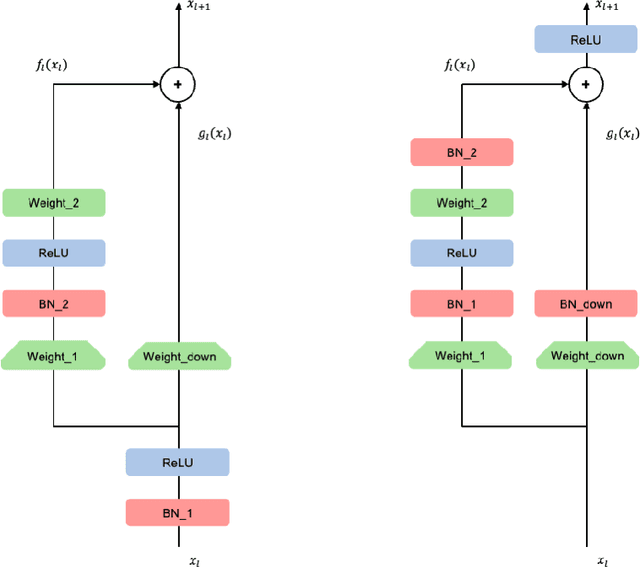
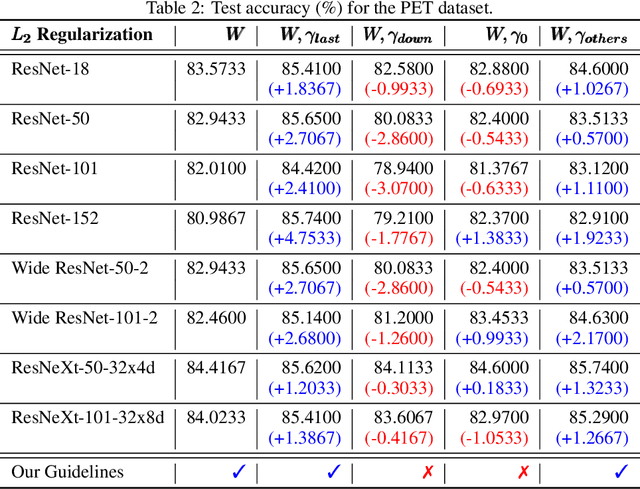
L2 regularization for weights in neural networks is widely used as a standard training trick. However, L2 regularization for gamma, a trainable parameter of batch normalization, remains an undiscussed mystery and is applied in different ways depending on the library and practitioner. In this paper, we study whether L2 regularization for gamma is valid. To explore this issue, we consider two approaches: 1) variance control to make the residual network behave like identity mapping and 2) stable optimization through the improvement of effective learning rate. Through two analyses, we specify the desirable and undesirable gamma to apply L2 regularization and propose four guidelines for managing them. In several experiments, we observed the increase and decrease in performance caused by applying L2 regularization to gamma of four categories, which is consistent with our four guidelines. Our proposed guidelines were validated through various tasks and architectures, including variants of residual networks and transformers.
Improved Robustness of Vision Transformer via PreLayerNorm in Patch Embedding
Nov 16, 2021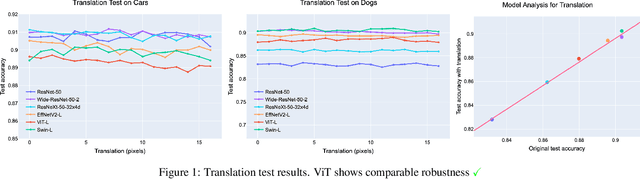
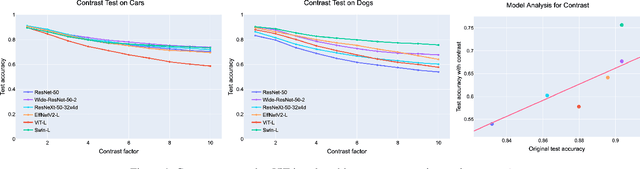
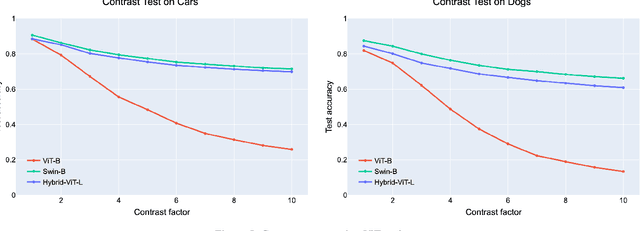
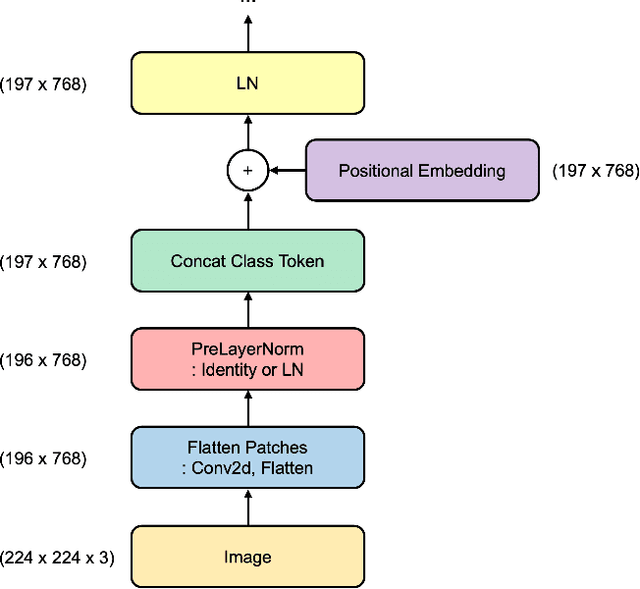
Vision transformers (ViTs) have recently demonstrated state-of-the-art performance in a variety of vision tasks, replacing convolutional neural networks (CNNs). Meanwhile, since ViT has a different architecture than CNN, it may behave differently. To investigate the reliability of ViT, this paper studies the behavior and robustness of ViT. We compared the robustness of CNN and ViT by assuming various image corruptions that may appear in practical vision tasks. We confirmed that for most image transformations, ViT showed robustness comparable to CNN or more improved. However, for contrast enhancement, severe performance degradations were consistently observed in ViT. From a detailed analysis, we identified a potential problem: positional embedding in ViT's patch embedding could work improperly when the color scale changes. Here we claim the use of PreLayerNorm, a modified patch embedding structure to ensure scale-invariant behavior of ViT. ViT with PreLayerNorm showed improved robustness in various corruptions including contrast-varying environments.
Dead Pixel Test Using Effective Receptive Field
Aug 31, 2021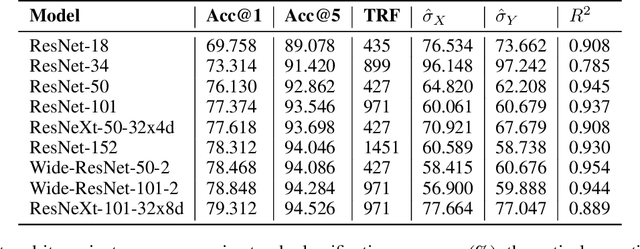

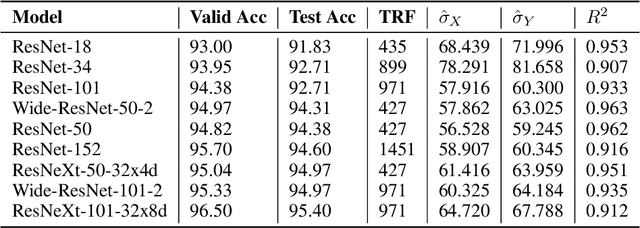
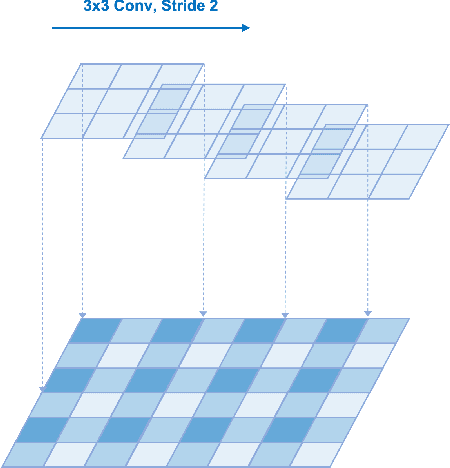
Deep neural networks have been used in various fields, but their internal behavior is not well known. In this study, we discuss two counterintuitive behaviors of convolutional neural networks (CNNs). First, we evaluated the size of the receptive field. Previous studies have attempted to increase or control the size of the receptive field. However, we observed that the size of the receptive field does not describe the classification accuracy. The size of the receptive field would be inappropriate for representing superiority in performance because it reflects only depth or kernel size and does not reflect other factors such as width or cardinality. Second, using the effective receptive field, we examined the pixels contributing to the output. Intuitively, each pixel is expected to equally contribute to the final output. However, we found that there exist pixels in a partially dead state with little contribution to the output. We reveal that the reason for this lies in the architecture of CNN and discuss solutions to reduce the phenomenon. Interestingly, for general classification tasks, the existence of dead pixels improves the training of CNNs. However, in a task that captures small perturbation, dead pixels degrade the performance. Therefore, the existence of these dead pixels should be understood and considered in practical applications of CNN.
Extending Class Activation Mapping Using Gaussian Receptive Field
Jan 15, 2020
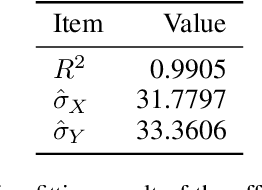
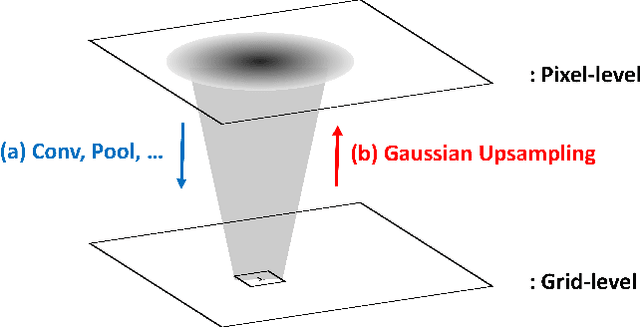

This paper addresses the visualization task of deep learning models. To improve Class Activation Mapping (CAM) based visualization method, we offer two options. First, we propose Gaussian upsampling, an improved upsampling method that can reflect the characteristics of deep learning models. Second, we identify and modify unnatural terms in the mathematical derivation of the existing CAM studies. Based on two options, we propose Extended-CAM, an advanced CAM-based visualization method, which exhibits improved theoretical properties. Experimental results show that Extended-CAM provides more accurate visualization than the existing methods.