 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectroscopy-Guided Discovery of Three-Dimensional Structures of Disordered Materials with Diffusion Models
Dec 09, 2023



The ability to rapidly develop materials with desired properties has a transformative impact on a broad range of emerging technologies. In this work, we introduce a new framework based on the diffusion model, a recent generative machine learning method to predict 3D structures of disordered materials from a target property. For demonstration, we apply the model to identify the atomic structures of amorphous carbons ($a$-C) as a representative material system from the target X-ray absorption near edge structure (XANES) spectra--a common experimental technique to probe atomic structures of materials. We show that conditional generation guided by XANES spectra reproduces key features of the target structures. Furthermore, we show that our model can steer the generative process to tailor atomic arrangements for a specific XANES spectrum. Finally, our generative model exhibits a remarkable scale-agnostic property, thereby enabling generation of realistic, large-scale structures through learning from a small-scale dataset (i.e., with small unit cells). Our work represents a significant stride in bridging the gap between materials characterization and atomic structure determination; in addition, it can be leveraged for materials discovery in exploring various material properties as targeted.
TUTORING: Instruction-Grounded Conversational Agent for Language Learners
Feb 24, 2023In this paper, we propose Tutoring bot, a generative chatbot trained on a large scale of tutor-student conversations for English-language learning. To mimic a human tutor's behavior in language education, the tutor bot leverages diverse educational instructions and grounds to each instruction as additional input context for the tutor response generation. As a single instruction generally involves multiple dialogue turns to give the student sufficient speaking practice, the tutor bot is required to monitor and capture when the current instruction should be kept or switched to the next instruction. For that, the tutor bot is learned to not only generate responses but also infer its teaching action and progress on the current conversation simultaneously by a multi-task learning scheme. Our Tutoring bot is deployed under a non-commercial use license at https://tutoringai.com.
Guidelines for the Regularization of Gammas in Batch Normalization for Deep Residual Networks
May 15, 2022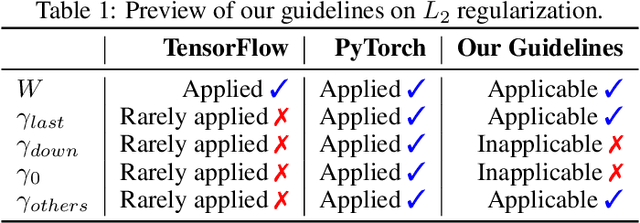
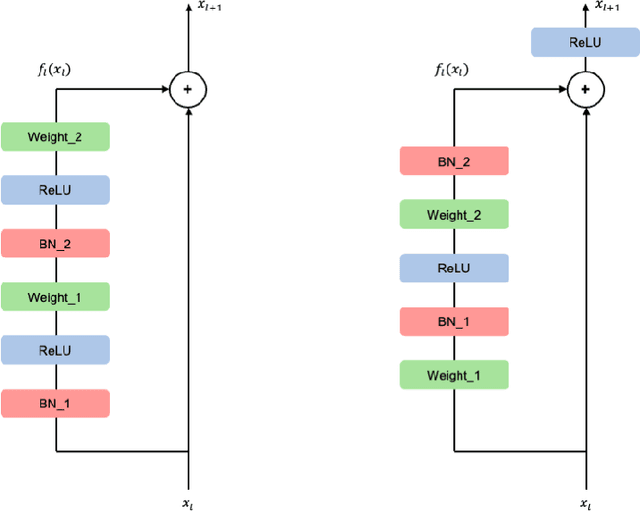
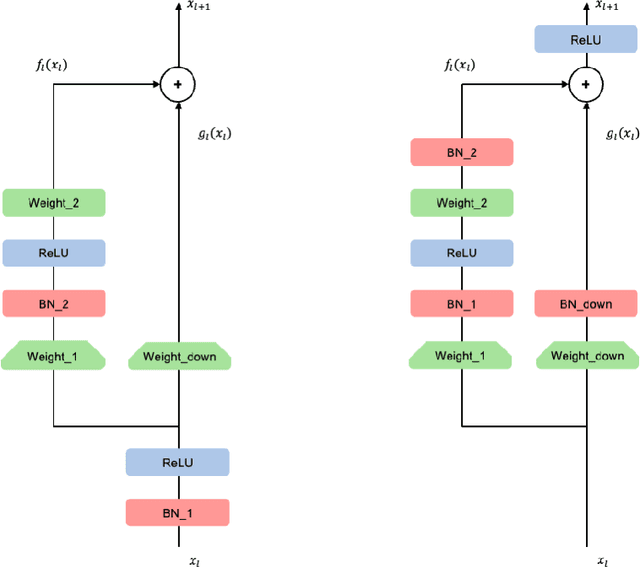
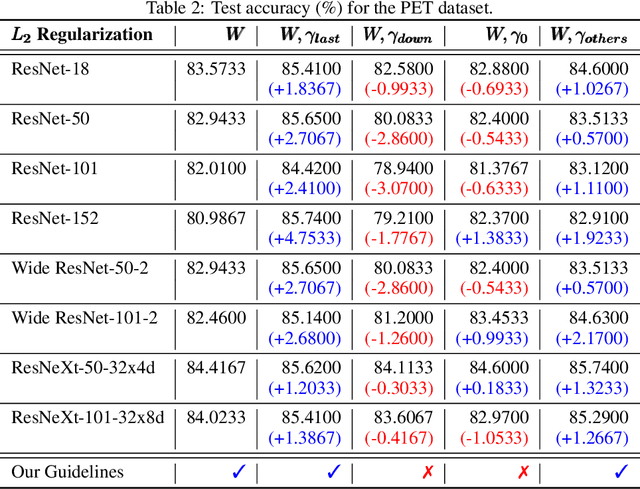
L2 regularization for weights in neural networks is widely used as a standard training trick. However, L2 regularization for gamma, a trainable parameter of batch normalization, remains an undiscussed mystery and is applied in different ways depending on the library and practitioner. In this paper, we study whether L2 regularization for gamma is valid. To explore this issue, we consider two approaches: 1) variance control to make the residual network behave like identity mapping and 2) stable optimization through the improvement of effective learning rate. Through two analyses, we specify the desirable and undesirable gamma to apply L2 regularization and propose four guidelines for managing them. In several experiments, we observed the increase and decrease in performance caused by applying L2 regularization to gamma of four categories, which is consistent with our four guidelines. Our proposed guidelines were validated through various tasks and architectures, including variants of residual networks and transformers.
Improved Robustness of Vision Transformer via PreLayerNorm in Patch Embedding
Nov 16, 2021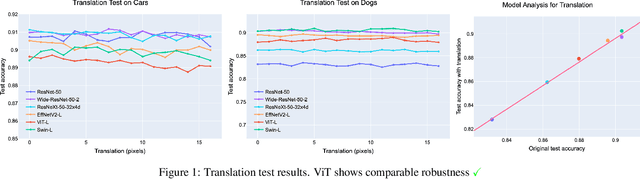
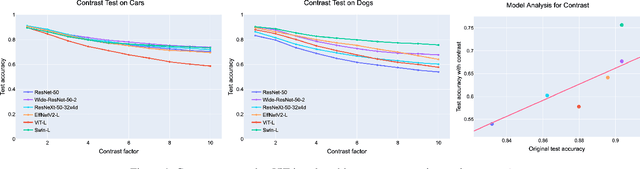
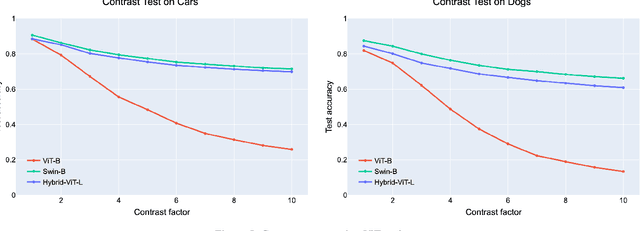
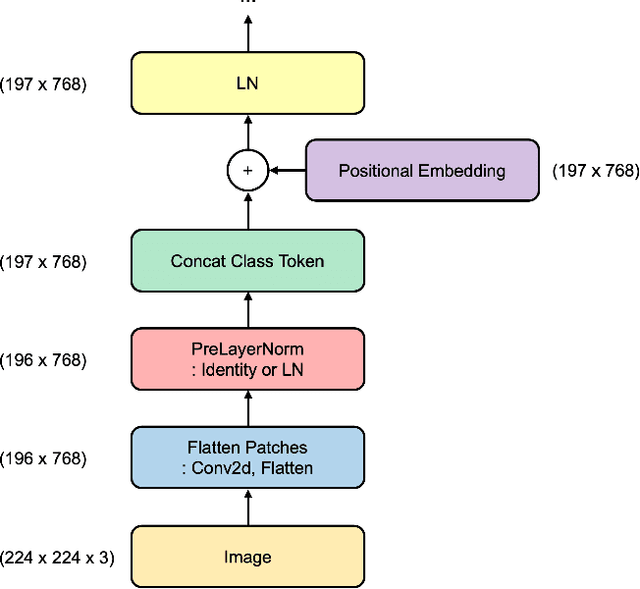
Vision transformers (ViTs) have recently demonstrated state-of-the-art performance in a variety of vision tasks, replacing convolutional neural networks (CNNs). Meanwhile, since ViT has a different architecture than CNN, it may behave differently. To investigate the reliability of ViT, this paper studies the behavior and robustness of ViT. We compared the robustness of CNN and ViT by assuming various image corruptions that may appear in practical vision tasks. We confirmed that for most image transformations, ViT showed robustness comparable to CNN or more improved. However, for contrast enhancement, severe performance degradations were consistently observed in ViT. From a detailed analysis, we identified a potential problem: positional embedding in ViT's patch embedding could work improperly when the color scale changes. Here we claim the use of PreLayerNorm, a modified patch embedding structure to ensure scale-invariant behavior of ViT. ViT with PreLayerNorm showed improved robustness in various corruptions including contrast-varying environments.
Dead Pixel Test Using Effective Receptive Field
Aug 31, 2021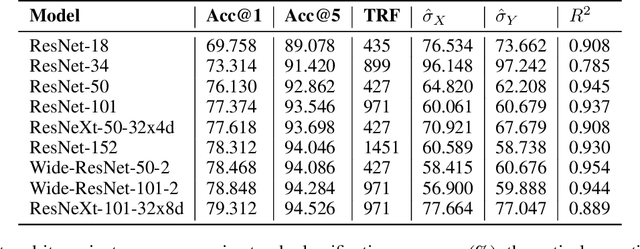

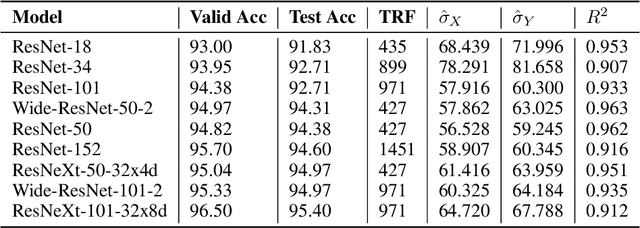
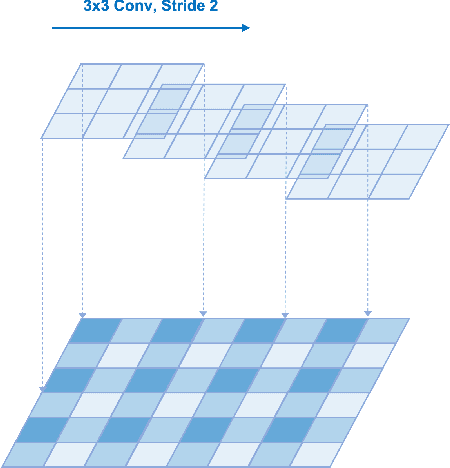
Deep neural networks have been used in various fields, but their internal behavior is not well known. In this study, we discuss two counterintuitive behaviors of convolutional neural networks (CNNs). First, we evaluated the size of the receptive field. Previous studies have attempted to increase or control the size of the receptive field. However, we observed that the size of the receptive field does not describe the classification accuracy. The size of the receptive field would be inappropriate for representing superiority in performance because it reflects only depth or kernel size and does not reflect other factors such as width or cardinality. Second, using the effective receptive field, we examined the pixels contributing to the output. Intuitively, each pixel is expected to equally contribute to the final output. However, we found that there exist pixels in a partially dead state with little contribution to the output. We reveal that the reason for this lies in the architecture of CNN and discuss solutions to reduce the phenomenon. Interestingly, for general classification tasks, the existence of dead pixels improves the training of CNNs. However, in a task that captures small perturbation, dead pixels degrade the performance. Therefore, the existence of these dead pixels should be understood and considered in practical applications of CNN.