 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImages & Recipes: Retrieval in the cooking context
May 02, 2018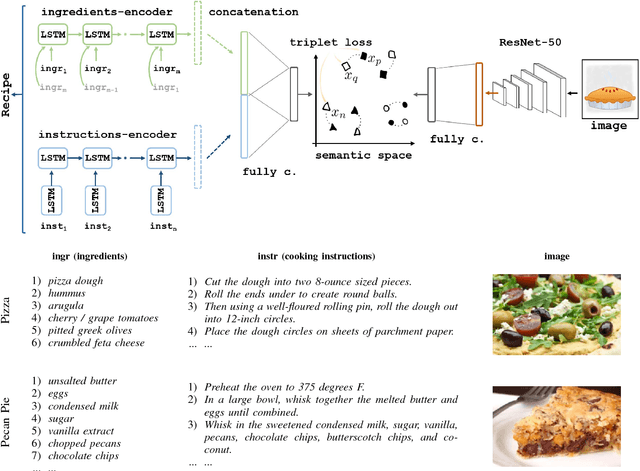



Recent advances in the machine learning community allowed different use cases to emerge, as its association to domains like cooking which created the computational cuisine. In this paper, we tackle the picture-recipe alignment problem, having as target application the large-scale retrieval task (finding a recipe given a picture, and vice versa). Our approach is validated on the Recipe1M dataset, composed of one million image-recipe pairs and additional class information, for which we achieve state-of-the-art results.
Cross-Modal Retrieval in the Cooking Context: Learning Semantic Text-Image Embeddings
Apr 30, 2018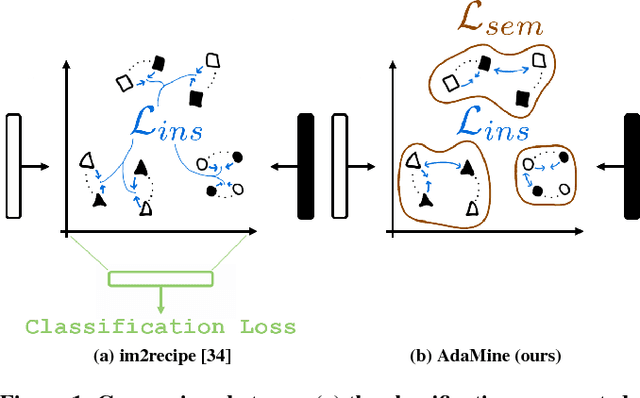

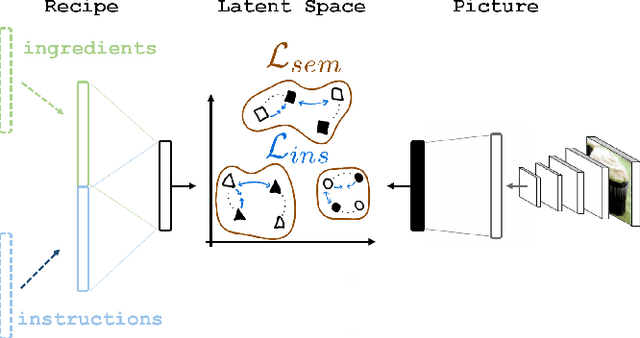
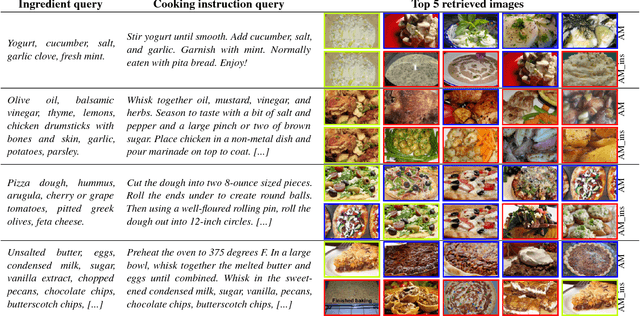
Designing powerful tools that support cooking activities has rapidly gained popularity due to the massive amounts of available data, as well as recent advances in machine learning that are capable of analyzing them. In this paper, we propose a cross-modal retrieval model aligning visual and textual data (like pictures of dishes and their recipes) in a shared representation space. We describe an effective learning scheme, capable of tackling large-scale problems, and validate it on the Recipe1M dataset containing nearly 1 million picture-recipe pairs. We show the effectiveness of our approach regarding previous state-of-the-art models and present qualitative results over computational cooking use cases.
Inspiring Computer Vision System Solutions
Jul 22, 2017

The "digital Michelangelo project" was a seminal computer vision project in the early 2000's that pushed the capabilities of acquisition systems and involved multiple people from diverse fields, many of whom are now leaders in industry and academia. Reviewing this project with modern eyes provides us with the opportunity to reflect on several issues, relevant now as then to the field of computer vision and research in general, that go beyond the technical aspects of the work. This article was written in the context of a reading group competition at the week-long International Computer Vision Summer School 2017 (ICVSS) on Sicily, Italy. To deepen the participants understanding of computer vision and to foster a sense of community, various reading groups were tasked to highlight important lessons which may be learned from provided literature, going beyond the contents of the paper. This report is the winning entry of this guided discourse (Fig. 1). The authors closely examined the origins, fruits and most importantly lessons about research in general which may be distilled from the "digital Michelangelo project". Discussions leading to this report were held within the group as well as with Hao Li, the group mentor.
Deep Neural Networks Under Stress
May 23, 2016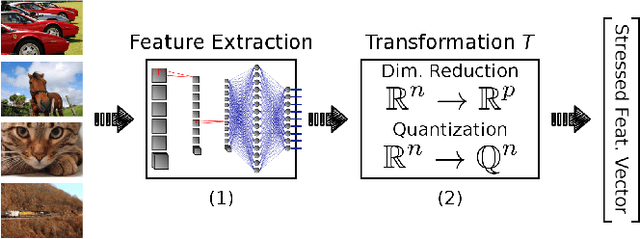
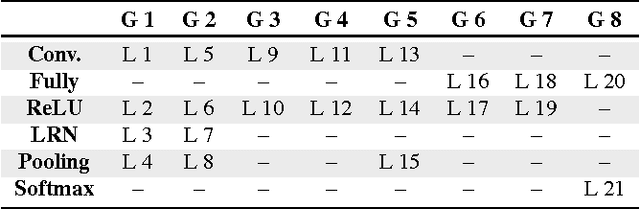
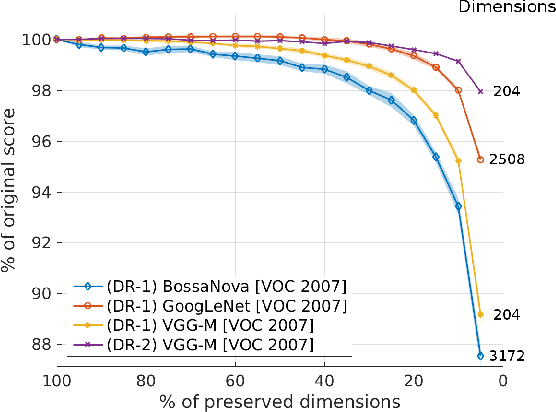
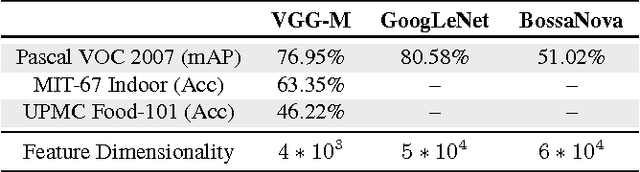
In recent years, deep architectures have been used for transfer learning with state-of-the-art performance in many datasets. The properties of their features remain, however, largely unstudied under the transfer perspective. In this work, we present an extensive analysis of the resiliency of feature vectors extracted from deep models, with special focus on the trade-off between performance and compression rate. By introducing perturbations to image descriptions extracted from a deep convolutional neural network, we change their precision and number of dimensions, measuring how it affects the final score. We show that deep features are more robust to these disturbances when compared to classical approaches, achieving a compression rate of 98.4%, while losing only 0.88% of their original score for Pascal VOC 2007.
Towards Automated Melanoma Screening: Proper Computer Vision & Reliable Results
May 06, 2016



In this paper we survey, analyze and criticize current art on automated melanoma screening, reimplementing a baseline technique, and proposing two novel ones. Melanoma, although highly curable when detected early, ends as one of the most dangerous types of cancer, due to delayed diagnosis and treatment. Its incidence is soaring, much faster than the number of trained professionals able to diagnose it. Automated screening appears as an alternative to make the most of those professionals, focusing their time on the patients at risk while safely discharging the other patients. However, the potential of automated melanoma diagnosis is currently unfulfilled, due to the emphasis of current literature on outdated computer vision models. Even more problematic is the irreproducibility of current art. We show how streamlined pipelines based upon current Computer Vision outperform conventional models - a model based on an advanced bags of words reaches an AUC of 84.6%, and a model based on deep neural networks reaches 89.3%, while the baseline (a classical bag of words) stays at 81.2%. We also initiate a dialog to improve reproducibility in our community