 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Anomaly Segmentation
Nov 25, 2019



Detecting out-of-distribution examples is important for safety-critical machine learning applications such as self-driving vehicles. However, existing research mainly focuses on small-scale images where the whole image is considered anomalous. We propose to segment only the anomalous regions within an image, and hence we introduce the Combined Anomalous Object Segmentation benchmark for the more realistic task of large-scale anomaly segmentation. Our benchmark combines two novel datasets for anomaly segmentation that incorporate both realism and anomaly diversity. Using both real images and those from a simulated driving environment, we ensure the background context and a wide variety of anomalous objects are naturally integrated, unlike before. Additionally, we improve out-of-distribution detectors on large-scale multi-class datasets and introduce detectors for the previously unexplored setting of multi-label out-of-distribution detection. These novel baselines along with our anomaly segmentation benchmark open the door to further research in large-scale out-of-distribution detection and segmentation.
Learning Rich Representations For Structured Visual Prediction Tasks
Aug 30, 2019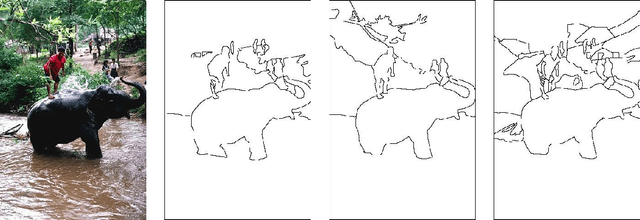

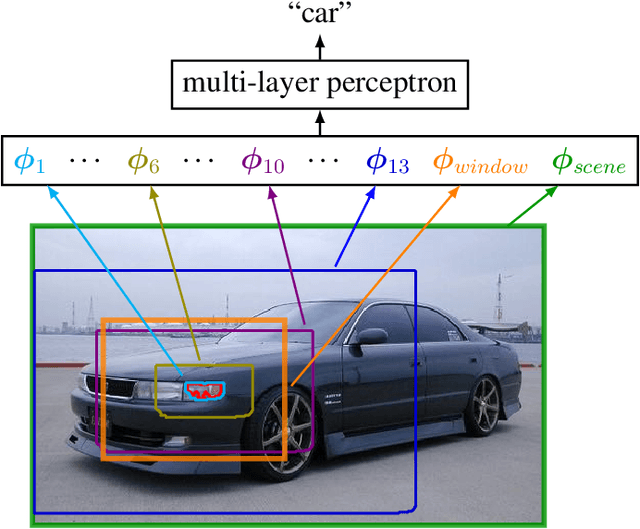
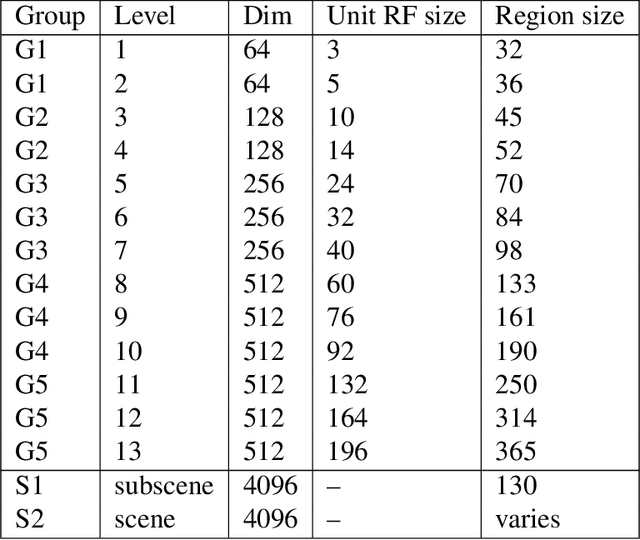
We describe an approach to learning rich representations for images, that enables simple and effective predictors in a range of vision tasks involving spatially structured maps. Our key idea is to map small image elements to feature representations extracted from a sequence of nested regions of increasing spatial extent. These regions are obtained by "zooming out" from the pixel/superpixel all the way to scene-level resolution, and hence we call these zoom-out features. Applied to semantic segmentation and other structured prediction tasks, our approach exploits statistical structure in the image and in the label space without setting up explicit structured prediction mechanisms, and thus avoids complex and expensive inference. Instead image elements are classified by a feedforward multilayer network with skip-layer connections spanning the zoom-out levels. When used in conjunction with modern neural architectures such as ResNet, DenseNet and NASNet (to which it is complementary) our approach achieves competitive accuracy on segmentation benchmarks. In addition, we propose an approach for learning category-level semantic segmentation purely from image-level classification tag. It exploits localization cues that emerge from training a modified zoom-out architecture tailored for classification tasks, to drive a weakly supervised process that automatically labels a sparse, diverse training set of points likely to belong to classes of interest. Finally, we introduce data-driven regularization functions for the supervised training of CNNs. Our innovation takes the form of a regularizer derived by learning an autoencoder over the set of annotations. This approach leverages an improved representation of label space to inform extraction of features from images
DIODE: A Dense Indoor and Outdoor DEpth Dataset
Aug 29, 2019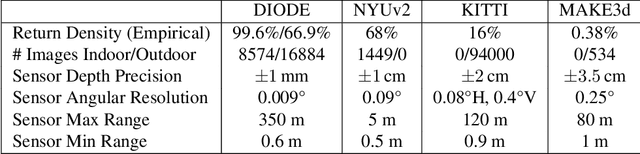
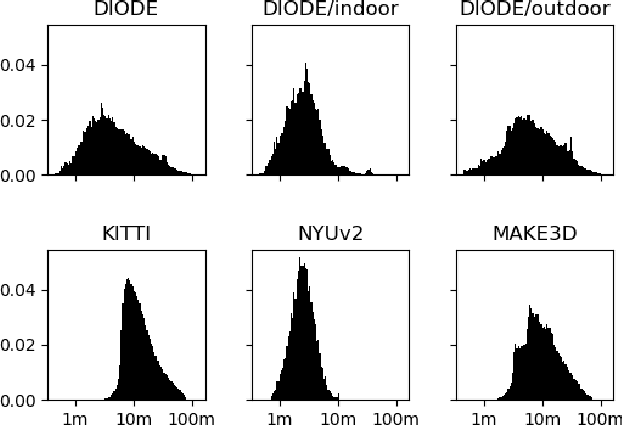
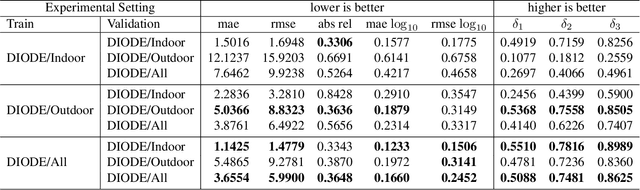
We introduce DIODE, a dataset that contains thousands of diverse high resolution color images with accurate, dense, long-range depth measurements. DIODE (Dense Indoor/Outdoor DEpth) is the first public dataset to include RGBD images of indoor and outdoor scenes obtained with one sensor suite. This is in contrast to existing datasets that focus on just one domain/scene type and employ different sensors, making generalization across domains difficult. The dataset is available for download at http://diode-dataset.org
Regularizing Deep Networks by Modeling and Predicting Label Structure
Apr 05, 2018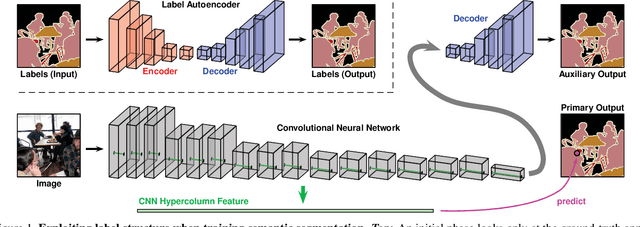
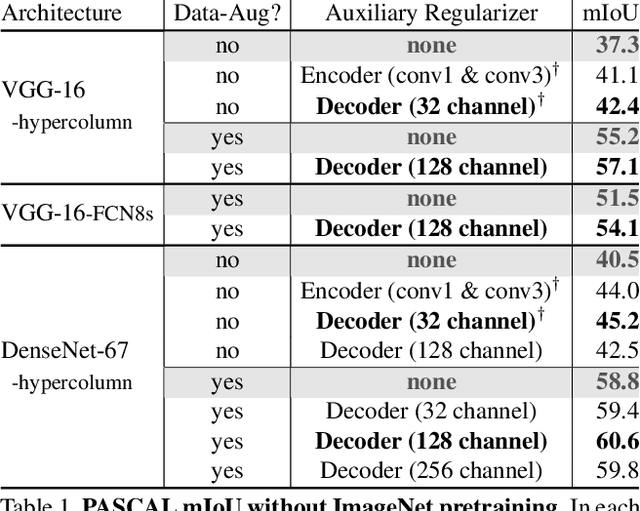
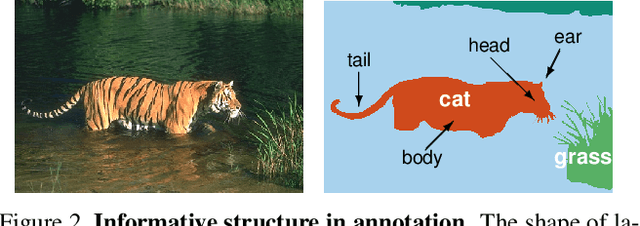
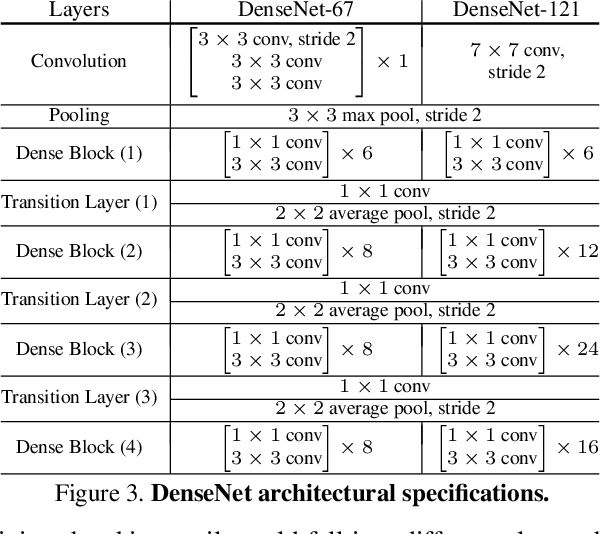
We construct custom regularization functions for use in supervised training of deep neural networks. Our technique is applicable when the ground-truth labels themselves exhibit internal structure; we derive a regularizer by learning an autoencoder over the set of annotations. Training thereby becomes a two-phase procedure. The first phase models labels with an autoencoder. The second phase trains the actual network of interest by attaching an auxiliary branch that must predict output via a hidden layer of the autoencoder. After training, we discard this auxiliary branch. We experiment in the context of semantic segmentation, demonstrating this regularization strategy leads to consistent accuracy boosts over baselines, both when training from scratch, or in combination with ImageNet pretraining. Gains are also consistent over different choices of convolutional network architecture. As our regularizer is discarded after training, our method has zero cost at test time; the performance improvements are essentially free. We are simply able to learn better network weights by building an abstract model of the label space, and then training the network to understand this abstraction alongside the original task.
Diverse Sampling for Self-Supervised Learning of Semantic Segmentation
Dec 06, 2016

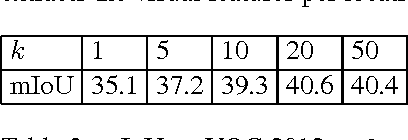

We propose an approach for learning category-level semantic segmentation purely from image-level classification tags indicating presence of categories. It exploits localization cues that emerge from training classification-tasked convolutional networks, to drive a "self-supervision" process that automatically labels a sparse, diverse training set of points likely to belong to classes of interest. Our approach has almost no hyperparameters, is modular, and allows for very fast training of segmentation in less than 3 minutes. It obtains competitive results on the VOC 2012 segmentation benchmark. More, significantly the modularity and fast training of our framework allows new classes to efficiently added for inference.
Feedforward semantic segmentation with zoom-out features
Dec 02, 2014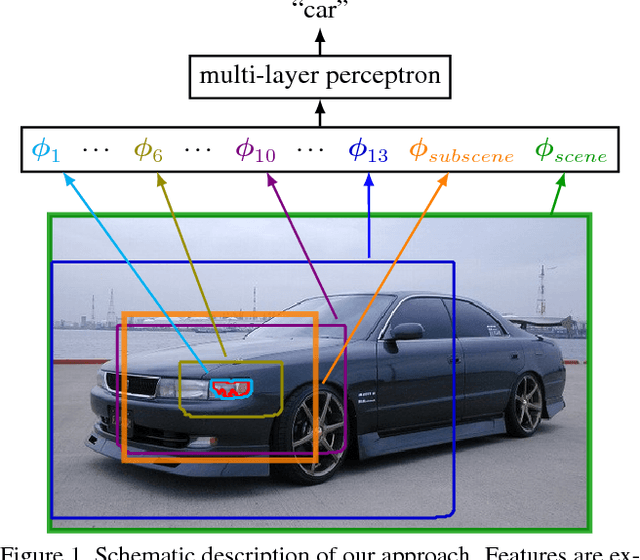
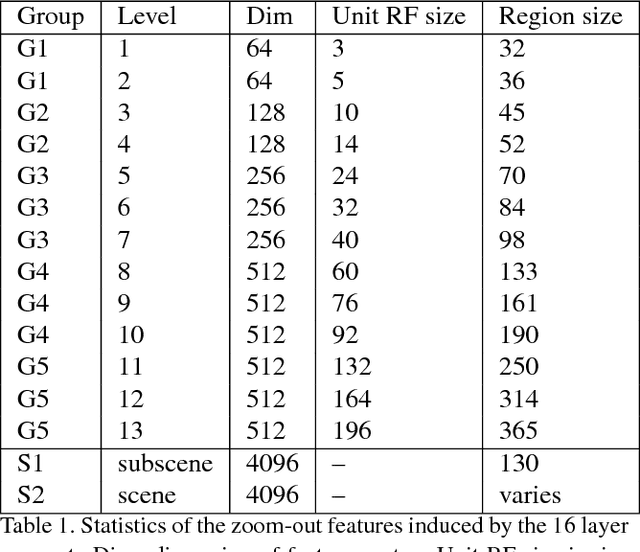


We introduce a purely feed-forward architecture for semantic segmentation. We map small image elements (superpixels) to rich feature representations extracted from a sequence of nested regions of increasing extent. These regions are obtained by "zooming out" from the superpixel all the way to scene-level resolution. This approach exploits statistical structure in the image and in the label space without setting up explicit structured prediction mechanisms, and thus avoids complex and expensive inference. Instead superpixels are classified by a feedforward multilayer network. Our architecture achieves new state of the art performance in semantic segmentation, obtaining 64.4% average accuracy on the PASCAL VOC 2012 test set.