 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-driven text descriptions for images
Aug 28, 2021

A big part of achieving Artificial General Intelligence(AGI) is to build a machine that can see and listen like humans. Much work has focused on designing models for image classification, video classification, object detection, pose estimation, speech recognition, etc., and has achieved significant progress in recent years thanks to deep learning. However, understanding the world is not enough. An AI agent also needs to know how to talk, especially how to communicate with a human. While perception (vision, for example) is more common across animal species, the use of complicated language is unique to humans and is one of the most important aspects of intelligence. In this thesis, we focus on generating textual output given visual input. In Chapter 3, we focus on generating the referring expression, a text description for an object in the image so that a receiver can infer which object is being described. We use a comprehension machine to directly guide the generated referring expressions to be more discriminative. In Chapter 4, we introduce a method that encourages discriminability in image caption generation. We show that more discriminative captioning models generate more descriptive captions. In Chapter 5, we study how training objectives and sampling methods affect the models' ability to generate diverse captions. We find that a popular captioning training strategy will be detrimental to the diversity of generated captions. In Chapter 6, we propose a model that can control the length of generated captions. By changing the desired length, one can influence the style and descriptiveness of the captions. Finally, in Chapter 7, we rank/generate informative image tags according to their information utility. The proposed method better matches what humans think are the most important tags for the images.
Controlling Length in Image Captioning
May 29, 2020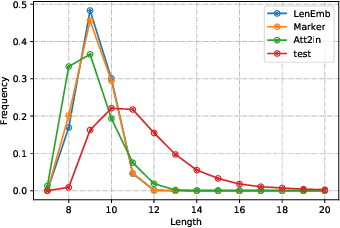

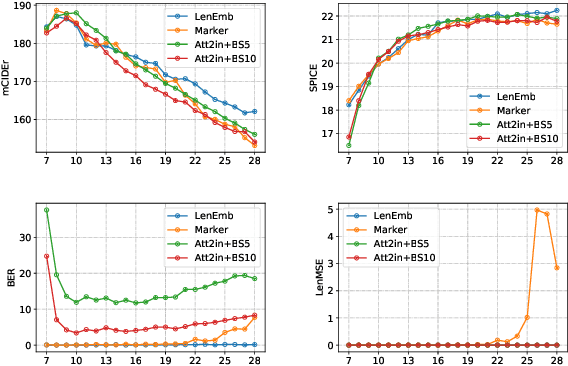

We develop and evaluate captioning models that allow control of caption length. Our models can leverage this control to generate captions of different style and descriptiveness.
Detection and Description of Change in Visual Streams
Apr 09, 2020
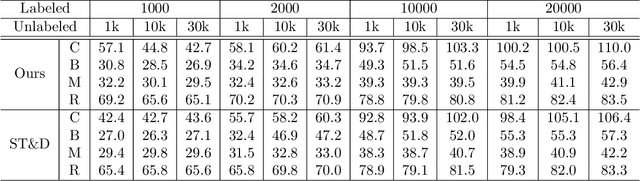

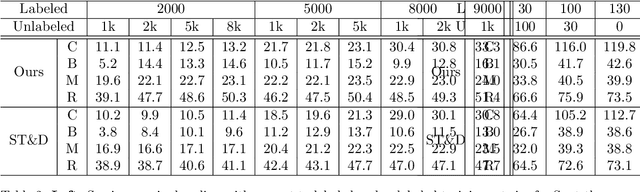
This paper presents a framework for the analysis of changes in visual streams: ordered sequences of images, possibly separated by significant time gaps. We propose a new approach to incorporating unlabeled data into training to generate natural language descriptions of change. We also develop a framework for estimating the time of change in visual stream. We use learned representations for change evidence and consistency of perceived change, and combine these in a regularized graph cut based change detector. Experimental evaluation on visual stream datasets, which we release as part of our contribution, shows that representation learning driven by natural language descriptions significantly improves change detection accuracy, compared to methods that do not rely on language.
Pixel Consensus Voting for Panoptic Segmentation
Apr 04, 2020The core of our approach, Pixel Consensus Voting, is a framework for instance segmentation based on the Generalized Hough transform. Pixels cast discretized, probabilistic votes for the likely regions that contain instance centroids. At the detected peaks that emerge in the voting heatmap, backprojection is applied to collect pixels and produce instance masks. Unlike a sliding window detector that densely enumerates object proposals, our method detects instances as a result of the consensus among pixel-wise votes. We implement vote aggregation and backprojection using native operators of a convolutional neural network. The discretization of centroid voting reduces the training of instance segmentation to pixel labeling, analogous and complementary to FCN-style semantic segmentation, leading to an efficient and unified architecture that jointly models things and stuff. We demonstrate the effectiveness of our pipeline on COCO and Cityscapes Panoptic Segmentation and obtain competitive results. Code will be open-sourced.
A Better Variant of Self-Critical Sequence Training
Mar 22, 2020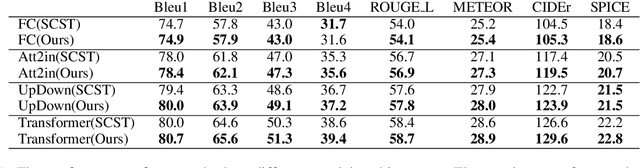


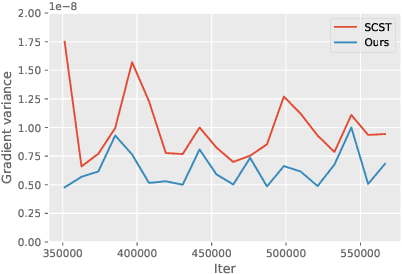
In this work, we present a simple yet better variant of Self-Critical Sequence Training. We make a simple change in the choice of baseline function in REINFORCE algorithm. The new baseline can bring better performance with no extra cost, compared to the greedy decoding baseline.
Analysis of diversity-accuracy tradeoff in image captioning
Feb 27, 2020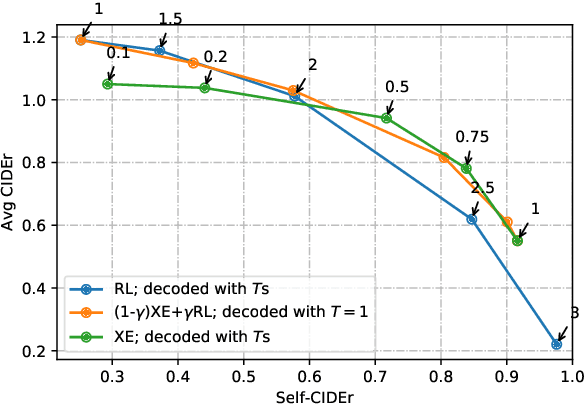

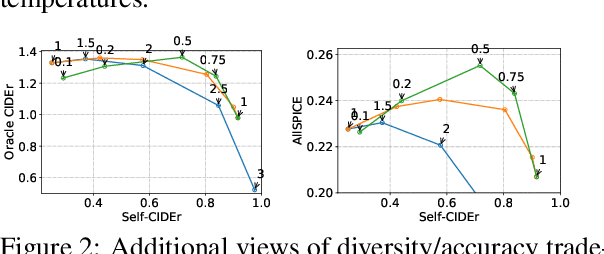

We investigate the effect of different model architectures, training objectives, hyperparameter settings and decoding procedures on the diversity of automatically generated image captions. Our results show that 1) simple decoding by naive sampling, coupled with low temperature is a competitive and fast method to produce diverse and accurate caption sets; 2) training with CIDEr-based reward using Reinforcement learning harms the diversity properties of the resulting generator, which cannot be mitigated by manipulating decoding parameters. In addition, we propose a new metric AllSPICE for evaluating both accuracy and diversity of a set of captions by a single value.
DIODE: A Dense Indoor and Outdoor DEpth Dataset
Aug 29, 2019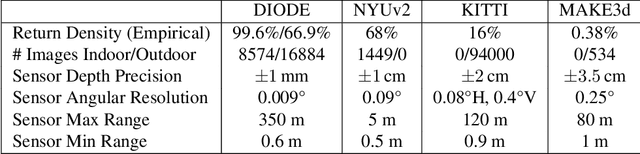
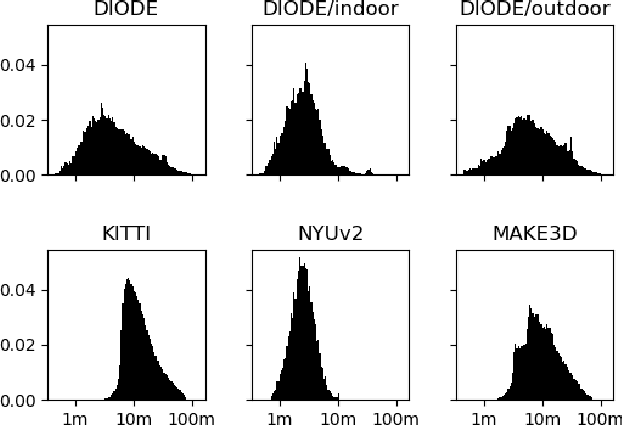
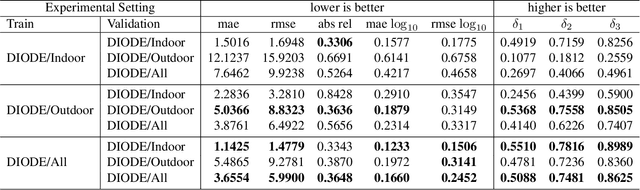
We introduce DIODE, a dataset that contains thousands of diverse high resolution color images with accurate, dense, long-range depth measurements. DIODE (Dense Indoor/Outdoor DEpth) is the first public dataset to include RGBD images of indoor and outdoor scenes obtained with one sensor suite. This is in contrast to existing datasets that focus on just one domain/scene type and employ different sensors, making generalization across domains difficult. The dataset is available for download at http://diode-dataset.org
Context-Aware Zero-Shot Recognition
Apr 24, 2019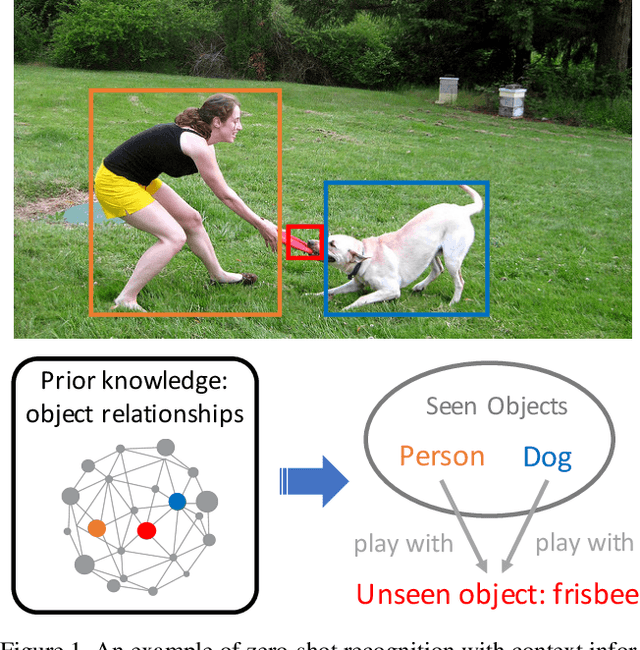
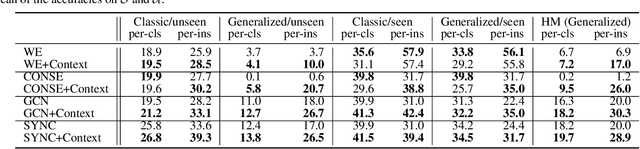
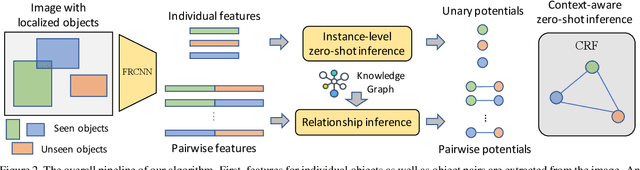
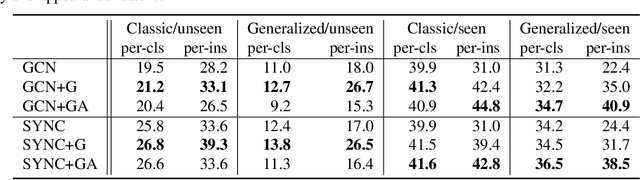
We present a novel problem setting in zero-shot learning, zero-shot object recognition and detection in the context. Contrary to the traditional zero-shot learning methods, which simply infers unseen categories by transferring knowledge from the objects belonging to semantically similar seen categories, we aim to understand the identity of the novel objects in an image surrounded by the known objects using the inter-object relation prior. Specifically, we leverage the visual context and the geometric relationships between all pairs of objects in a single image, and capture the information useful to infer unseen categories. We integrate our context-aware zero-shot learning framework into the traditional zero-shot learning techniques seamlessly using a Conditional Random Field (CRF). The proposed algorithm is evaluated on both zero-shot region classification and zero-shot detection tasks. The results on Visual Genome (VG) dataset show that our model significantly boosts performance with the additional visual context compared to traditional methods.
Discriminability objective for training descriptive captions
Jun 08, 2018

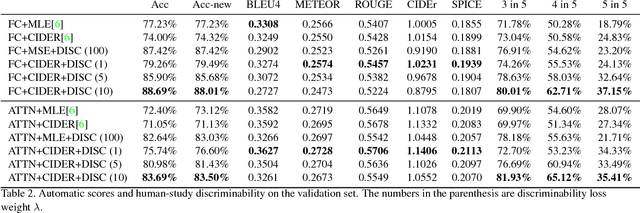

One property that remains lacking in image captions generated by contemporary methods is discriminability: being able to tell two images apart given the caption for one of them. We propose a way to improve this aspect of caption generation. By incorporating into the captioning training objective a loss component directly related to ability (by a machine) to disambiguate image/caption matches, we obtain systems that produce much more discriminative caption, according to human evaluation. Remarkably, our approach leads to improvement in other aspects of generated captions, reflected by a battery of standard scores such as BLEU, SPICE etc. Our approach is modular and can be applied to a variety of model/loss combinations commonly proposed for image captioning.
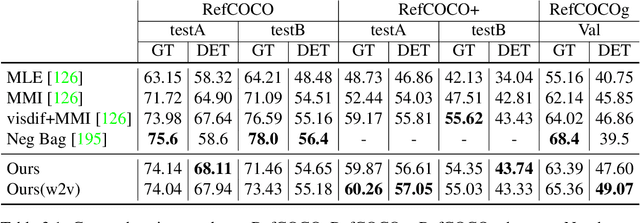
Comprehension-guided referring expressions
Jan 12, 2017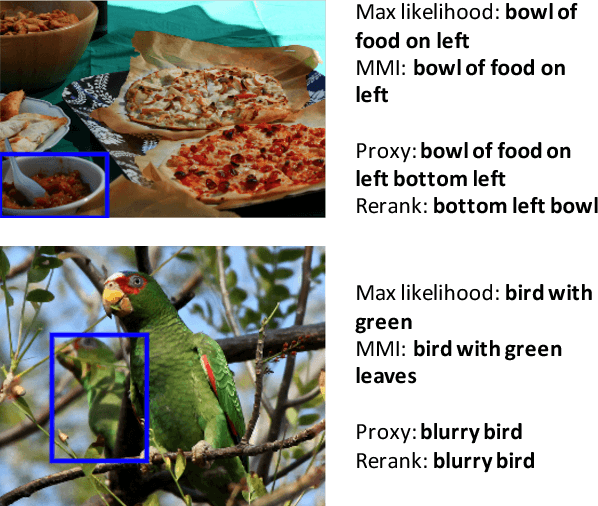
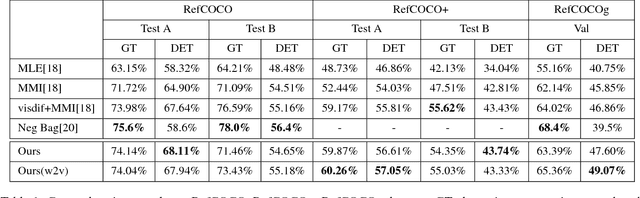
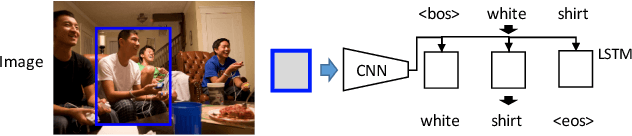
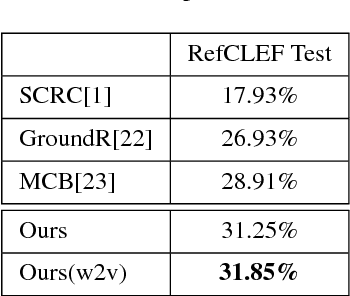
We consider generation and comprehension of natural language referring expression for objects in an image. Unlike generic "image captioning" which lacks natural standard evaluation criteria, quality of a referring expression may be measured by the receiver's ability to correctly infer which object is being described. Following this intuition, we propose two approaches to utilize models trained for comprehension task to generate better expressions. First, we use a comprehension module trained on human-generated expressions, as a "critic" of referring expression generator. The comprehension module serves as a differentiable proxy of human evaluation, providing training signal to the generation module. Second, we use the comprehension module in a generate-and-rerank pipeline, which chooses from candidate expressions generated by a model according to their performance on the comprehension task. We show that both approaches lead to improved referring expression generation on multiple benchmark datasets.