 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-driven text descriptions for images
Paper and Code


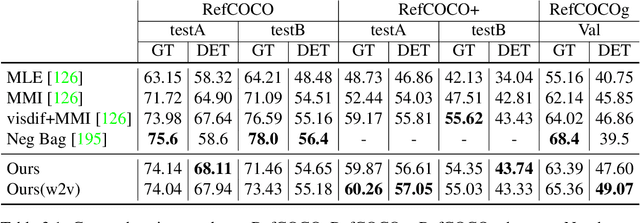
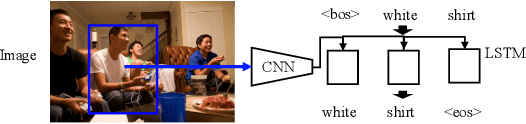
A big part of achieving Artificial General Intelligence(AGI) is to build a machine that can see and listen like humans. Much work has focused on designing models for image classification, video classification, object detection, pose estimation, speech recognition, etc., and has achieved significant progress in recent years thanks to deep learning. However, understanding the world is not enough. An AI agent also needs to know how to talk, especially how to communicate with a human. While perception (vision, for example) is more common across animal species, the use of complicated language is unique to humans and is one of the most important aspects of intelligence. In this thesis, we focus on generating textual output given visual input. In Chapter 3, we focus on generating the referring expression, a text description for an object in the image so that a receiver can infer which object is being described. We use a comprehension machine to directly guide the generated referring expressions to be more discriminative. In Chapter 4, we introduce a method that encourages discriminability in image caption generation. We show that more discriminative captioning models generate more descriptive captions. In Chapter 5, we study how training objectives and sampling methods affect the models' ability to generate diverse captions. We find that a popular captioning training strategy will be detrimental to the diversity of generated captions. In Chapter 6, we propose a model that can control the length of generated captions. By changing the desired length, one can influence the style and descriptiveness of the captions. Finally, in Chapter 7, we rank/generate informative image tags according to their information utility. The proposed method better matches what humans think are the most important tags for the images.