 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehension-guided referring expressions
Paper and Code
Jan 12, 2017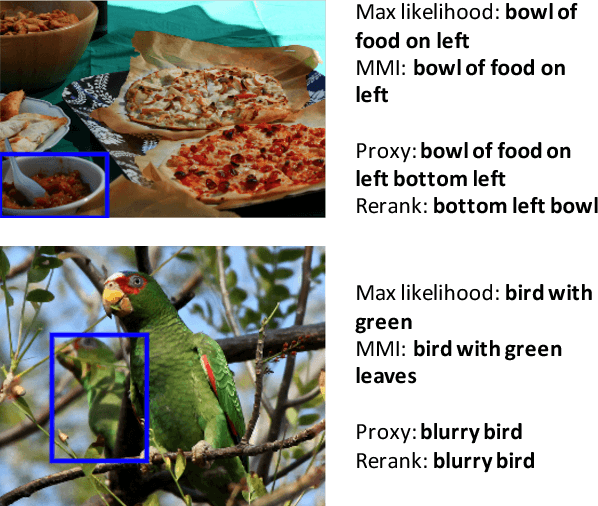
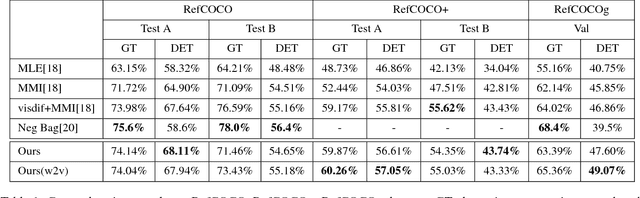
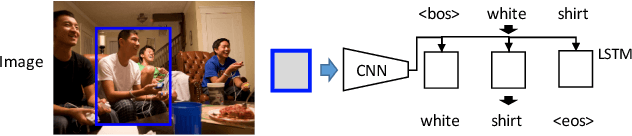
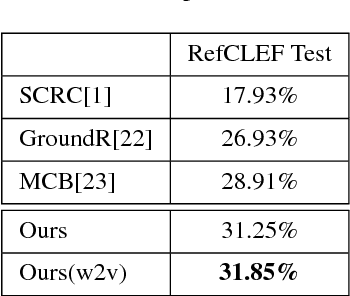
We consider generation and comprehension of natural language referring expression for objects in an image. Unlike generic "image captioning" which lacks natural standard evaluation criteria, quality of a referring expression may be measured by the receiver's ability to correctly infer which object is being described. Following this intuition, we propose two approaches to utilize models trained for comprehension task to generate better expressions. First, we use a comprehension module trained on human-generated expressions, as a "critic" of referring expression generator. The comprehension module serves as a differentiable proxy of human evaluation, providing training signal to the generation module. Second, we use the comprehension module in a generate-and-rerank pipeline, which chooses from candidate expressions generated by a model according to their performance on the comprehension task. We show that both approaches lead to improved referring expression generation on multiple benchmark datasets.