Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of diversity-accuracy tradeoff in image captioning
Paper and Code
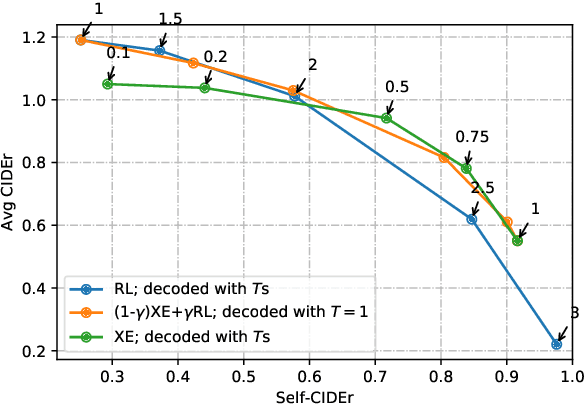

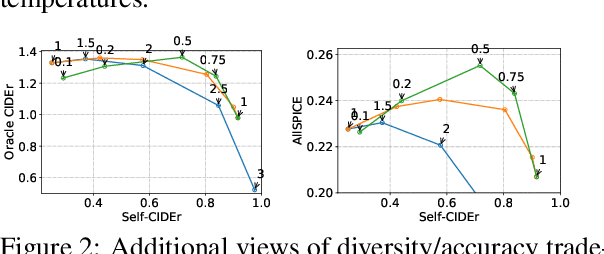

We investigate the effect of different model architectures, training objectives, hyperparameter settings and decoding procedures on the diversity of automatically generated image captions. Our results show that 1) simple decoding by naive sampling, coupled with low temperature is a competitive and fast method to produce diverse and accurate caption sets; 2) training with CIDEr-based reward using Reinforcement learning harms the diversity properties of the resulting generator, which cannot be mitigated by manipulating decoding parameters. In addition, we propose a new metric AllSPICE for evaluating both accuracy and diversity of a set of captions by a single value.
View paper on