 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic tactile sensing for mobile robot wheels
Feb 28, 2024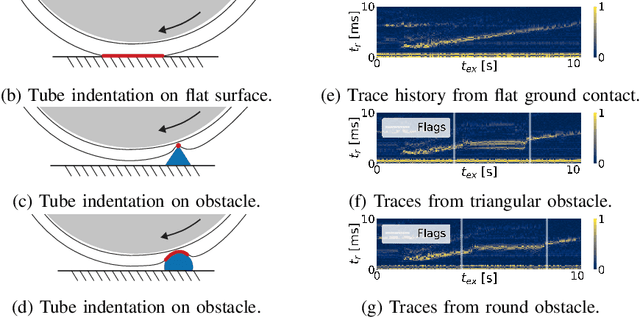



Tactile sensing in mobile robots remains under-explored, mainly due to challenges related to sensor integration and the complexities of distributed sensing. In this work, we present a tactile sensing architecture for mobile robots based on wheel-mounted acoustic waveguides. Our sensor architecture enables tactile sensing along the entire circumference of a wheel with a single active component: an off-the-shelf acoustic rangefinder. We present findings showing that our sensor, mounted on the wheel of a mobile robot, is capable of discriminating between different terrains, detecting and classifying obstacles with different geometries, and performing collision detection via contact localization. We also present a comparison between our sensor and sensors traditionally used in mobile robots, and point to the potential for sensor fusion approaches that leverage the unique capabilities of our tactile sensing architecture. Our findings demonstrate that autonomous mobile robots can further leverage our sensor architecture for diverse mapping tasks requiring knowledge of terrain material, surface topology, and underlying structure.
On Reward Structures of Markov Decision Processes
Aug 31, 2023A Markov decision process can be parameterized by a transition kernel and a reward function. Both play essential roles in the study of reinforcement learning as evidenced by their presence in the Bellman equations. In our inquiry of various kinds of "costs" associated with reinforcement learning inspired by the demands in robotic applications, rewards are central to understanding the structure of a Markov decision process and reward-centric notions can elucidate important concepts in reinforcement learning. Specifically, we study the sample complexity of policy evaluation and develop a novel estimator with an instance-specific error bound of $\tilde{O}(\sqrt{\frac{\tau_s}{n}})$ for estimating a single state value. Under the online regret minimization setting, we refine the transition-based MDP constant, diameter, into a reward-based constant, maximum expected hitting cost, and with it, provide a theoretical explanation for how a well-known technique, potential-based reward shaping, could accelerate learning with expert knowledge. In an attempt to study safe reinforcement learning, we model hazardous environments with irrecoverability and proposed a quantitative notion of safe learning via reset efficiency. In this setting, we modify a classic algorithm to account for resets achieving promising preliminary numerical results. Lastly, for MDPs with multiple reward functions, we develop a planning algorithm that computationally efficiently finds Pareto-optimal stochastic policies.
Word2vec Conjecture and A Limitative Result
Oct 24, 2020Being inspired by the success of \texttt{word2vec} \citep{mikolov2013distributed} in capturing analogies, we study the conjecture that analogical relations can be represented by vector spaces. Unlike many previous works that focus on the distributional semantic aspect of \texttt{word2vec}, we study the purely \emph{representational} question: can \emph{all} semantic word-word relations be represented by differences (or directions) of vectors? We call this the word2vec conjecture and point out some of its desirable implications. However, we will exhibit a class of relations that cannot be represented in this way, thus falsifying the conjecture and establishing a limitative result for the representability of semantic relations by vector spaces over fields of characteristic 0, e.g., real or complex numbers.
Loop estimator for discounted values in Markov reward processes
Feb 15, 2020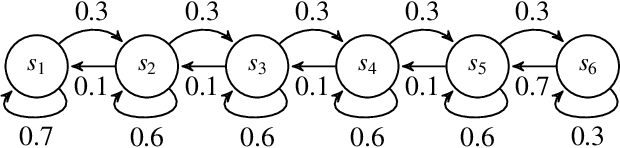
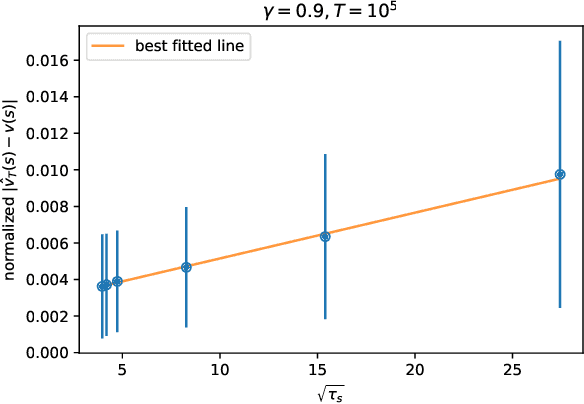
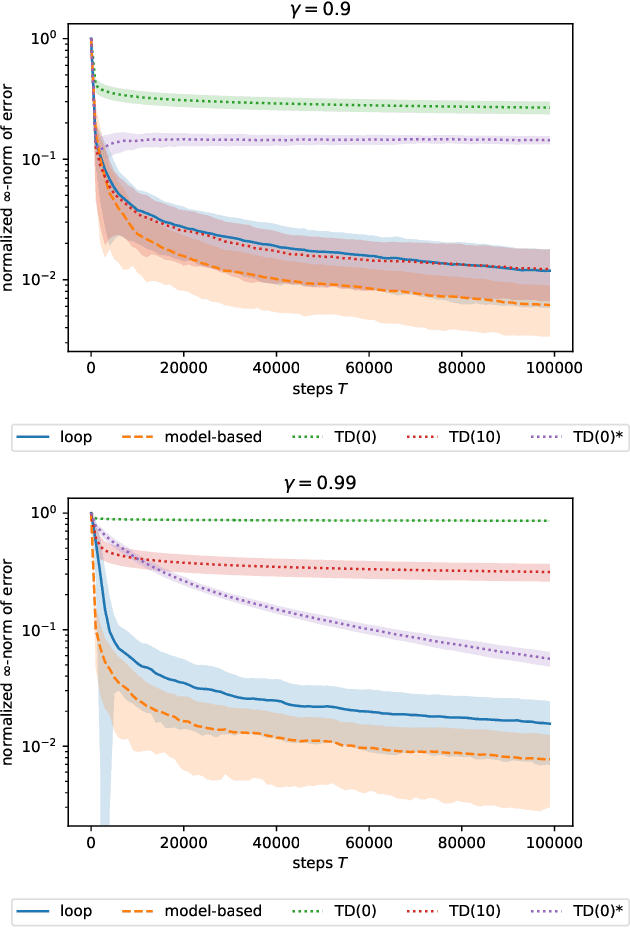
At the working heart of policy iteration algorithms commonly used and studied in the discounted setting of reinforcement learning, the policy evaluation step estimates the value of state with samples from a Markov reward process induced by following a Markov policy in a Markov decision process. We propose a simple and efficient estimator called \emph{loop estimator} that exploits the regenerative structure of Markov reward processes without explicitly estimating a full model. Our method enjoys a space complexity of $O(1)$ when estimating the value of a single positive recurrent state $s$ unlike TD (with $O(S)$) or model-based methods (with $O(S^2)$). Moreover, the regenerative structure enables us to show, without relying on the generative model approach, that the estimator has an instance-dependent convergence rate of $\widetilde{O}(\sqrt{\tau_s/T})$ over steps $T$ on a single sample path, where $\tau_s$ is the maximal expected hitting time to state $s$. In preliminary numerical experiments, the loop estimator outperforms model-free methods, such as TD(k), and is competitive with the model-based estimator.
DIODE: A Dense Indoor and Outdoor DEpth Dataset
Aug 29, 2019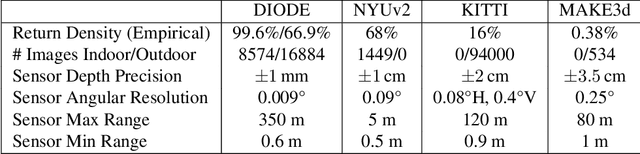
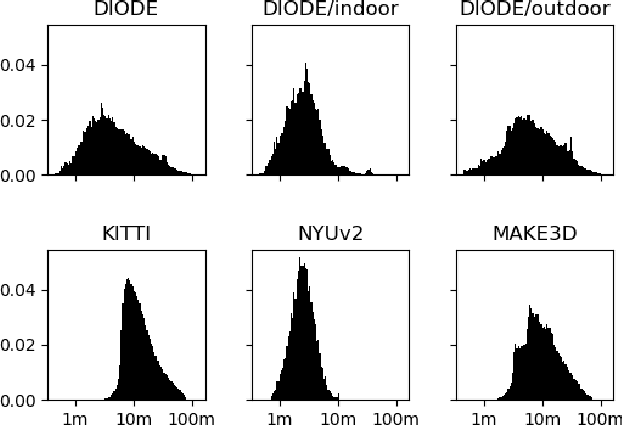
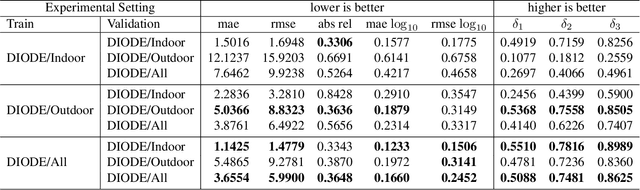
We introduce DIODE, a dataset that contains thousands of diverse high resolution color images with accurate, dense, long-range depth measurements. DIODE (Dense Indoor/Outdoor DEpth) is the first public dataset to include RGBD images of indoor and outdoor scenes obtained with one sensor suite. This is in contrast to existing datasets that focus on just one domain/scene type and employ different sensors, making generalization across domains difficult. The dataset is available for download at http://diode-dataset.org
Towards Near-imperceptible Steganographic Text
Jul 29, 2019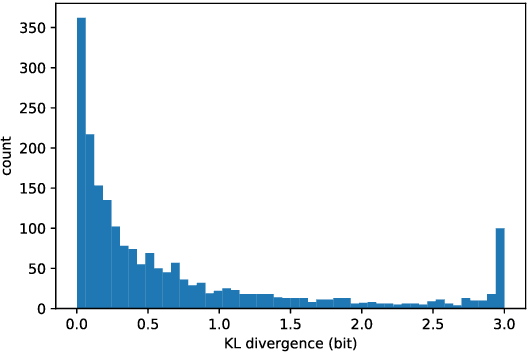
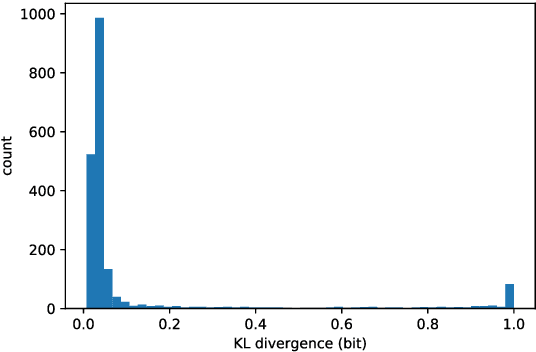
We show that the imperceptibility of several existing linguistic steganographic systems (Fang et al., 2017; Yang et al., 2018) relies on implicit assumptions on statistical behaviors of fluent text. We formally analyze them and empirically evaluate these assumptions. Furthermore, based on these observations, we propose an encoding algorithm called patient-Huffman with improved near-imperceptible guarantees.
Maximum Expected Hitting Cost of a Markov Decision Process and Informativeness of Rewards
Jul 03, 2019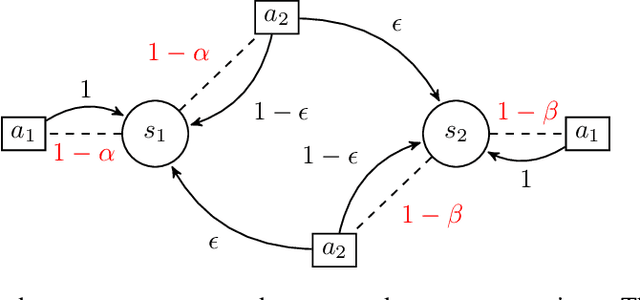
We propose a new complexity measure for Markov decision processes (MDP), the maximum expected hitting cost (MEHC). This measure tightens the closely related notion of diameter [JOA10] by accounting for the reward structure. We show that this parameter replaces diameter in the upper bound on the optimal value span of an extended MDP, thus refining the associated upper bounds on the regret of several UCRL2-like algorithms. Furthermore, we show that potential-based reward shaping [NHR99] can induce equivalent reward functions with varying informativeness, as measured by MEHC. We further establish that shaping can reduce or increase MEHC by at most a factor of two in a large class of MDPs with finite MEHC and unsaturated optimal average rewards.
End-to-End Content and Plan Selection for Data-to-Text Generation
Oct 10, 2018
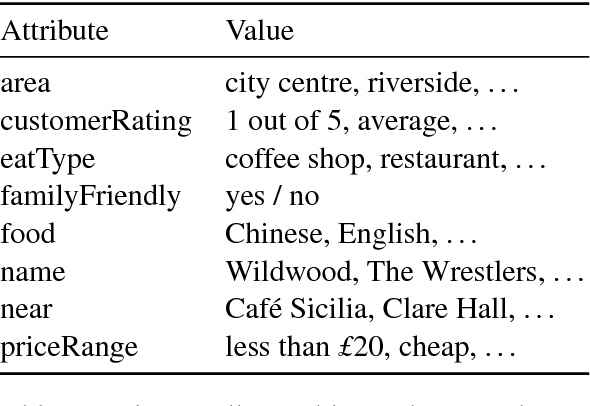
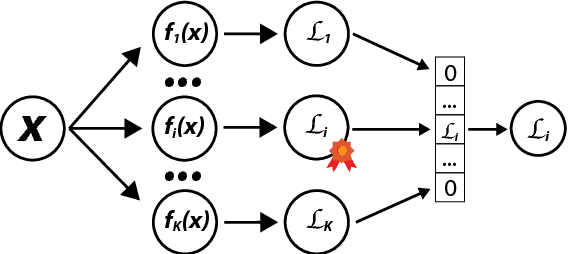
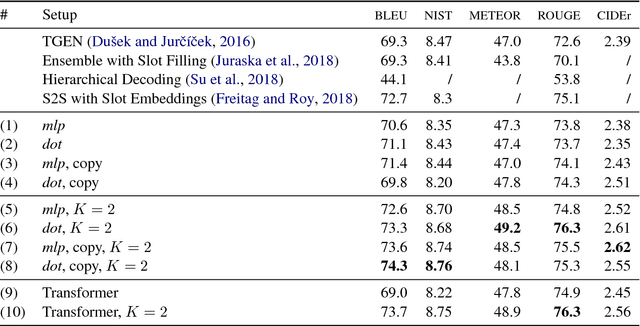
Learning to generate fluent natural language from structured data with neural networks has become an common approach for NLG. This problem can be challenging when the form of the structured data varies between examples. This paper presents a survey of several extensions to sequence-to-sequence models to account for the latent content selection process, particularly variants of copy attention and coverage decoding. We further propose a training method based on diverse ensembling to encourage models to learn distinct sentence templates during training. An empirical evaluation of these techniques shows an increase in the quality of generated text across five automated metrics, as well as human evaluation.