 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Expected Hitting Cost of a Markov Decision Process and Informativeness of Rewards
Paper and Code
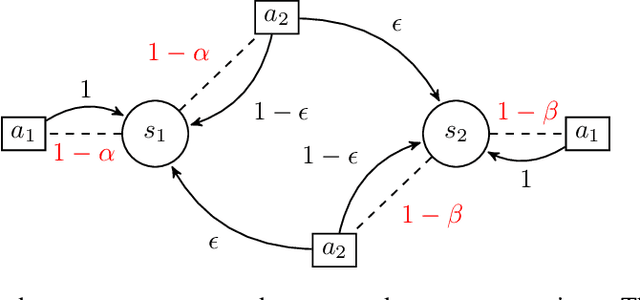
We propose a new complexity measure for Markov decision processes (MDP), the maximum expected hitting cost (MEHC). This measure tightens the closely related notion of diameter [JOA10] by accounting for the reward structure. We show that this parameter replaces diameter in the upper bound on the optimal value span of an extended MDP, thus refining the associated upper bounds on the regret of several UCRL2-like algorithms. Furthermore, we show that potential-based reward shaping [NHR99] can induce equivalent reward functions with varying informativeness, as measured by MEHC. We further establish that shaping can reduce or increase MEHC by at most a factor of two in a large class of MDPs with finite MEHC and unsaturated optimal average rewards.