 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape of synth to come: Why we should use synthetic data for English surface realization
May 06, 2020
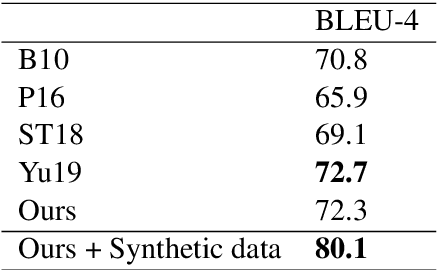

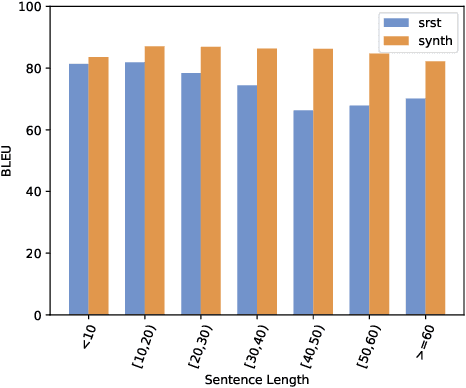
The Surface Realization Shared Tasks of 2018 and 2019 were Natural Language Generation shared tasks with the goal of exploring approaches to surface realization from Universal-Dependency-like trees to surface strings for several languages. In the 2018 shared task there was very little difference in the absolute performance of systems trained with and without additional, synthetically created data, and a new rule prohibiting the use of synthetic data was introduced for the 2019 shared task. Contrary to the findings of the 2018 shared task, we show, in experiments on the English 2018 dataset, that the use of synthetic data can have a substantial positive effect - an improvement of almost 8 BLEU points for a previously state-of-the-art system. We analyse the effects of synthetic data, and we argue that its use should be encouraged rather than prohibited so that future research efforts continue to explore systems that can take advantage of such data.
Designing a Symbolic Intermediate Representation for Neural Surface Realization
May 24, 2019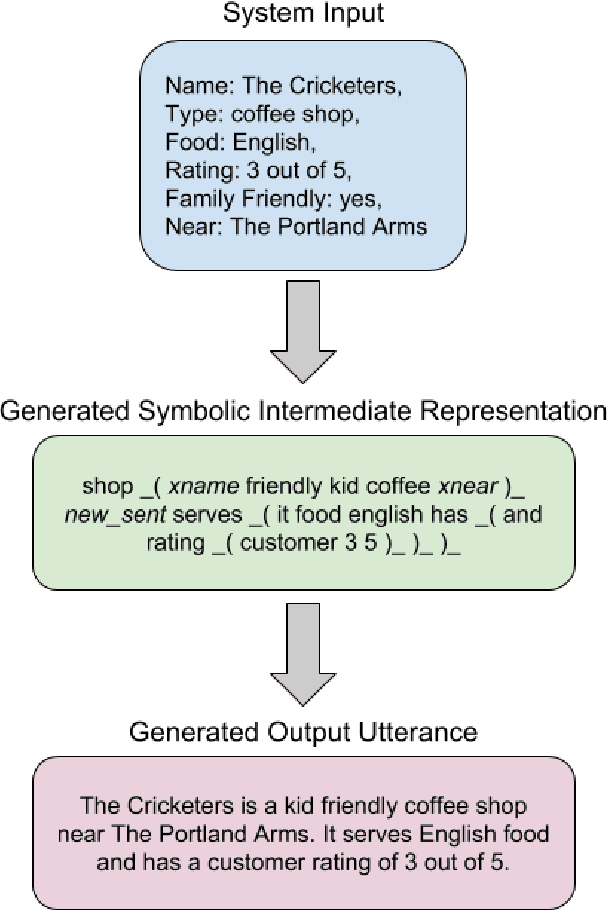



Generated output from neural NLG systems often contain errors such as hallucination, repetition or contradiction. This work focuses on designing a symbolic intermediate representation to be used in multi-stage neural generation with the intention of reducing the frequency of failed outputs. We show that surface realization from this intermediate representation is of high quality and when the full system is applied to the E2E dataset it outperforms the winner of the E2E challenge. Furthermore, by breaking out the surface realization step from typically end-to-end neural systems, we also provide a framework for non-neural content selection and planning systems to potentially take advantage of semi-supervised pretraining of neural surface realization models.
End-to-End Content and Plan Selection for Data-to-Text Generation
Oct 10, 2018
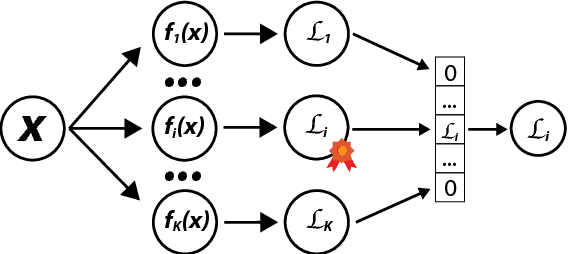
Learning to generate fluent natural language from structured data with neural networks has become an common approach for NLG. This problem can be challenging when the form of the structured data varies between examples. This paper presents a survey of several extensions to sequence-to-sequence models to account for the latent content selection process, particularly variants of copy attention and coverage decoding. We further propose a training method based on diverse ensembling to encourage models to learn distinct sentence templates during training. An empirical evaluation of these techniques shows an increase in the quality of generated text across five automated metrics, as well as human evaluation.
Generating High-Quality Surface Realizations Using Data Augmentation and Factored Sequence Models
May 20, 2018
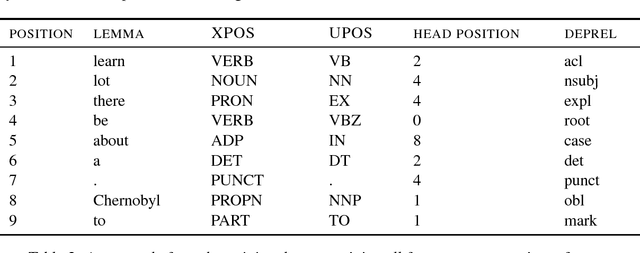


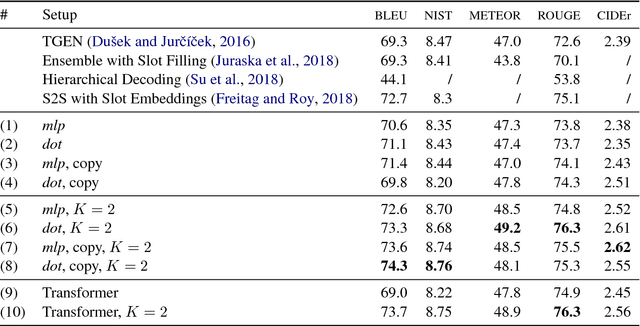
This work presents a new state of the art in reconstruction of surface realizations from obfuscated text. We identify the lack of sufficient training data as the major obstacle to training high-performing models, and solve this issue by generating large amounts of synthetic training data. We also propose preprocessing techniques which make the structure contained in the input features more accessible to sequence models. Our models were ranked first on all evaluation metrics in the English portion of the 2018 Surface Realization shared task.