Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating High-Quality Surface Realizations Using Data Augmentation and Factored Sequence Models
Paper and Code
May 20, 2018
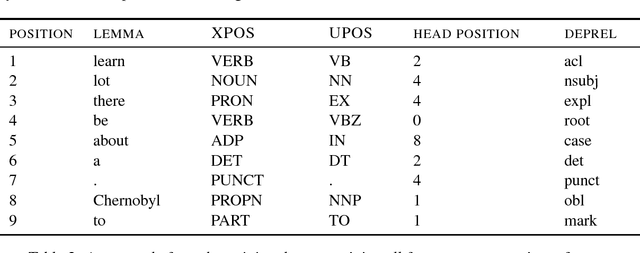


This work presents a new state of the art in reconstruction of surface realizations from obfuscated text. We identify the lack of sufficient training data as the major obstacle to training high-performing models, and solve this issue by generating large amounts of synthetic training data. We also propose preprocessing techniques which make the structure contained in the input features more accessible to sequence models. Our models were ranked first on all evaluation metrics in the English portion of the 2018 Surface Realization shared task.
View paper on