 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape of synth to come: Why we should use synthetic data for English surface realization
Paper and Code

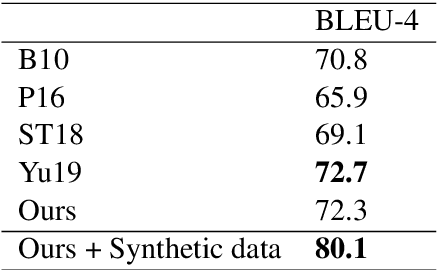

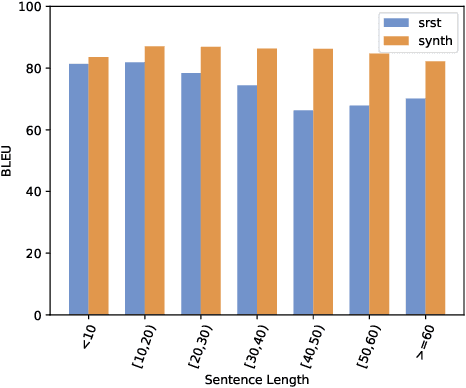
The Surface Realization Shared Tasks of 2018 and 2019 were Natural Language Generation shared tasks with the goal of exploring approaches to surface realization from Universal-Dependency-like trees to surface strings for several languages. In the 2018 shared task there was very little difference in the absolute performance of systems trained with and without additional, synthetically created data, and a new rule prohibiting the use of synthetic data was introduced for the 2019 shared task. Contrary to the findings of the 2018 shared task, we show, in experiments on the English 2018 dataset, that the use of synthetic data can have a substantial positive effect - an improvement of almost 8 BLEU points for a previously state-of-the-art system. We analyse the effects of synthetic data, and we argue that its use should be encouraged rather than prohibited so that future research efforts continue to explore systems that can take advantage of such data.