 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Can Input Reformulation Improve Tool Usage Accuracy in a Complex Dynamic Environment? A Study on $τ$-bench
Aug 28, 2025Recent advances in reasoning and planning capabilities of large language models (LLMs) have enabled their potential as autonomous agents capable of tool use in dynamic environments. However, in multi-turn conversational environments like $\tau$-bench, these agents often struggle with consistent reasoning, adherence to domain-specific policies, and extracting correct information over a long horizon of tool-calls and conversation. To capture and mitigate these failures, we conduct a comprehensive manual analysis of the common errors occurring in the conversation trajectories. We then experiment with reformulations of inputs to the tool-calling agent for improvement in agent decision making. Finally, we propose the Input-Reformulation Multi-Agent (IRMA) framework, which automatically reformulates user queries augmented with relevant domain rules and tool suggestions for the tool-calling agent to focus on. The results show that IRMA significantly outperforms ReAct, Function Calling, and Self-Reflection by 16.1%, 12.7%, and 19.1%, respectively, in overall pass^5 scores. These findings highlight the superior reliability and consistency of IRMA compared to other methods in dynamic environments.
VL-GLUE: A Suite of Fundamental yet Challenging Visuo-Linguistic Reasoning Tasks
Oct 17, 2024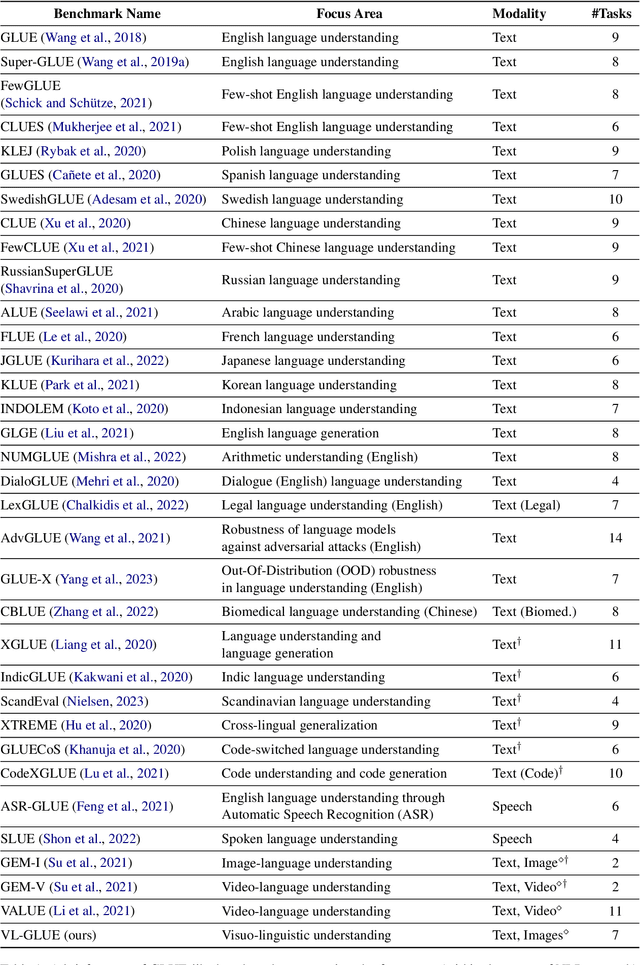

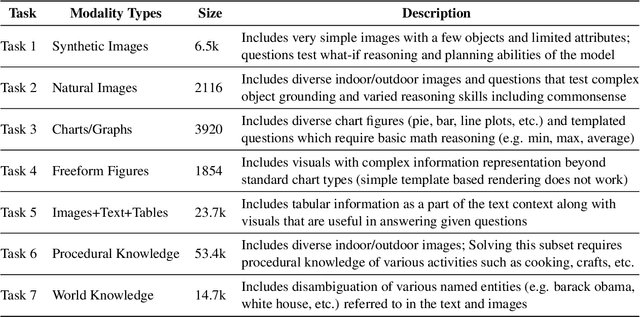

Deriving inference from heterogeneous inputs (such as images, text, and audio) is an important skill for humans to perform day-to-day tasks. A similar ability is desirable for the development of advanced Artificial Intelligence (AI) systems. While state-of-the-art models are rapidly closing the gap with human-level performance on diverse computer vision and NLP tasks separately, they struggle to solve tasks that require joint reasoning over visual and textual modalities. Inspired by GLUE (Wang et. al., 2018)- a multitask benchmark for natural language understanding, we propose VL-GLUE in this paper. VL-GLUE consists of over 100k samples spanned across seven different tasks, which at their core require visuo-linguistic reasoning. Moreover, our benchmark comprises of diverse image types (from synthetically rendered figures, and day-to-day scenes to charts and complex diagrams) and includes a broad variety of domain-specific text (from cooking, politics, and sports to high-school curricula), demonstrating the need for multi-modal understanding in the real-world. We show that this benchmark is quite challenging for existing large-scale vision-language models and encourage development of systems that possess robust visuo-linguistic reasoning capabilities.
Step-by-Step Reasoning to Solve Grid Puzzles: Where do LLMs Falter?
Jul 20, 2024Solving grid puzzles involves a significant amount of logical reasoning. Hence, it is a good domain to evaluate the reasoning capability of a model which can then guide us to improve the reasoning ability of models. However, most existing works evaluate only the final predicted answer of a puzzle, without delving into an in-depth analysis of the LLMs' reasoning chains (such as where they falter) or providing any finer metrics to evaluate them. Since LLMs may rely on simple heuristics or artifacts to predict the final answer, it is crucial to evaluate the generated reasoning chain beyond overall correctness measures, for accurately evaluating the reasoning abilities of LLMs. To this end, we first develop GridPuzzle, an evaluation dataset comprising 274 grid-based puzzles with different complexities. Second, we propose a new error taxonomy derived from manual analysis of reasoning chains from LLMs including GPT-4, Claude-3, Gemini, Mistral, and Llama-2. Then, we develop an LLM-based framework for large-scale subjective evaluation (i.e., identifying errors) and an objective metric, PuzzleEval, to evaluate the correctness of reasoning chains. Evaluating reasoning chains from LLMs leads to several interesting findings. We further show that existing prompting methods used for enhancing models' reasoning abilities do not improve performance on GridPuzzle. This highlights the importance of understanding fine-grained errors and presents a challenge for future research to enhance LLMs' puzzle-solving abilities by developing methods that address these errors. Data and source code are available at https://github.com/Mihir3009/GridPuzzle.
Multi-LogiEval: Towards Evaluating Multi-Step Logical Reasoning Ability of Large Language Models
Jun 24, 2024



As Large Language Models (LLMs) continue to exhibit remarkable performance in natural language understanding tasks, there is a crucial need to measure their ability for human-like multi-step logical reasoning. Existing logical reasoning evaluation benchmarks often focus primarily on simplistic single-step or multi-step reasoning with a limited set of inference rules. Furthermore, the lack of datasets for evaluating non-monotonic reasoning represents a crucial gap since it aligns more closely with human-like reasoning. To address these limitations, we propose Multi-LogiEval, a comprehensive evaluation dataset encompassing multi-step logical reasoning with various inference rules and depths. Multi-LogiEval covers three logic types--propositional, first-order, and non-monotonic--consisting of more than 30 inference rules and more than 60 of their combinations with various depths. Leveraging this dataset, we conduct evaluations on a range of LLMs including GPT-4, ChatGPT, Gemini-Pro, Yi, Orca, and Mistral, employing a zero-shot chain-of-thought. Experimental results show that there is a significant drop in the performance of LLMs as the reasoning steps/depth increases (average accuracy of ~68% at depth-1 to ~43% at depth-5). We further conduct a thorough investigation of reasoning chains generated by LLMs which reveals several important findings. We believe that Multi-LogiEval facilitates future research for evaluating and enhancing the logical reasoning ability of LLMs. Data is available at https://github.com/Mihir3009/Multi-LogiEval.
Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models
Apr 23, 2024Recently developed large language models (LLMs) have been shown to perform remarkably well on a wide range of language understanding tasks. But, can they really "reason" over the natural language? This question has been receiving significant research attention and many reasoning skills such as commonsense, numerical, and qualitative have been studied. However, the crucial skill pertaining to 'logical reasoning' has remained underexplored. Existing work investigating this reasoning ability of LLMs has focused only on a couple of inference rules (such as modus ponens and modus tollens) of propositional and first-order logic. Addressing the above limitation, we comprehensively evaluate the logical reasoning ability of LLMs on 25 different reasoning patterns spanning over propositional, first-order, and non-monotonic logics. To enable systematic evaluation, we introduce LogicBench, a natural language question-answering dataset focusing on the use of a single inference rule. We conduct detailed analysis with a range of LLMs such as GPT-4, ChatGPT, Gemini, Llama-2, and Mistral using chain-of-thought prompting. Experimental results show that existing LLMs do not fare well on LogicBench; especially, they struggle with instances involving complex reasoning and negations. Furthermore, they sometimes overlook contextual information necessary for reasoning to arrive at the correct conclusion. We believe that our work and findings facilitate future research for evaluating and enhancing the logical reasoning ability of LLMs. Data and code are available at https://github.com/Mihir3009/LogicBench.