 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use of Context for Predicting Citation Worthiness of Sentences in Scholarly Articles
Apr 18, 2021
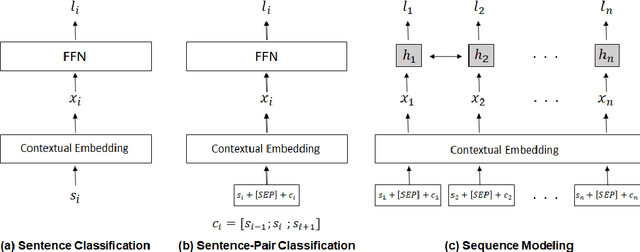
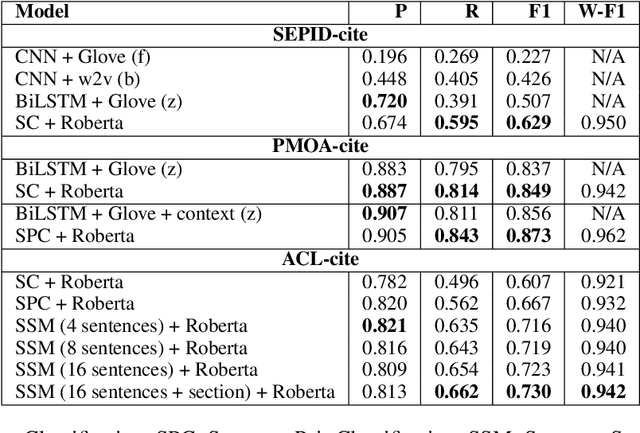
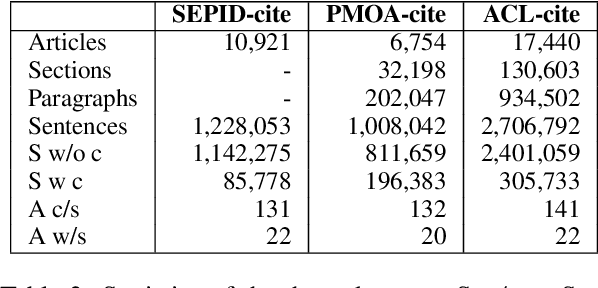
In this paper, we study the importance of context in predicting the citation worthiness of sentences in scholarly articles. We formulate this problem as a sequence labeling task solved using a hierarchical BiLSTM model. We contribute a new benchmark dataset containing over two million sentences and their corresponding labels. We preserve the sentence order in this dataset and perform document-level train/test splits, which importantly allows incorporating contextual information in the modeling process. We evaluate the proposed approach on three benchmark datasets. Our results quantify the benefits of using context and contextual embeddings for citation worthiness. Lastly, through error analysis, we provide insights into cases where context plays an essential role in predicting citation worthiness.