 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge#MeTooMA: Multi-Aspect Annotations of Tweets Related to the MeToo Movement
Paper and Code

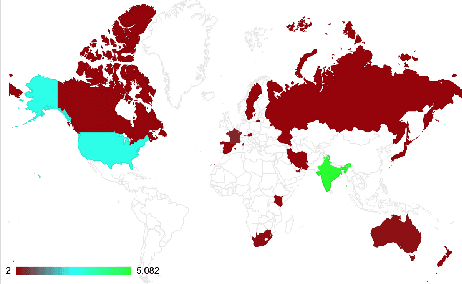

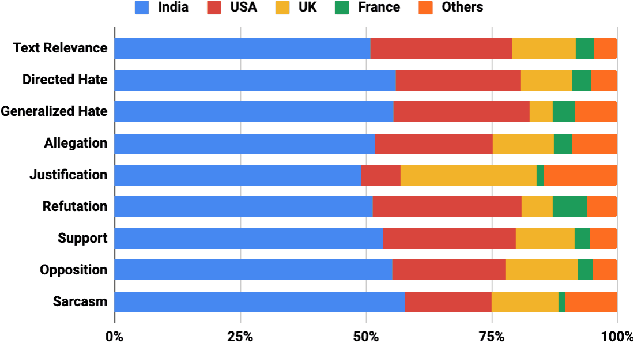
In this paper, we present a dataset containing 9,973 tweets related to the MeToo movement that were manually annotated for five different linguistic aspects: relevance, stance, hate speech, sarcasm, and dialogue acts. We present a detailed account of the data collection and annotation processes. The annotations have a very high inter-annotator agreement (0.79 to 0.93 k-alpha) due to the domain expertise of the annotators and clear annotation instructions. We analyze the data in terms of geographical distribution, label correlations, and keywords. Lastly, we present some potential use cases of this dataset. We expect this dataset would be of great interest to psycholinguists, socio-linguists, and computational linguists to study the discursive space of digitally mobilized social movements on sensitive issues like sexual harassment.