 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-NormFedAvg: Normalizing Client Updates for Privacy-Preserving Federated Learning
Paper and Code
Jun 13, 2021
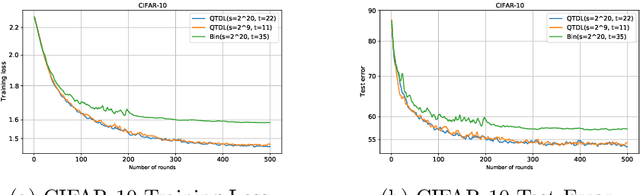

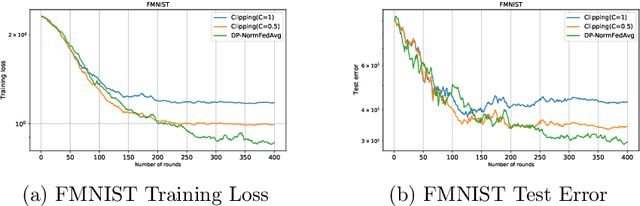
In this paper, we focus on facilitating differentially private quantized communication between the clients and server in federated learning (FL). Towards this end, we propose to have the clients send a \textit{private quantized} version of only the \textit{unit vector} along the change in their local parameters to the server, \textit{completely throwing away the magnitude information}. We call this algorithm \texttt{DP-NormFedAvg} and show that it has the same order-wise convergence rate as \texttt{FedAvg} on smooth quasar-convex functions (an important class of non-convex functions for modeling optimization of deep neural networks), thereby establishing that discarding the magnitude information is not detrimental from an optimization point of view. We also introduce QTDL, a new differentially private quantization mechanism for unit-norm vectors, which we use in \texttt{DP-NormFedAvg}. QTDL employs \textit{discrete} noise having a Laplacian-like distribution on a \textit{finite support} to provide privacy. We show that under a growth-condition assumption on the per-sample client losses, the extra per-coordinate communication cost in each round incurred due to privacy by our method is $\mathcal{O}(1)$ with respect to the model dimension, which is an improvement over prior work. Finally, we show the efficacy of our proposed method with experiments on fully-connected neural networks trained on CIFAR-10 and Fashion-MNIST.