 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Retrieval-Augmented Generation without Automatic Speech Recognition
Dec 21, 2024



One common approach for question answering over speech data is to first transcribe speech using automatic speech recognition (ASR) and then employ text-based retrieval-augmented generation (RAG) on the transcriptions. While this cascaded pipeline has proven effective in many practical settings, ASR errors can propagate to the retrieval and generation steps. To overcome this limitation, we introduce SpeechRAG, a novel framework designed for open-question answering over spoken data. Our proposed approach fine-tunes a pre-trained speech encoder into a speech adapter fed into a frozen large language model (LLM)--based retrieval model. By aligning the embedding spaces of text and speech, our speech retriever directly retrieves audio passages from text-based queries, leveraging the retrieval capacity of the frozen text retriever. Our retrieval experiments on spoken question answering datasets show that direct speech retrieval does not degrade over the text-based baseline, and outperforms the cascaded systems using ASR. For generation, we use a speech language model (SLM) as a generator, conditioned on audio passages rather than transcripts. Without fine-tuning of the SLM, this approach outperforms cascaded text-based models when there is high WER in the transcripts.
Dynamic Reward Adjustment in Multi-Reward Reinforcement Learning for Counselor Reflection Generation
Mar 20, 2024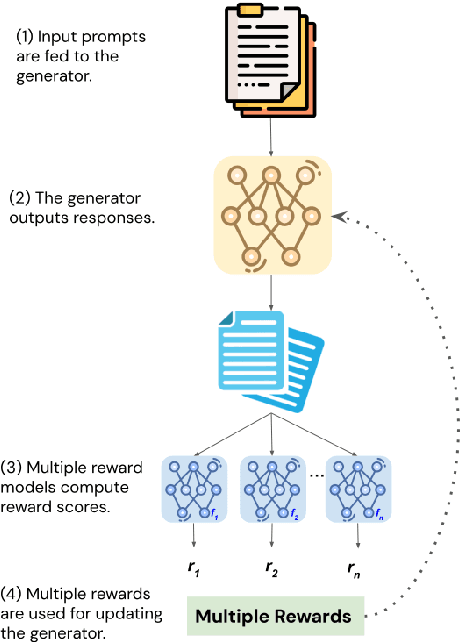
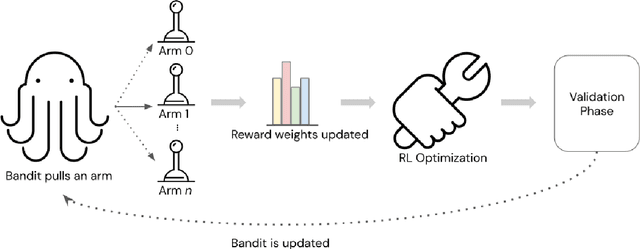

In this paper, we study the problem of multi-reward reinforcement learning to jointly optimize for multiple text qualities for natural language generation. We focus on the task of counselor reflection generation, where we optimize the generators to simultaneously improve the fluency, coherence, and reflection quality of generated counselor responses. We introduce two novel bandit methods, DynaOpt and C-DynaOpt, which rely on the broad strategy of combining rewards into a single value and optimizing them simultaneously. Specifically, we employ non-contextual and contextual multi-arm bandits to dynamically adjust multiple reward weights during training. Through automatic and manual evaluations, we show that our proposed techniques, DynaOpt and C-DynaOpt, outperform existing naive and bandit baselines, showcasing their potential for enhancing language models.
VERVE: Template-based ReflectiVE Rewriting for MotiVational IntErviewing
Nov 14, 2023



Reflective listening is a fundamental skill that counselors must acquire to achieve proficiency in motivational interviewing (MI). It involves responding in a manner that acknowledges and explores the meaning of what the client has expressed in the conversation. In this work, we introduce the task of counseling response rewriting, which transforms non-reflective statements into reflective responses. We introduce VERVE, a template-based rewriting system with paraphrase-augmented training and adaptive template updating. VERVE first creates a template by identifying and filtering out tokens that are not relevant to reflections and constructs a reflective response using the template. Paraphrase-augmented training allows the model to learn less-strict fillings of masked spans, and adaptive template updating helps discover effective templates for rewriting without significantly removing the original content. Using both automatic and human evaluations, we compare our method against text rewriting baselines and show that our framework is effective in turning non-reflective statements into more reflective responses while achieving a good content preservation-reflection style trade-off.
Workflow-Guided Response Generation for Task-Oriented Dialogue
Nov 14, 2023


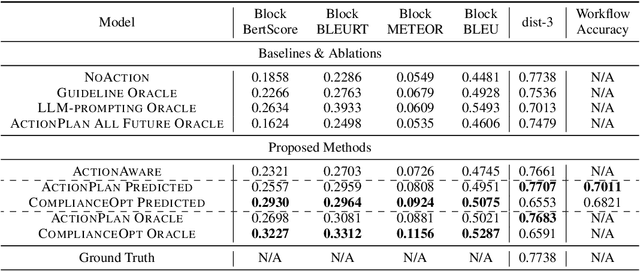
Task-oriented dialogue (TOD) systems aim to achieve specific goals through interactive dialogue. Such tasks usually involve following specific workflows, i.e. executing a sequence of actions in a particular order. While prior work has focused on supervised learning methods to condition on past actions, they do not explicitly optimize for compliance to a desired workflow. In this paper, we propose a novel framework based on reinforcement learning (RL) to generate dialogue responses that are aligned with a given workflow. Our framework consists of ComplianceScorer, a metric designed to evaluate how well a generated response executes the specified action, combined with an RL opimization process that utilizes an interactive sampling technique. We evaluate our approach on two TOD datasets, Action-Based Conversations Dataset (ABCD) (Chen et al., 2021a) and MultiWOZ 2.2 (Zang et al., 2020) on a range of automated and human evaluation metrics. Our findings indicate that our RL-based framework outperforms baselines and is effective at enerating responses that both comply with the intended workflows while being expressed in a natural and fluent manner.
A PhD Student's Perspective on Research in NLP in the Era of Very Large Language Models
May 21, 2023Recent progress in large language models has enabled the deployment of many generative NLP applications. At the same time, it has also led to a misleading public discourse that ``it's all been solved.'' Not surprisingly, this has in turn made many NLP researchers -- especially those at the beginning of their career -- wonder about what NLP research area they should focus on. This document is a compilation of NLP research directions that are rich for exploration, reflecting the views of a diverse group of PhD students in an academic research lab. While we identify many research areas, many others exist; we do not cover those areas that are currently addressed by LLMs but where LLMs lag behind in performance, or those focused on LLM development. We welcome suggestions for other research directions to include: https://bit.ly/nlp-era-llm
Adaptive Endpointing with Deep Contextual Multi-armed Bandits
Mar 23, 2023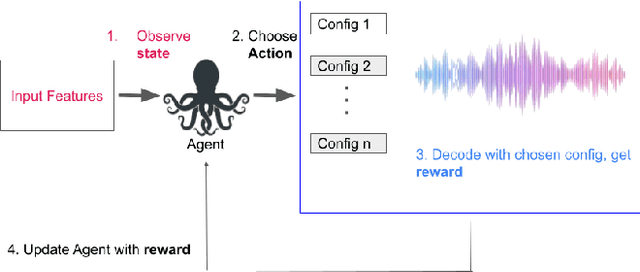

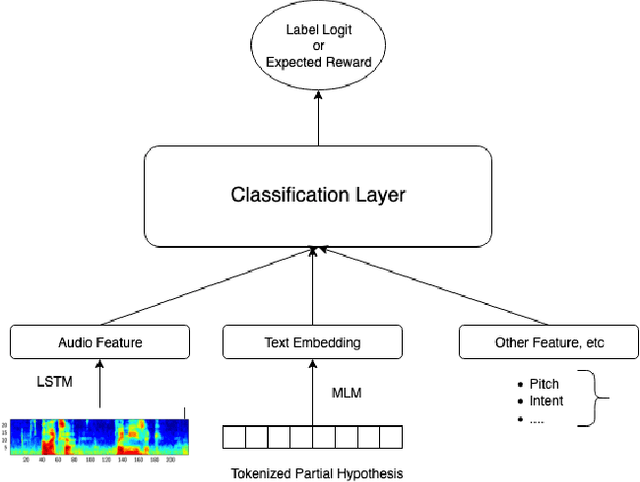
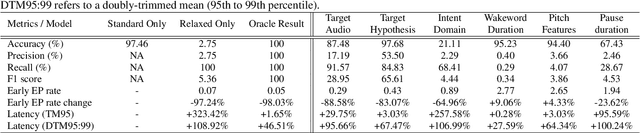
Current endpointing (EP) solutions learn in a supervised framework, which does not allow the model to incorporate feedback and improve in an online setting. Also, it is a common practice to utilize costly grid-search to find the best configuration for an endpointing model. In this paper, we aim to provide a solution for adaptive endpointing by proposing an efficient method for choosing an optimal endpointing configuration given utterance-level audio features in an online setting, while avoiding hyperparameter grid-search. Our method does not require ground truth labels, and only uses online learning from reward signals without requiring annotated labels. Specifically, we propose a deep contextual multi-armed bandit-based approach, which combines the representational power of neural networks with the action exploration behavior of Thompson modeling algorithms. We compare our approach to several baselines, and show that our deep bandit models also succeed in reducing early cutoff errors while maintaining low latency.