 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Evaluation of LLM Strategies for Mental Health Text Analysis: Fine-tuning vs. Prompt Engineering vs. RAG
Mar 31, 2025This study presents a systematic comparison of three approaches for the analysis of mental health text using large language models (LLMs): prompt engineering, retrieval augmented generation (RAG), and fine-tuning. Using LLaMA 3, we evaluate these approaches on emotion classification and mental health condition detection tasks across two datasets. Fine-tuning achieves the highest accuracy (91% for emotion classification, 80% for mental health conditions) but requires substantial computational resources and large training sets, while prompt engineering and RAG offer more flexible deployment with moderate performance (40-68% accuracy). Our findings provide practical insights for implementing LLM-based solutions in mental health applications, highlighting the trade-offs between accuracy, computational requirements, and deployment flexibility.
Dynamic Reward Adjustment in Multi-Reward Reinforcement Learning for Counselor Reflection Generation
Mar 20, 2024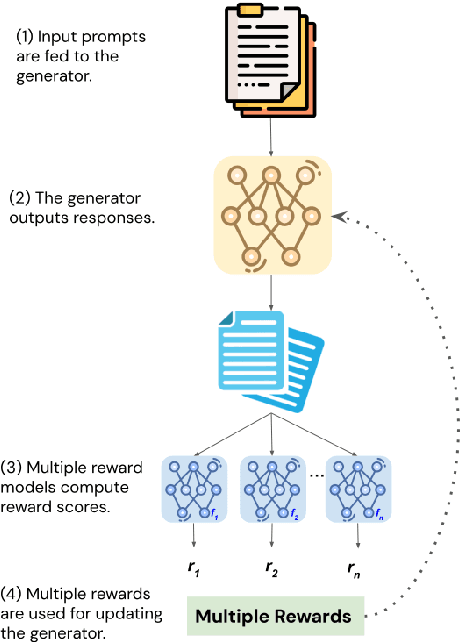
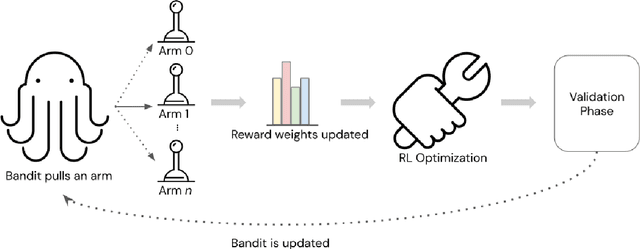

In this paper, we study the problem of multi-reward reinforcement learning to jointly optimize for multiple text qualities for natural language generation. We focus on the task of counselor reflection generation, where we optimize the generators to simultaneously improve the fluency, coherence, and reflection quality of generated counselor responses. We introduce two novel bandit methods, DynaOpt and C-DynaOpt, which rely on the broad strategy of combining rewards into a single value and optimizing them simultaneously. Specifically, we employ non-contextual and contextual multi-arm bandits to dynamically adjust multiple reward weights during training. Through automatic and manual evaluations, we show that our proposed techniques, DynaOpt and C-DynaOpt, outperform existing naive and bandit baselines, showcasing their potential for enhancing language models.
A PhD Student's Perspective on Research in NLP in the Era of Very Large Language Models
May 21, 2023Recent progress in large language models has enabled the deployment of many generative NLP applications. At the same time, it has also led to a misleading public discourse that ``it's all been solved.'' Not surprisingly, this has in turn made many NLP researchers -- especially those at the beginning of their career -- wonder about what NLP research area they should focus on. This document is a compilation of NLP research directions that are rich for exploration, reflecting the views of a diverse group of PhD students in an academic research lab. While we identify many research areas, many others exist; we do not cover those areas that are currently addressed by LLMs but where LLMs lag behind in performance, or those focused on LLM development. We welcome suggestions for other research directions to include: https://bit.ly/nlp-era-llm