 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-loop POMDP Simplification and Safe Skipping of Replanning with Formal Performance Guarantees
Apr 01, 2026Partially Observable Markov Decision Processes (POMDPs) provide a principled mathematical framework for decision-making under uncertainty. However, the exact solution to POMDPs is computationally intractable. In this paper, we address the computational intractability by introducing a novel framework for adaptive open-loop simplification with formal performance guarantees. Our method adaptively interleaves open-loop and closed-loop planning via a topology-based belief tree, enabling a significant reduction in planning complexity. The key contribution lies in the derivation of efficiently computable bounds which provide formal guarantees and can be used to ensure that our simplification can identify the immediate optimal action of the original POMDP problem. Our framework therefore provides computationally tractable performance guarantees for macro-actions within POMDPs. Furthermore, we propose a novel framework for safely skipping replanning during execution, supported by theoretical guarantees on multi-step open-loop action sequences. To the best of our knowledge, this framework is the first to address skipping replanning with formal performance guarantees. Practical online solvers for our proposed simplification are developed, including a sampling-based solver and an anytime solver. Empirical results demonstrate substantial computational speedups while maintaining provable performance guarantees, advancing the tractability and efficiency of POMDP planning.
Accelerated Online Risk-Averse Policy Evaluation in POMDPs with Theoretical Guarantees and Novel CVaR Bounds
Feb 26, 2026Risk-averse decision-making under uncertainty in partially observable domains is a central challenge in artificial intelligence and is essential for developing reliable autonomous agents. The formal framework for such problems is the partially observable Markov decision process (POMDP), where risk sensitivity is introduced through a risk measure applied to the value function, with Conditional Value-at-Risk (CVaR) being a particularly significant criterion. However, solving POMDPs is computationally intractable in general, and approximate methods rely on computationally expensive simulations of future agent trajectories. This work introduces a theoretical framework for accelerating CVaR value function evaluation in POMDPs with formal performance guarantees. We derive new bounds on the CVaR of a random variable X using an auxiliary random variable Y, under assumptions relating their cumulative distribution and density functions; these bounds yield interpretable concentration inequalities and converge as the distributional discrepancy vanishes. Building on this, we establish upper and lower bounds on the CVaR value function computable from a simplified belief-MDP, accommodating general simplifications of the transition dynamics. We develop estimators for these bounds within a particle-belief MDP framework with probabilistic guarantees, and employ them for acceleration via action elimination: actions whose bounds indicate suboptimality under the simplified model are safely discarded while ensuring consistency with the original POMDP. Empirical evaluation across multiple POMDP domains confirms that the bounds reliably separate safe from dangerous policies while achieving substantial computational speedups under the simplified model.
POMDPPlanners: Open-Source Package for POMDP Planning
Feb 24, 2026We present POMDPPlanners, an open-source Python package for empirical evaluation of Partially Observable Markov Decision Process (POMDP) planning algorithms. The package integrates state-of-the-art planning algorithms, a suite of benchmark environments with safety-critical variants, automated hyperparameter optimization via Optuna, persistent caching with failure recovery, and configurable parallel simulation -- reducing the overhead of extensive simulation studies. POMDPPlanners is designed to enable scalable, reproducible research on decision-making under uncertainty, with particular emphasis on risk-sensitive settings where standard toolkits fall short.
Online Risk-Averse Planning in POMDPs Using Iterated CVaR Value Function
Jan 28, 2026We study risk-sensitive planning under partial observability using the dynamic risk measure Iterated Conditional Value-at-Risk (ICVaR). A policy evaluation algorithm for ICVaR is developed with finite-time performance guarantees that do not depend on the cardinality of the action space. Building on this foundation, three widely used online planning algorithms--Sparse Sampling, Particle Filter Trees with Double Progressive Widening (PFT-DPW), and Partially Observable Monte Carlo Planning with Observation Widening (POMCPOW)--are extended to optimize the ICVaR value function rather than the expectation of the return. Our formulations introduce a risk parameter $α$, where $α= 1$ recovers standard expectation-based planning and $α< 1$ induces increasing risk aversion. For ICVaR Sparse Sampling, we establish finite-time performance guarantees under the risk-sensitive objective, which further enable a novel exploration strategy tailored to ICVaR. Experiments on benchmark POMDP domains demonstrate that the proposed ICVaR planners achieve lower tail risk compared to their risk-neutral counterparts.
Towards Optimal Performance and Action Consistency Guarantees in Dec-POMDPs with Inconsistent Beliefs and Limited Communication
Dec 23, 2025Multi-agent decision-making under uncertainty is fundamental for effective and safe autonomous operation. In many real-world scenarios, each agent maintains its own belief over the environment and must plan actions accordingly. However, most existing approaches assume that all agents have identical beliefs at planning time, implying these beliefs are conditioned on the same data. Such an assumption is often impractical due to limited communication. In reality, agents frequently operate with inconsistent beliefs, which can lead to poor coordination and suboptimal, potentially unsafe, performance. In this paper, we address this critical challenge by introducing a novel decentralized framework for optimal joint action selection that explicitly accounts for belief inconsistencies. Our approach provides probabilistic guarantees for both action consistency and performance with respect to open-loop multi-agent POMDP (which assumes all data is always communicated), and selectively triggers communication only when needed. Furthermore, we address another key aspect of whether, given a chosen joint action, the agents should share data to improve expected performance in inference. Simulation results show our approach outperforms state-of-the-art algorithms.
Value Gradients with Action Adaptive Search Trees in Continuous (PO)MDPs
Mar 15, 2025



Solving Partially Observable Markov Decision Processes (POMDPs) in continuous state, action and observation spaces is key for autonomous planning in many real-world mobility and robotics applications. Current approaches are mostly sample based, and cannot hope to reach near-optimal solutions in reasonable time. We propose two complementary theoretical contributions. First, we formulate a novel Multiple Importance Sampling (MIS) tree for value estimation, that allows to share value information between sibling action branches. The novel MIS tree supports action updates during search time, such as gradient-based updates. Second, we propose a novel methodology to compute value gradients with online sampling based on transition likelihoods. It is applicable to MDPs, and we extend it to POMDPs via particle beliefs with the application of the propagated belief trick. The gradient estimator is computed in practice using the MIS tree with efficient Monte Carlo sampling. These two parts are combined into a new planning algorithm Action Gradient Monte Carlo Tree Search (AGMCTS). We demonstrate in a simulated environment its applicability, advantages over continuous online POMDP solvers that rely solely on sampling, and we discuss further implications.
Anytime Incremental $ρ$POMDP Planning in Continuous Spaces
Feb 04, 2025



Partially Observable Markov Decision Processes (POMDPs) provide a robust framework for decision-making under uncertainty in applications such as autonomous driving and robotic exploration. Their extension, $\rho$POMDPs, introduces belief-dependent rewards, enabling explicit reasoning about uncertainty. Existing online $\rho$POMDP solvers for continuous spaces rely on fixed belief representations, limiting adaptability and refinement - critical for tasks such as information-gathering. We present $\rho$POMCPOW, an anytime solver that dynamically refines belief representations, with formal guarantees of improvement over time. To mitigate the high computational cost of updating belief-dependent rewards, we propose a novel incremental computation approach. We demonstrate its effectiveness for common entropy estimators, reducing computational cost by orders of magnitude. Experimental results show that $\rho$POMCPOW outperforms state-of-the-art solvers in both efficiency and solution quality.
Online Hybrid-Belief POMDP with Coupled Semantic-Geometric Models and Semantic Safety Awareness
Jan 20, 2025Robots operating in complex and unknown environments frequently require geometric-semantic representations of the environment to safely perform their tasks. While inferring the environment, they must account for many possible scenarios when planning future actions. Since objects' class types are discrete and the robot's self-pose and the objects' poses are continuous, the environment can be represented by a hybrid discrete-continuous belief which is updated according to models and incoming data. Prior probabilities and observation models representing the environment can be learned from data using deep learning algorithms. Such models often couple environmental semantic and geometric properties. As a result, semantic variables are interconnected, causing semantic state space dimensionality to increase exponentially. In this paper, we consider planning under uncertainty using partially observable Markov decision processes (POMDPs) with hybrid semantic-geometric beliefs. The models and priors consider the coupling between semantic and geometric variables. Within POMDP, we introduce the concept of semantically aware safety. Obtaining representative samples of the theoretical hybrid belief, required for estimating the value function, is very challenging. As a key contribution, we develop a novel form of the hybrid belief and leverage it to sample representative samples. We show that under certain conditions, the value function and probability of safety can be calculated efficiently with an explicit expectation over all possible semantic mappings. Our simulations show that our estimates of the objective function and probability of safety achieve similar levels of accuracy compared to estimators that run exhaustively on the entire semantic state-space using samples from the theoretical hybrid belief. Nevertheless, the complexity of our estimators is polynomial rather than exponential.
Previous Knowledge Utilization In Online Anytime Belief Space Planning
Dec 17, 2024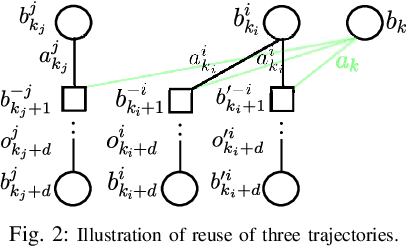
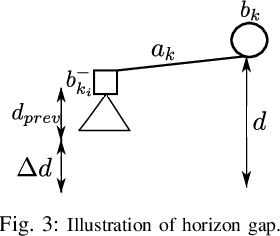
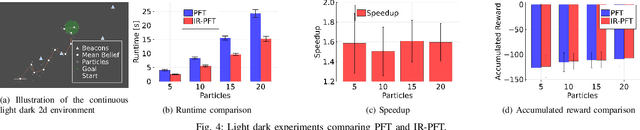
Online planning under uncertainty remains a critical challenge in robotics and autonomous systems. While tree search techniques are commonly employed to construct partial future trajectories within computational constraints, most existing methods discard information from previous planning sessions considering continuous spaces. This study presents a novel, computationally efficient approach that leverages historical planning data in current decision-making processes. We provide theoretical foundations for our information reuse strategy and introduce an algorithm based on Monte Carlo Tree Search (MCTS) that implements this approach. Experimental results demonstrate that our method significantly reduces computation time while maintaining high performance levels. Our findings suggest that integrating historical planning information can substantially improve the efficiency of online decision-making in uncertain environments, paving the way for more responsive and adaptive autonomous systems.
Anytime Probabilistically Constrained Provably Convergent Online Belief Space Planning
Nov 11, 2024Taking into account future risk is essential for an autonomously operating robot to find online not only the best but also a safe action to execute. In this paper, we build upon the recently introduced formulation of probabilistic belief-dependent constraints. We present an anytime approach employing the Monte Carlo Tree Search (MCTS) method in continuous domains. Unlike previous approaches, our method assures safety anytime with respect to the currently expanded search tree without relying on the convergence of the search. We prove convergence in probability with an exponential rate of a version of our algorithms and study proposed techniques via extensive simulations. Even with a tiny number of tree queries, the best action found by our approach is much safer than the baseline. Moreover, our approach constantly finds better than the baseline action in terms of objective. This is because we revise the values and statistics maintained in the search tree and remove from them the contribution of the pruned actions.