 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Resiliency in Large Language Model Serving with KevlarFlow
Jan 30, 2026Large Language Model (LLM) serving systems remain fundamentally fragile, where frequent hardware faults in hyperscale clusters trigger disproportionate service outages in the software stack. Current recovery mechanisms are prohibitively slow, often requiring up to 10 minutes to reinitialize resources and reload massive model weights. We introduce KevlarFlow, a fault tolerant serving architecture designed to bridge the gap between hardware unreliability and service availability. KevlarFlow leverages 1) decoupled model parallelism initialization, 2) dynamic traffic rerouting, and 3) background KV cache replication to maintain high throughput during partial failures. Our evaluation demonstrates that KevlarFlow reduces mean-time-to-recovery (MTTR) by 20x and, under failure conditions, improves average latency by 3.1x, 99th percentile (p99) latency by 2.8x, average time-to-first-token (TTFT) by 378.9x, and p99 TTFT by 574.6x with negligible runtime overhead in comparison to state-of-the-art LLM serving systems.
WAFFLE: Multi-Modal Model for Automated Front-End Development
Oct 24, 2024


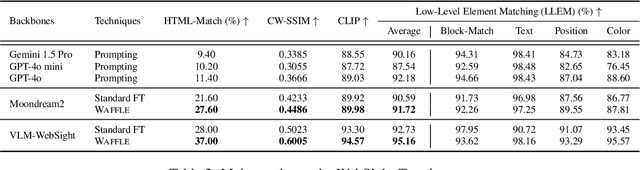
Web development involves turning UI designs into functional webpages, which can be difficult for both beginners and experienced developers due to the complexity of HTML's hierarchical structures and styles. While Large Language Models (LLMs) have shown promise in generating source code, two major challenges persist in UI-to-HTML code generation: (1) effectively representing HTML's hierarchical structure for LLMs, and (2) bridging the gap between the visual nature of UI designs and the text-based format of HTML code. To tackle these challenges, we introduce Waffle, a new fine-tuning strategy that uses a structure-aware attention mechanism to improve LLMs' understanding of HTML's structure and a contrastive fine-tuning approach to align LLMs' understanding of UI images and HTML code. Models fine-tuned with Waffle show up to 9.00 pp (percentage point) higher HTML match, 0.0982 higher CW-SSIM, 32.99 higher CLIP, and 27.12 pp higher LLEM on our new benchmark WebSight-Test and an existing benchmark Design2Code, outperforming current fine-tuning methods.