 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Resiliency in Large Language Model Serving with KevlarFlow
Jan 30, 2026Large Language Model (LLM) serving systems remain fundamentally fragile, where frequent hardware faults in hyperscale clusters trigger disproportionate service outages in the software stack. Current recovery mechanisms are prohibitively slow, often requiring up to 10 minutes to reinitialize resources and reload massive model weights. We introduce KevlarFlow, a fault tolerant serving architecture designed to bridge the gap between hardware unreliability and service availability. KevlarFlow leverages 1) decoupled model parallelism initialization, 2) dynamic traffic rerouting, and 3) background KV cache replication to maintain high throughput during partial failures. Our evaluation demonstrates that KevlarFlow reduces mean-time-to-recovery (MTTR) by 20x and, under failure conditions, improves average latency by 3.1x, 99th percentile (p99) latency by 2.8x, average time-to-first-token (TTFT) by 378.9x, and p99 TTFT by 574.6x with negligible runtime overhead in comparison to state-of-the-art LLM serving systems.
Recovering Partially Corrupted Major Objects through Tri-modality Based Image Completion
Mar 10, 2025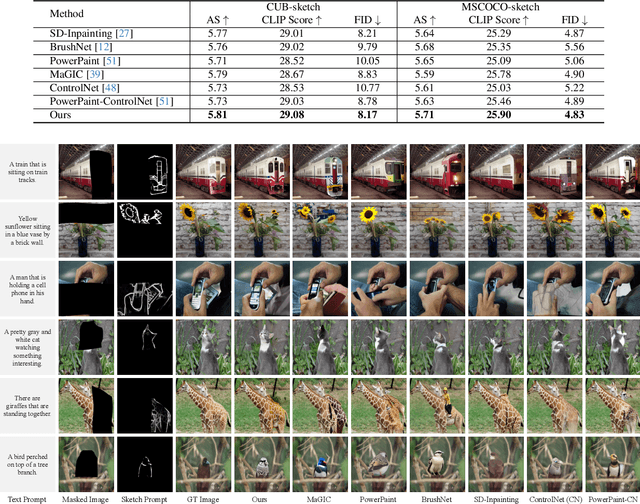
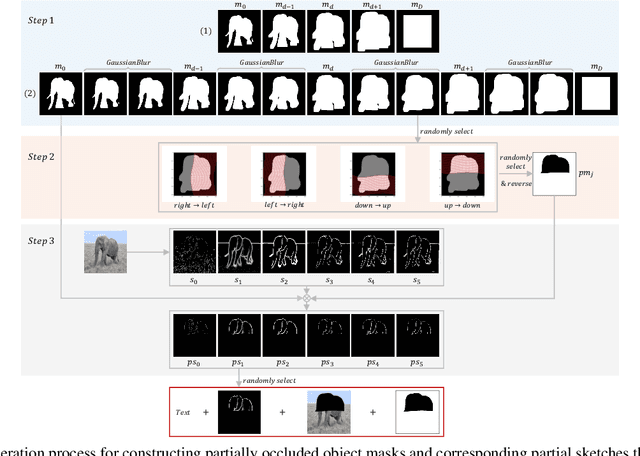
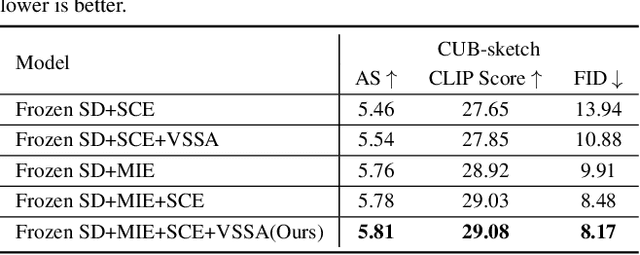
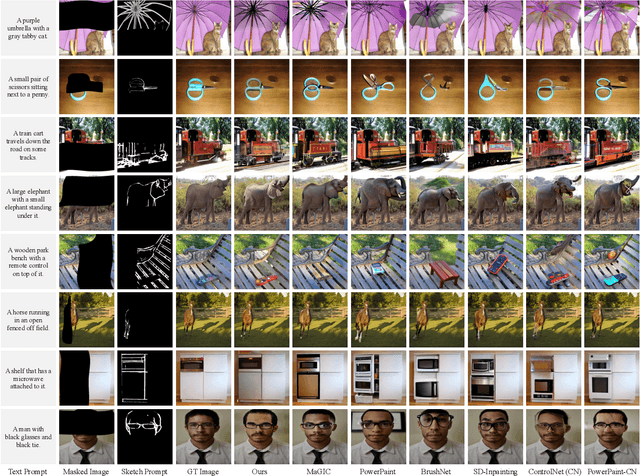
Diffusion models have become widely adopted in image completion tasks, with text prompts commonly employed to ensure semantic coherence by providing high-level guidance. However, a persistent challenge arises when an object is partially obscured in the damaged region, yet its remaining parts are still visible in the background. While text prompts offer semantic direction, they often fail to precisely recover fine-grained structural details, such as the object's overall posture, ensuring alignment with the visible object information in the background. This limitation stems from the inability of text prompts to provide pixel-level specificity. To address this, we propose supplementing text-based guidance with a novel visual aid: a casual sketch, which can be roughly drawn by anyone based on visible object parts. This sketch supplies critical structural cues, enabling the generative model to produce an object structure that seamlessly integrates with the existing background. We introduce the Visual Sketch Self-Aware (VSSA) model, which integrates the casual sketch into each iterative step of the diffusion process, offering distinct advantages for partially corrupted scenarios. By blending sketch-derived features with those of the corrupted image, and leveraging text prompt guidance, the VSSA assists the diffusion model in generating images that preserve both the intended object semantics and structural consistency across the restored objects and original regions. To support this research, we created two datasets, CUB-sketch and MSCOCO-sketch, each combining images, sketches, and text. Extensive qualitative and quantitative experiments demonstrate that our approach outperforms several state-of-the-art methods.
Facilitating Global Team Meetings Between Language-Based Subgroups: When and How Can Machine Translation Help?
Sep 07, 2022


Global teams frequently consist of language-based subgroups who put together complementary information to achieve common goals. Previous research outlines a two-step work communication flow in these teams. There are team meetings using a required common language (i.e., English); in preparation for those meetings, people have subgroup conversations in their native languages. Work communication at team meetings is often less effective than in subgroup conversations. In the current study, we investigate the idea of leveraging machine translation (MT) to facilitate global team meetings. We hypothesize that exchanging subgroup conversation logs before a team meeting offers contextual information that benefits teamwork at the meeting. MT can translate these logs, which enables comprehension at a low cost. To test our hypothesis, we conducted a between-subjects experiment where twenty quartets of participants performed a personnel selection task. Each quartet included two English native speakers (NS) and two non-native speakers (NNS) whose native language was Mandarin. All participants began the task with subgroup conversations in their native languages, then proceeded to team meetings in English. We manipulated the exchange of subgroup conversation logs prior to team meetings: with MT-mediated exchanges versus without. Analysis of participants' subjective experience, task performance, and depth of discussions as reflected through their conversational moves jointly indicates that team meeting quality improved when there were MT-mediated exchanges of subgroup conversation logs as opposed to no exchanges. We conclude with reflections on when and how MT could be applied to enhance global teamwork across a language barrier.