 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Redundancy in Diffusion Transformers (DiTs): A Systematic Study
Nov 18, 2024The increased model capacity of Diffusion Transformers (DiTs) and the demand for generating higher resolutions of images and videos have led to a significant rise in inference latency, impacting real-time performance adversely. While prior research has highlighted the presence of high similarity in activation values between adjacent diffusion steps (referred to as redundancy) and proposed various caching mechanisms to mitigate computational overhead, the exploration of redundancy in existing literature remains limited, with findings often not generalizable across different DiT models. This study aims to address this gap by conducting a comprehensive investigation into redundancy across a broad spectrum of mainstream DiT models. Our experimental analysis reveals substantial variations in the distribution of redundancy across diffusion steps among different DiT models. Interestingly, within a single model, the redundancy distribution remains stable regardless of variations in input prompts, step counts, or scheduling strategies. Given the lack of a consistent pattern across diverse models, caching strategies designed for a specific group of models may not easily transfer to others. To overcome this challenge, we introduce a tool for analyzing the redundancy of individual models, enabling subsequent research to develop tailored caching strategies for specific model architectures. The project is publicly available at https://github.com/xdit-project/DiTCacheAnalysis.
xDiT: an Inference Engine for Diffusion Transformers (DiTs) with Massive Parallelism
Nov 04, 2024



Diffusion models are pivotal for generating high-quality images and videos. Inspired by the success of OpenAI's Sora, the backbone of diffusion models is evolving from U-Net to Transformer, known as Diffusion Transformers (DiTs). However, generating high-quality content necessitates longer sequence lengths, exponentially increasing the computation required for the attention mechanism, and escalating DiTs inference latency. Parallel inference is essential for real-time DiTs deployments, but relying on a single parallel method is impractical due to poor scalability at large scales. This paper introduces xDiT, a comprehensive parallel inference engine for DiTs. After thoroughly investigating existing DiTs parallel approaches, xDiT chooses Sequence Parallel (SP) and PipeFusion, a novel Patch-level Pipeline Parallel method, as intra-image parallel strategies, alongside CFG parallel for inter-image parallelism. xDiT can flexibly combine these parallel approaches in a hybrid manner, offering a robust and scalable solution. Experimental results on two 8xL40 GPUs (PCIe) nodes interconnected by Ethernet and an 8xA100 (NVLink) node showcase xDiT's exceptional scalability across five state-of-the-art DiTs. Notably, we are the first to demonstrate DiTs scalability on Ethernet-connected GPU clusters. xDiT is available at https://github.com/xdit-project/xDiT.
MAC Revivo: Artificial Intelligence Paves the Way
Oct 21, 2024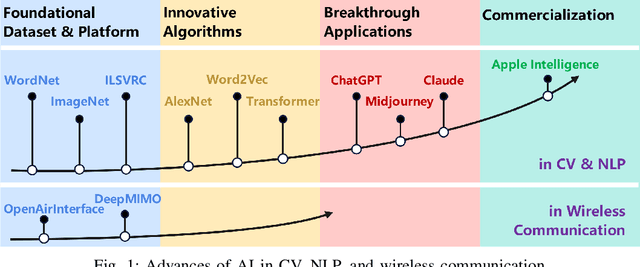
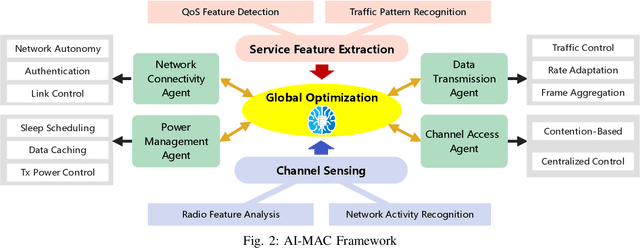
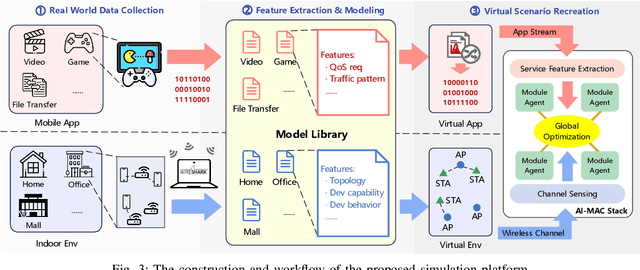
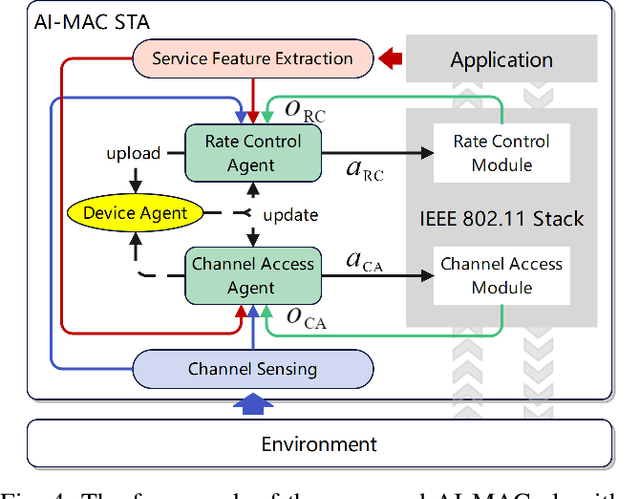
The vast adoption of Wi-Fi and/or Bluetooth capabilities in Internet of Things (IoT) devices, along with the rapid growth of deployed smart devices, has caused significant interference and congestion in the industrial, scientific, and medical (ISM) bands. Traditional Wi-Fi Medium Access Control (MAC) design faces significant challenges in managing increasingly complex wireless environments while ensuring network Quality of Service (QoS) performance. This paper explores the potential integration of advanced Artificial Intelligence (AI) methods into the design of Wi-Fi MAC protocols. We propose AI-MAC, an innovative approach that employs machine learning algorithms to dynamically adapt to changing network conditions, optimize channel access, mitigate interference, and ensure deterministic latency. By intelligently predicting and managing interference, AI-MAC aims to provide a robust solution for next generation of Wi-Fi networks, enabling seamless connectivity and enhanced QoS. Our experimental results demonstrate that AI-MAC significantly reduces both interference and latency, paving the way for more reliable and efficient wireless communications in the increasingly crowded ISM band.