 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Redundancy in Diffusion Transformers (DiTs): A Systematic Study
Nov 18, 2024The increased model capacity of Diffusion Transformers (DiTs) and the demand for generating higher resolutions of images and videos have led to a significant rise in inference latency, impacting real-time performance adversely. While prior research has highlighted the presence of high similarity in activation values between adjacent diffusion steps (referred to as redundancy) and proposed various caching mechanisms to mitigate computational overhead, the exploration of redundancy in existing literature remains limited, with findings often not generalizable across different DiT models. This study aims to address this gap by conducting a comprehensive investigation into redundancy across a broad spectrum of mainstream DiT models. Our experimental analysis reveals substantial variations in the distribution of redundancy across diffusion steps among different DiT models. Interestingly, within a single model, the redundancy distribution remains stable regardless of variations in input prompts, step counts, or scheduling strategies. Given the lack of a consistent pattern across diverse models, caching strategies designed for a specific group of models may not easily transfer to others. To overcome this challenge, we introduce a tool for analyzing the redundancy of individual models, enabling subsequent research to develop tailored caching strategies for specific model architectures. The project is publicly available at https://github.com/xdit-project/DiTCacheAnalysis.
xDiT: an Inference Engine for Diffusion Transformers (DiTs) with Massive Parallelism
Nov 04, 2024



Diffusion models are pivotal for generating high-quality images and videos. Inspired by the success of OpenAI's Sora, the backbone of diffusion models is evolving from U-Net to Transformer, known as Diffusion Transformers (DiTs). However, generating high-quality content necessitates longer sequence lengths, exponentially increasing the computation required for the attention mechanism, and escalating DiTs inference latency. Parallel inference is essential for real-time DiTs deployments, but relying on a single parallel method is impractical due to poor scalability at large scales. This paper introduces xDiT, a comprehensive parallel inference engine for DiTs. After thoroughly investigating existing DiTs parallel approaches, xDiT chooses Sequence Parallel (SP) and PipeFusion, a novel Patch-level Pipeline Parallel method, as intra-image parallel strategies, alongside CFG parallel for inter-image parallelism. xDiT can flexibly combine these parallel approaches in a hybrid manner, offering a robust and scalable solution. Experimental results on two 8xL40 GPUs (PCIe) nodes interconnected by Ethernet and an 8xA100 (NVLink) node showcase xDiT's exceptional scalability across five state-of-the-art DiTs. Notably, we are the first to demonstrate DiTs scalability on Ethernet-connected GPU clusters. xDiT is available at https://github.com/xdit-project/xDiT.
PipeFusion: Displaced Patch Pipeline Parallelism for Inference of Diffusion Transformer Models
May 23, 2024This paper introduces PipeFusion, a novel approach that harnesses multi-GPU parallelism to address the high computational and latency challenges of generating high-resolution images with diffusion transformers (DiT) models. PipeFusion splits images into patches and distributes the network layers across multiple devices. It employs a pipeline parallel manner to orchestrate communication and computations. By leveraging the high similarity between the input from adjacent diffusion steps, PipeFusion eliminates the waiting time in the pipeline by reusing the one-step stale feature maps to provide context for the current step. Our experiments demonstrate that it can generate higher image resolution where existing DiT parallel approaches meet OOM. PipeFusion significantly reduces the required communication bandwidth, enabling DiT inference to be hosted on GPUs connected via PCIe rather than the more costly NVLink infrastructure, which substantially lowers the overall operational expenses for serving DiT models. Our code is publicly available at https://github.com/PipeFusion/PipeFusion.
Exploring the Impact of In-Browser Deep Learning Inference on Quality of User Experience and Performance
Feb 08, 2024
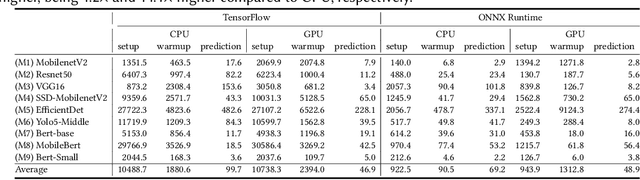

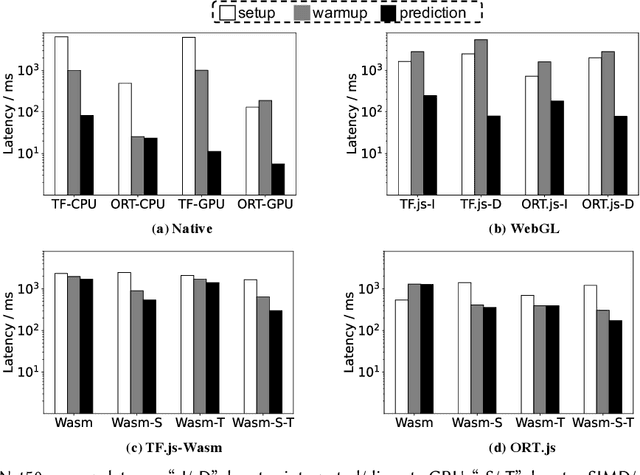
Deep Learning (DL) is increasingly being integrated into Web applications through a method known as "in-browser inference", where the DL processes occur directly within Web browsers. However, the actual performance of this method and its effect on user experience quality (QoE) is not well-understood. This gap in knowledge necessitates new forms of QoE measurement, going beyond traditional metrics such as page load time. To address this, we conducted the first extensive performance evaluation of in-browser inference. We introduced new metrics for this purpose: responsiveness, smoothness, and inference accuracy. Our thorough study included 9 widely-used DL models and tested them across 50 popular PC Web browsers. The findings show a significant latency issue with in-browser inference: it's on average 16.9 times slower on CPU and 4.9 times slower on GPU than native inference methods. Several factors contribute to this latency, including underused hardware instruction sets, inherent delays in the runtime environment, resource competition within the browser, and inefficiencies in software libraries and GPU abstractions. Moreover, in-browser inference demands a lot of memory, sometimes up to 334.6 times more than the size of the DL models themselves. This excessive memory usage is partly due to suboptimal memory management. Additionally, we noticed that in-browser inference increases the time it takes for graphical user interface (GUI) components to load in web browsers by a significant 67.2\%, which severely impacts the overall QoE for users of web applications that depend on this technology.
BiBench: Benchmarking and Analyzing Network Binarization
Jan 26, 2023
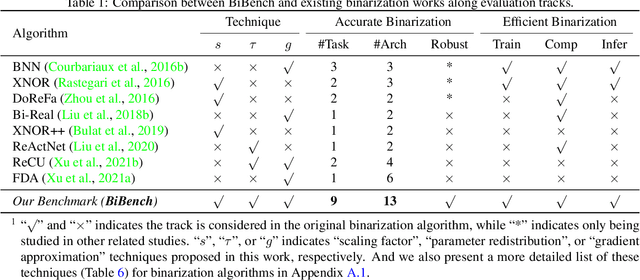
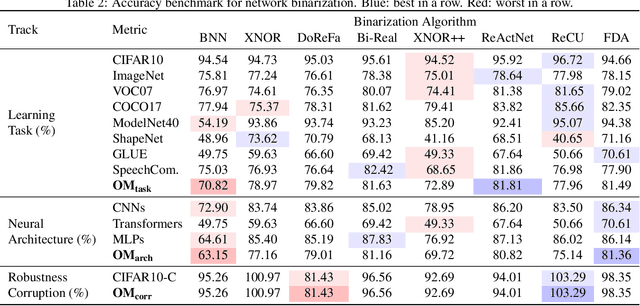

Network binarization emerges as one of the most promising compression approaches offering extraordinary computation and memory savings by minimizing the bit-width. However, recent research has shown that applying existing binarization algorithms to diverse tasks, architectures, and hardware in realistic scenarios is still not straightforward. Common challenges of binarization, such as accuracy degradation and efficiency limitation, suggest that its attributes are not fully understood. To close this gap, we present BiBench, a rigorously designed benchmark with in-depth analysis for network binarization. We first carefully scrutinize the requirements of binarization in the actual production and define evaluation tracks and metrics for a comprehensive and fair investigation. Then, we evaluate and analyze a series of milestone binarization algorithms that function at the operator level and with extensive influence. Our benchmark reveals that 1) the binarized operator has a crucial impact on the performance and deployability of binarized networks; 2) the accuracy of binarization varies significantly across different learning tasks and neural architectures; 3) binarization has demonstrated promising efficiency potential on edge devices despite the limited hardware support. The results and analysis also lead to a promising paradigm for accurate and efficient binarization. We believe that BiBench will contribute to the broader adoption of binarization and serve as a foundation for future research.
Informative Sample-Aware Proxy for Deep Metric Learning
Nov 18, 2022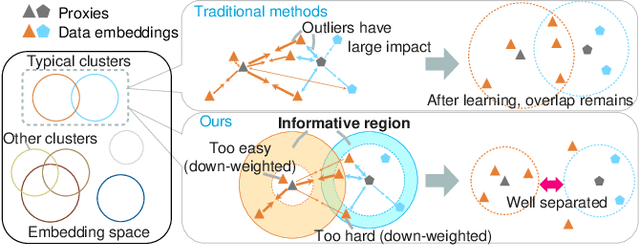
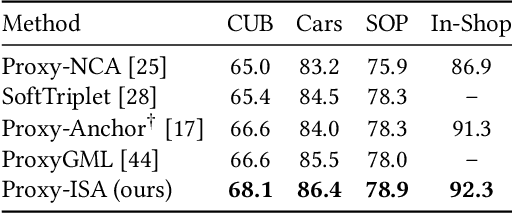

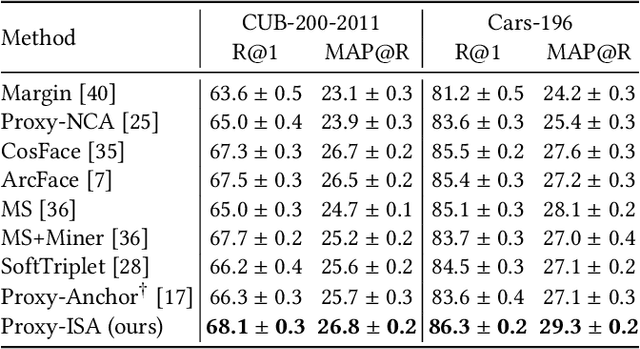
Among various supervised deep metric learning methods proxy-based approaches have achieved high retrieval accuracies. Proxies, which are class-representative points in an embedding space, receive updates based on proxy-sample similarities in a similar manner to sample representations. In existing methods, a relatively small number of samples can produce large gradient magnitudes (ie, hard samples), and a relatively large number of samples can produce small gradient magnitudes (ie, easy samples); these can play a major part in updates. Assuming that acquiring too much sensitivity to such extreme sets of samples would deteriorate the generalizability of a method, we propose a novel proxy-based method called Informative Sample-Aware Proxy (Proxy-ISA), which directly modifies a gradient weighting factor for each sample using a scheduled threshold function, so that the model is more sensitive to the informative samples. Extensive experiments on the CUB-200-2011, Cars-196, Stanford Online Products and In-shop Clothes Retrieval datasets demonstrate the superiority of Proxy-ISA compared with the state-of-the-art methods.
Diverse Sample Generation: Pushing the Limit of Data-free Quantization
Sep 03, 2021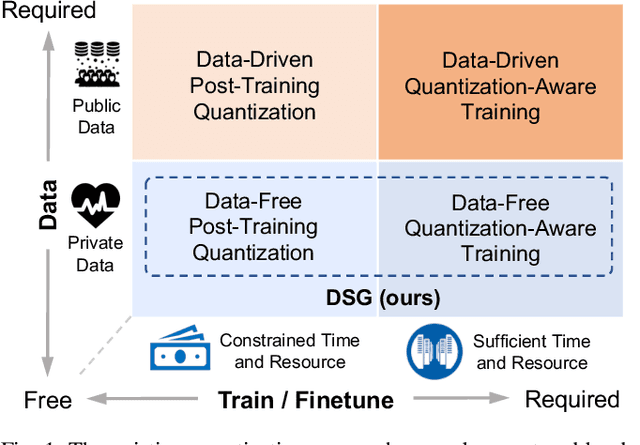
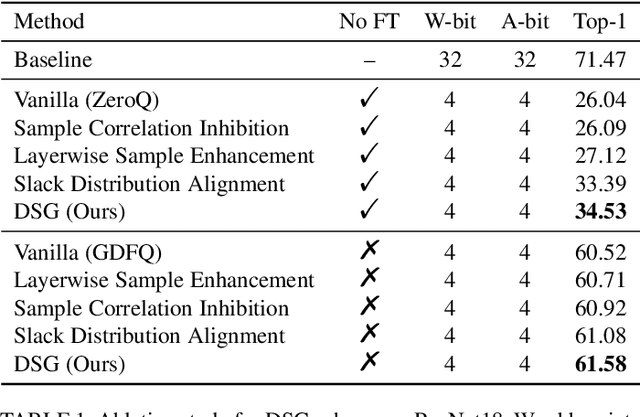
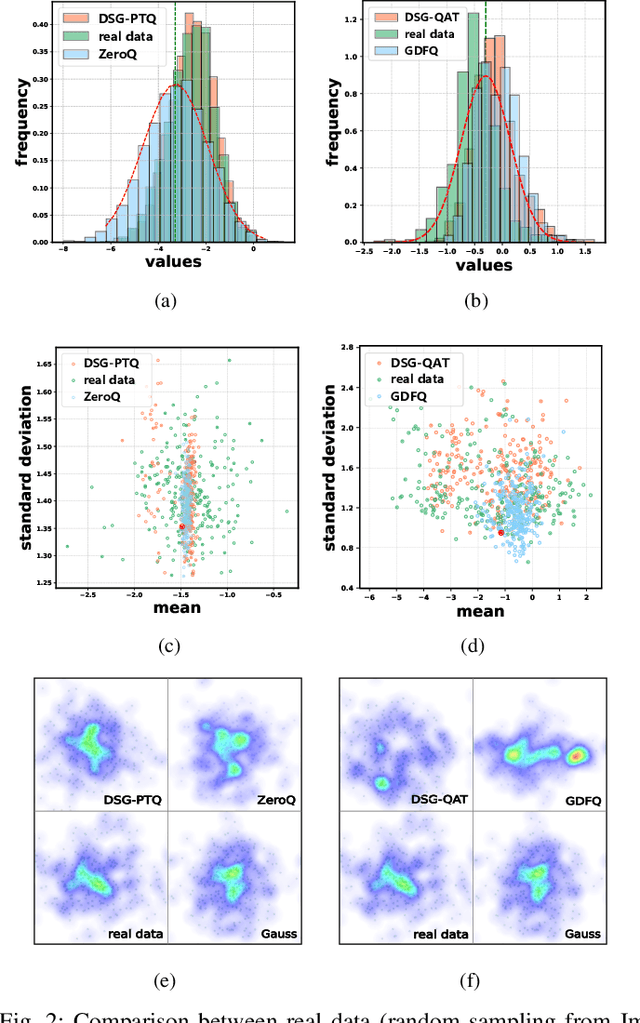
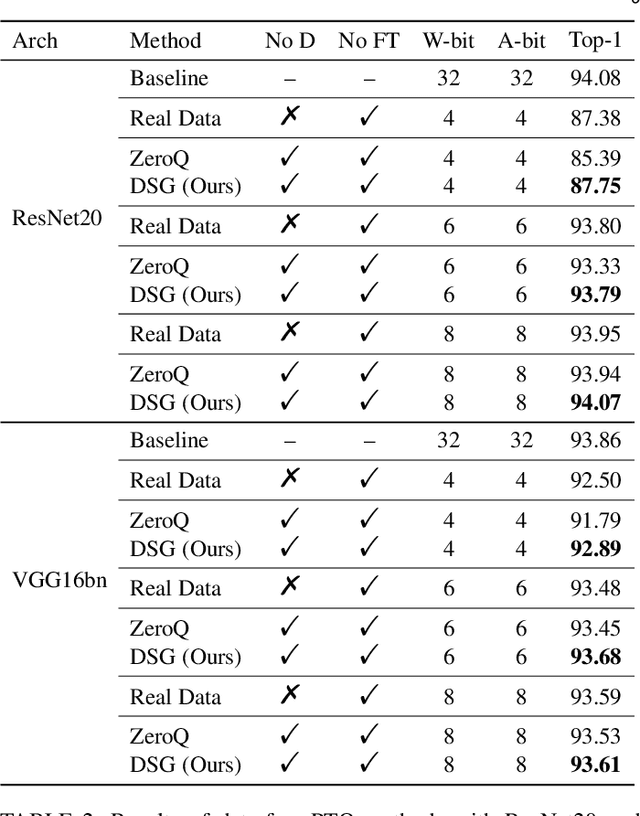
Recently, generative data-free quantization emerges as a practical approach that compresses the neural network to low bit-width without access to real data. It generates data to quantize the network by utilizing the batch normalization (BN) statistics of its full-precision counterpart. However, our study shows that in practice, the synthetic data completely constrained by BN statistics suffers severe homogenization at distribution and sample level, which causes serious accuracy degradation of the quantized network. This paper presents a generic Diverse Sample Generation (DSG) scheme for the generative data-free post-training quantization and quantization-aware training, to mitigate the detrimental homogenization. In our DSG, we first slack the statistics alignment for features in the BN layer to relax the distribution constraint. Then we strengthen the loss impact of the specific BN layer for different samples and inhibit the correlation among samples in the generation process, to diversify samples from the statistical and spatial perspective, respectively. Extensive experiments show that for large-scale image classification tasks, our DSG can consistently outperform existing data-free quantization methods on various neural architectures, especially under ultra-low bit-width (e.g., 22% gain under W4A4 setting). Moreover, data diversifying caused by our DSG brings a general gain in various quantization methods, demonstrating diversity is an important property of high-quality synthetic data for data-free quantization.