 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Impact of In-Browser Deep Learning Inference on Quality of User Experience and Performance
Paper and Code

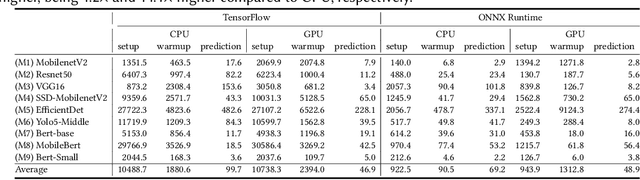

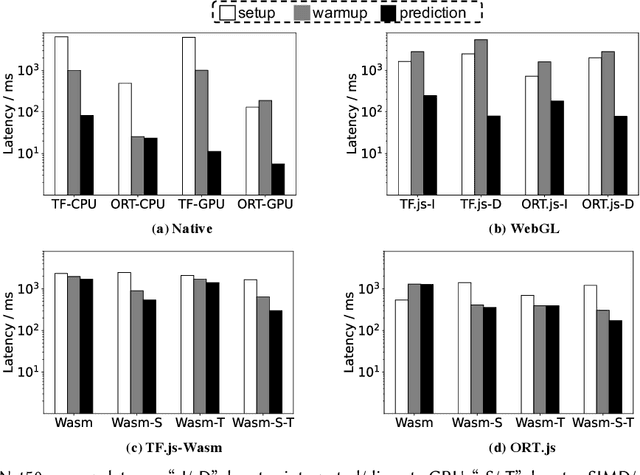
Deep Learning (DL) is increasingly being integrated into Web applications through a method known as "in-browser inference", where the DL processes occur directly within Web browsers. However, the actual performance of this method and its effect on user experience quality (QoE) is not well-understood. This gap in knowledge necessitates new forms of QoE measurement, going beyond traditional metrics such as page load time. To address this, we conducted the first extensive performance evaluation of in-browser inference. We introduced new metrics for this purpose: responsiveness, smoothness, and inference accuracy. Our thorough study included 9 widely-used DL models and tested them across 50 popular PC Web browsers. The findings show a significant latency issue with in-browser inference: it's on average 16.9 times slower on CPU and 4.9 times slower on GPU than native inference methods. Several factors contribute to this latency, including underused hardware instruction sets, inherent delays in the runtime environment, resource competition within the browser, and inefficiencies in software libraries and GPU abstractions. Moreover, in-browser inference demands a lot of memory, sometimes up to 334.6 times more than the size of the DL models themselves. This excessive memory usage is partly due to suboptimal memory management. Additionally, we noticed that in-browser inference increases the time it takes for graphical user interface (GUI) components to load in web browsers by a significant 67.2\%, which severely impacts the overall QoE for users of web applications that depend on this technology.