 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Vision-and-Language Reasoning via Spatial Relations Modeling
Nov 09, 2023Visual commonsense reasoning (VCR) is a challenging multi-modal task, which requires high-level cognition and commonsense reasoning ability about the real world. In recent years, large-scale pre-training approaches have been developed and promoted the state-of-the-art performance of VCR. However, the existing approaches almost employ the BERT-like objectives to learn multi-modal representations. These objectives motivated from the text-domain are insufficient for the excavation on the complex scenario of visual modality. Most importantly, the spatial distribution of the visual objects is basically neglected. To address the above issue, we propose to construct the spatial relation graph based on the given visual scenario. Further, we design two pre-training tasks named object position regression (OPR) and spatial relation classification (SRC) to learn to reconstruct the spatial relation graph respectively. Quantitative analysis suggests that the proposed method can guide the representations to maintain more spatial context and facilitate the attention on the essential visual regions for reasoning. We achieve the state-of-the-art results on VCR and two other vision-and-language reasoning tasks VQA, and NLVR.
NL2INTERFACE: Interactive Visualization Interface Generation from Natural Language Queries
Sep 24, 2022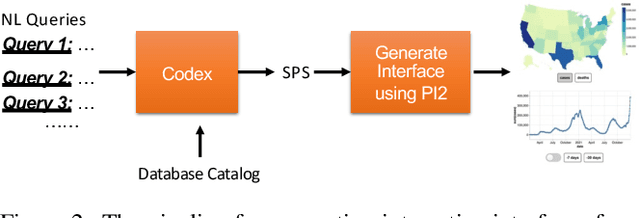
We develop NL2INTERFACE to explore the potential of generating usable interactive multi-visualization interfaces from natural language queries. With NL2INTERFACE, users can directly write natural language queries to automatically generate a fully interactive multi-visualization interface without any extra effort of learning a tool or programming language. Further, users can interact with the interfaces to easily transform the data and quickly see the results in the visualizations.
HiT: Hierarchical Transformer with Momentum Contrast for Video-Text Retrieval
Mar 28, 2021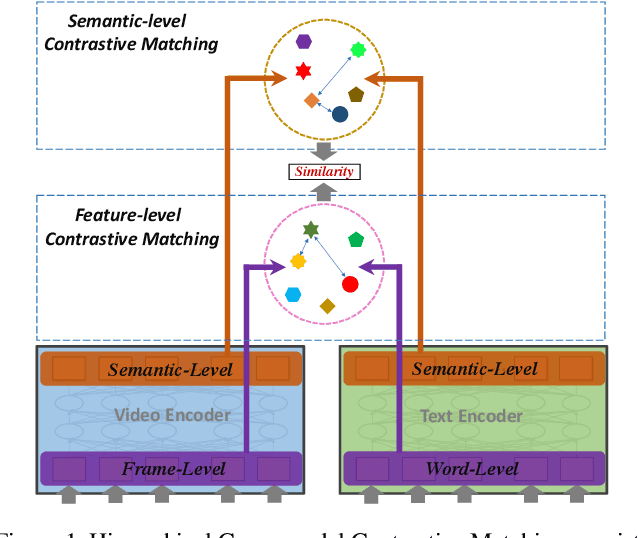
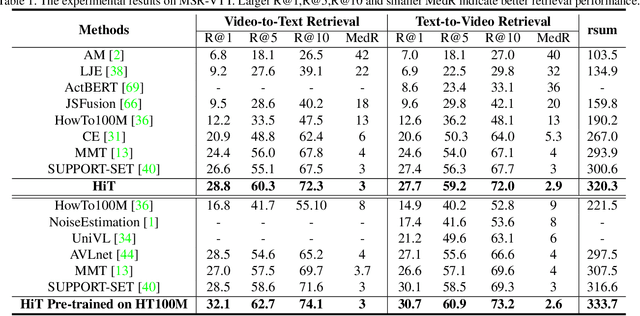
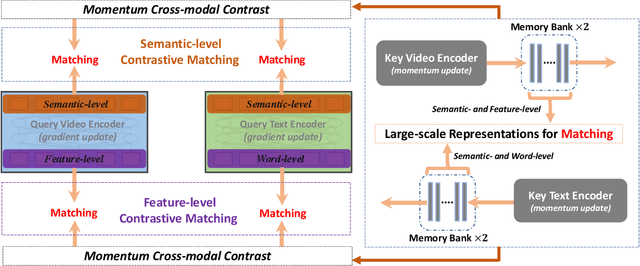
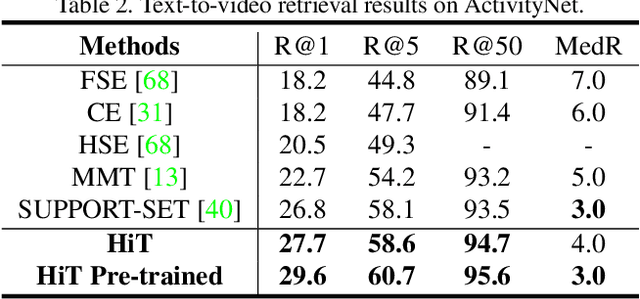
Video-Text Retrieval has been a hot research topic with the explosion of multimedia data on the Internet. Transformer for video-text learning has attracted increasing attention due to the promising performance.However, existing cross-modal transformer approaches typically suffer from two major limitations: 1) Limited exploitation of the transformer architecture where different layers have different feature characteristics. 2) End-to-end training mechanism limits negative interactions among samples in a mini-batch. In this paper, we propose a novel approach named Hierarchical Transformer (HiT) for video-text retrieval. HiT performs hierarchical cross-modal contrastive matching in feature-level and semantic-level to achieve multi-view and comprehensive retrieval results. Moreover, inspired by MoCo, we propose Momentum Cross-modal Contrast for cross-modal learning to enable large-scale negative interactions on-the-fly, which contributes to the generation of more precise and discriminative representations. Experimental results on three major Video-Text Retrieval benchmark datasets demonstrate the advantages of our methods.
Monte Carlo Tree Search for Generating Interactive Data Analysis Interfaces
Jan 07, 2020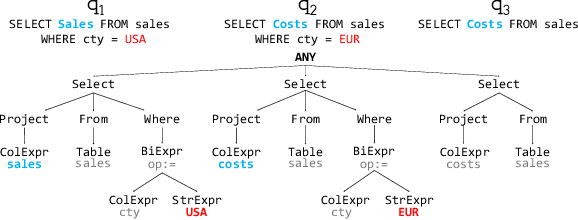


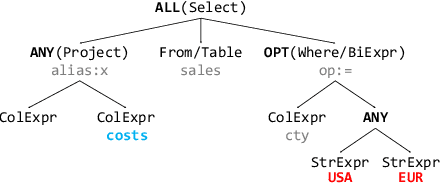
Interactive tools like user interfaces help democratize data access for end-users by hiding underlying programming details and exposing the necessary widget interface to users. Since customized interfaces are costly to build, automated interface generation is desirable. SQL is the dominant way to analyze data and there already exists logs to analyze data. Previous work proposed a syntactic approach to analyze structural changes in SQL query logs and automatically generates a set of widgets to express the changes. However, they do not consider layout usability and the sequential order of queries in the log. We propose to adopt Monte Carlo Tree Search(MCTS) to search for the optimal interface that accounts for hierarchical layout as well as the usability in terms of how easy to express the query log.