 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArming Data Agents with Tribal Knowledge
Feb 13, 2026Natural language to SQL (NL2SQL) translation enables non-expert users to query relational databases through natural language. Recently, NL2SQL agents, powered by the reasoning capabilities of Large Language Models (LLMs), have significantly advanced NL2SQL translation. Nonetheless, NL2SQL agents still make mistakes when faced with large-scale real-world databases because they lack knowledge of how to correctly leverage the underlying data (e.g., knowledge about the intent of each column) and form misconceptions about the data when querying it, leading to errors. Prior work has studied generating facts about the database to provide more context to NL2SQL agents, but such approaches simply restate database contents without addressing the agent's misconceptions. In this paper, we propose Tk-Boost, a bolt-on framework for augmenting any NL2SQL agent with tribal knowledge: knowledge that corrects the agent's misconceptions in querying the database accumulated through experience using the database. To accumulate experience, Tk-Boost first asks the NL2SQL agent to answer a few queries on the database, identifies the agent's misconceptions by analyzing its mistakes on the database, and generates tribal knowledge to address them. To enable accurate retrieval, Tk-Boost indexes this knowledge with applicability conditions that specify the query features for which the knowledge is useful. When answering new queries, Tk-Boost uses this knowledge to provide feedback to the NL2SQL agent, resolving the agent's misconceptions during SQL generation, and thus improving the agent's accuracy. Extensive experiments across the BIRD and Spider 2.0 benchmarks with various NL2SQL agents shows Tk-Boost improves NL2SQL agents accuracy by up to 16.9% on Spider 2.0 and 13.7% on BIRD
RAG Without the Lag: Interactive Debugging for Retrieval-Augmented Generation Pipelines
Apr 18, 2025Retrieval-augmented generation (RAG) pipelines have become the de-facto approach for building AI assistants with access to external, domain-specific knowledge. Given a user query, RAG pipelines typically first retrieve (R) relevant information from external sources, before invoking a Large Language Model (LLM), augmented (A) with this information, to generate (G) responses. Modern RAG pipelines frequently chain multiple retrieval and generation components, in any order. However, developing effective RAG pipelines is challenging because retrieval and generation components are intertwined, making it hard to identify which component(s) cause errors in the eventual output. The parameters with the greatest impact on output quality often require hours of pre-processing after each change, creating prohibitively slow feedback cycles. To address these challenges, we present RAGGY, a developer tool that combines a Python library of composable RAG primitives with an interactive interface for real-time debugging. We contribute the design and implementation of RAGGY, insights into expert debugging patterns through a qualitative study with 12 engineers, and design implications for future RAG tools that better align with developers' natural workflows.
LLM-Powered Proactive Data Systems
Feb 18, 2025With the power of LLMs, we now have the ability to query data that was previously impossible to query, including text, images, and video. However, despite this enormous potential, most present-day data systems that leverage LLMs are reactive, reflecting our community's desire to map LLMs to known abstractions. Most data systems treat LLMs as an opaque black box that operates on user inputs and data as is, optimizing them much like any other approximate, expensive UDFs, in conjunction with other relational operators. Such data systems do as they are told, but fail to understand and leverage what the LLM is being asked to do (i.e. the underlying operations, which may be error-prone), the data the LLM is operating on (e.g., long, complex documents), or what the user really needs. They don't take advantage of the characteristics of the operations and/or the data at hand, or ensure correctness of results when there are imprecisions and ambiguities. We argue that data systems instead need to be proactive: they need to be given more agency -- armed with the power of LLMs -- to understand and rework the user inputs and the data and to make decisions on how the operations and the data should be represented and processed. By allowing the data system to parse, rewrite, and decompose user inputs and data, or to interact with the user in ways that go beyond the standard single-shot query-result paradigm, the data system is able to address user needs more efficiently and effectively. These new capabilities lead to a rich design space where the data system takes more initiative: they are empowered to perform optimization based on the transformation operations, data characteristics, and user intent. We discuss various successful examples of how this framework has been and can be applied in real-world tasks, and present future directions for this ambitious research agenda.
Towards Establishing Guaranteed Error for Learned Database Operations
Nov 09, 2024
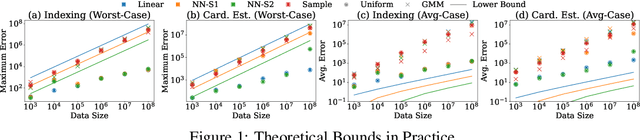
Machine learning models have demonstrated substantial performance enhancements over non-learned alternatives in various fundamental data management operations, including indexing (locating items in an array), cardinality estimation (estimating the number of matching records in a database), and range-sum estimation (estimating aggregate attribute values for query-matched records). However, real-world systems frequently favor less efficient non-learned methods due to their ability to offer (worst-case) error guarantees - an aspect where learned approaches often fall short. The primary objective of these guarantees is to ensure system reliability, ensuring that the chosen approach consistently delivers the desired level of accuracy across all databases. In this paper, we embark on the first theoretical study of such guarantees for learned methods, presenting the necessary conditions for such guarantees to hold when using machine learning to perform indexing, cardinality estimation and range-sum estimation. Specifically, we present the first known lower bounds on the model size required to achieve the desired accuracy for these three key database operations. Our results bound the required model size for given average and worst-case errors in performing database operations, serving as the first theoretical guidelines governing how model size must change based on data size to be able to guarantee an accuracy level. More broadly, our established guarantees pave the way for the broader adoption and integration of learned models into real-world systems.
Theoretical Analysis of Learned Database Operations under Distribution Shift through Distribution Learnability
Nov 09, 2024Use of machine learning to perform database operations, such as indexing, cardinality estimation, and sorting, is shown to provide substantial performance benefits. However, when datasets change and data distribution shifts, empirical results also show performance degradation for learned models, possibly to worse than non-learned alternatives. This, together with a lack of theoretical understanding of learned methods undermines their practical applicability, since there are no guarantees on how well the models will perform after deployment. In this paper, we present the first known theoretical characterization of the performance of learned models in dynamic datasets, for the aforementioned operations. Our results show novel theoretical characteristics achievable by learned models and provide bounds on the performance of the models that characterize their advantages over non-learned methods, showing why and when learned models can outperform the alternatives. Our analysis develops the distribution learnability framework and novel theoretical tools which build the foundation for the analysis of learned database operations in the future.
NUDGE: Lightweight Non-Parametric Fine-Tuning of Embeddings for Retrieval
Sep 04, 2024$k$-Nearest Neighbor search on dense vector embeddings ($k$-NN retrieval) from pre-trained embedding models is the predominant retrieval method for text and images, as well as Retrieval-Augmented Generation (RAG) pipelines. In practice, application developers often fine-tune the embeddings to improve their accuracy on the dataset and query workload in hand. Existing approaches either fine-tune the pre-trained model itself or, more efficiently, but at the cost of accuracy, train adaptor models to transform the output of the pre-trained model. We present NUDGE, a family of novel non-parametric embedding fine-tuning approaches that are significantly more accurate and efficient than both sets of existing approaches. NUDGE directly modifies the embeddings of data records to maximize the accuracy of $k$-NN retrieval. We present a thorough theoretical and experimental study of NUDGE's non-parametric approach. We show that even though the underlying problem is NP-Hard, constrained variations can be solved efficiently. These constraints additionally ensure that the changes to the embeddings are modest, avoiding large distortions to the semantics learned during pre-training. In experiments across five pre-trained models and nine standard text and image retrieval datasets, NUDGE runs in minutes and often improves NDCG@10 by more than 10% over existing fine-tuning methods. On average, NUDGE provides 3.3x and 4.3x higher increase in accuracy and runs 200x and 3x faster, respectively, over fine-tuning the pre-trained model and training adaptors.
BiasBuster: a Neural Approach for Accurate Estimation of Population Statistics using Biased Location Data
Feb 17, 2024



While extremely useful (e.g., for COVID-19 forecasting and policy-making, urban mobility analysis and marketing, and obtaining business insights), location data collected from mobile devices often contain data from a biased population subset, with some communities over or underrepresented in the collected datasets. As a result, aggregate statistics calculated from such datasets (as is done by various companies including Safegraph, Google, and Facebook), while ignoring the bias, leads to an inaccurate representation of population statistics. Such statistics will not only be generally inaccurate, but the error will disproportionately impact different population subgroups (e.g., because they ignore the underrepresented communities). This has dire consequences, as these datasets are used for sensitive decision-making such as COVID-19 policymaking. This paper tackles the problem of providing accurate population statistics using such biased datasets. We show that statistical debiasing, although in some cases useful, often fails to improve accuracy. We then propose BiasBuster, a neural network approach that utilizes the correlations between population statistics and location characteristics to provide accurate estimates of population statistics. Extensive experiments on real-world data show that BiasBuster improves accuracy by up to 2 times in general and up to 3 times for underrepresented populations.
On Distribution Dependent Sub-Logarithmic Query Time of Learned Indexing
Jun 19, 2023



A fundamental problem in data management is to find the elements in an array that match a query. Recently, learned indexes are being extensively used to solve this problem, where they learn a model to predict the location of the items in the array. They are empirically shown to outperform non-learned methods (e.g., B-trees or binary search that answer queries in $O(\log n)$ time) by orders of magnitude. However, success of learned indexes has not been theoretically justified. Only existing attempt shows the same query time of $O(\log n)$, but with a constant factor improvement in space complexity over non-learned methods, under some assumptions on data distribution. In this paper, we significantly strengthen this result, showing that under mild assumptions on data distribution, and the same space complexity as non-learned methods, learned indexes can answer queries in $O(\log\log n)$ expected query time. We also show that allowing for slightly larger but still near-linear space overhead, a learned index can achieve $O(1)$ expected query time. Our results theoretically prove learned indexes are orders of magnitude faster than non-learned methods, theoretically grounding their empirical success.
Towards Accurate Spatiotemporal COVID-19 Risk Scores using High Resolution Real-World Mobility Data
Dec 14, 2020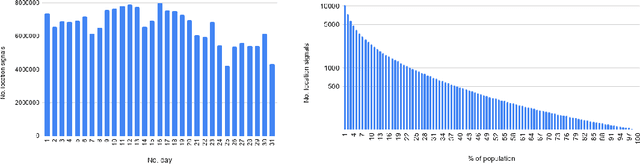
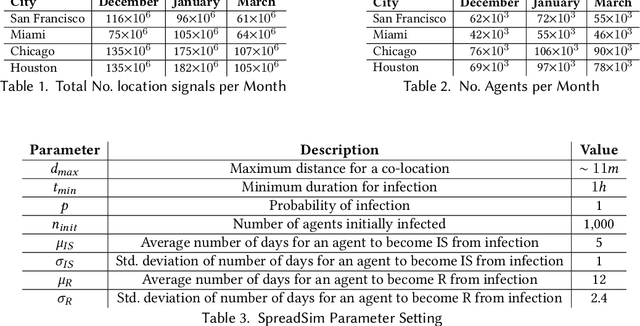
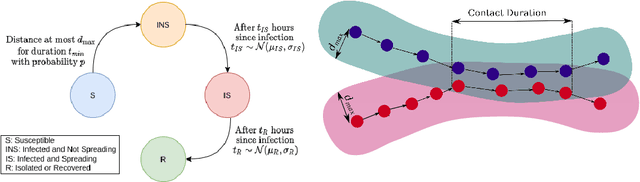

As countries look towards re-opening of economic activities amidst the ongoing COVID-19 pandemic, ensuring public health has been challenging. While contact tracing only aims to track past activities of infected users, one path to safe reopening is to develop reliable spatiotemporal risk scores to indicate the propensity of the disease. Existing works which aim to develop risk scores either rely on compartmental model-based reproduction numbers (which assume uniform population mixing) or develop coarse-grain spatial scores based on reproduction number (R0) and macro-level density-based mobility statistics. Instead, in this paper, we develop a Hawkes process-based technique to assign relatively fine-grain spatial and temporal risk scores by leveraging high-resolution mobility data based on cell-phone originated location signals. While COVID-19 risk scores also depend on a number of factors specific to an individual, including demography and existing medical conditions, the primary mode of disease transmission is via physical proximity and contact. Therefore, we focus on developing risk scores based on location density and mobility behaviour. We demonstrate the efficacy of the developed risk scores via simulation based on real-world mobility data. Our results show that fine-grain spatiotemporal risk scores based on high-resolution mobility data can provide useful insights and facilitate safe re-opening.
Finding Average Regret Ratio Minimizing Set in Database
Oct 18, 2018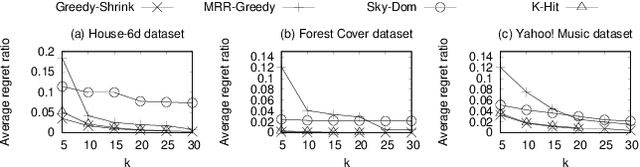


Selecting a certain number of data points (or records) from a database which "best" satisfy users' expectations is a very prevalent problem with many applications. One application is a hotel booking website showing a certain number of hotels on a single page. However, this problem is very challenging since the selected points should "collectively" satisfy the expectation of all users. Showing a certain number of data points to a single user could decrease the satisfaction of a user because the user may not be able to see his/her favorite point which could be found in the original database. In this paper, we would like to find a set of k points such that on average, the satisfaction (ratio) of a user is maximized. This problem takes into account the probability distribution of the users and considers the satisfaction (ratio) of all users, which is more reasonable in practice, compared with the existing studies that only consider the worst-case satisfaction (ratio) of the users, which may not reflect the whole population and is not useful in some applications. Motivated by this, in this paper, we propose algorithms for this problem. Finally, we conducted experiments to show the effectiveness and the efficiency of the algorithms.