 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Efficiency Gap in Byte Modeling
May 13, 2026Modern language models have historically relied on two dominant design choices: subword tokenization and autoregressive (AR) ordering. These design decisions bake in priors that dictate a model's learning. Recently, two alternative paradigms have challenged this: byte-level modeling, which bypasses static statistically-derived token vocabularies, and masked diffusion modeling (MDM), which conducts parallel, non-sequential generation. Their intersection represents a fully end-to-end modality-agnostic generative prototype; however, removing these structural priors incurs a significant computational cost. In this work, we investigate this cost through a compute-matched scaling study. Our results reveal that the performance penalty of byte modeling is not uniform; across scale, the scaling overhead of byte modeling is worse for MDM than for AR. We hypothesize that this disparity stems from context fragility: while AR's stable causal history allows models to naturally rediscover subword patterns, the MDM objective destroys the local contiguity required to efficiently resolve semantics from raw bytes. Our findings from controlled permutation experiments suggest that future modality-agnostic designs must incorporate alternative structural biases to maintain viable scaling trajectories in the byte regime.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
TreeScope: An Agricultural Robotics Dataset for LiDAR-Based Mapping of Trees in Forests and Orchards
Oct 03, 2023

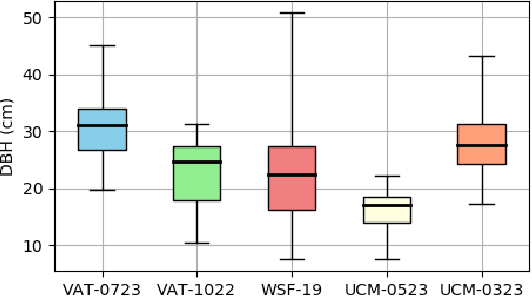

Data collection for forestry, timber, and agriculture currently relies on manual techniques which are labor-intensive and time-consuming. We seek to demonstrate that robotics offers improvements over these techniques and accelerate agricultural research, beginning with semantic segmentation and diameter estimation of trees in forests and orchards. We present TreeScope v1.0, the first robotics dataset for precision agriculture and forestry addressing the counting and mapping of trees in forestry and orchards. TreeScope provides LiDAR data from agricultural environments collected with robotics platforms, such as UAV and mobile robot platforms carried by vehicles and human operators. In the first release of this dataset, we provide ground-truth data with over 1,800 manually annotated semantic labels for tree stems and field-measured tree diameters. We share benchmark scripts for these tasks that researchers may use to evaluate the accuracy of their algorithms. Finally, we run our open-source diameter estimation and off-the-shelf semantic segmentation algorithms and share our baseline results.
Content-based Music Similarity with Triplet Networks
Aug 11, 2020
We explore the feasibility of using triplet neural networks to embed songs based on content-based music similarity. Our network is trained using triplets of songs such that two songs by the same artist are embedded closer to one another than to a third song by a different artist. We compare two models that are trained using different ways of picking this third song: at random vs. based on shared genre labels. Our experiments are conducted using songs from the Free Music Archive and use standard audio features. The initial results show that shallow Siamese networks can be used to embed music for a simple artist retrieval task.