 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Retrieval-Augmented Language Model Serving with Speculation
Jan 25, 2024Retrieval-augmented language models (RaLM) have demonstrated the potential to solve knowledge-intensive natural language processing (NLP) tasks by combining a non-parametric knowledge base with a parametric language model. Instead of fine-tuning a fully parametric model, RaLM excels at its low-cost adaptation to the latest data and better source attribution mechanisms. Among various RaLM approaches, iterative RaLM delivers a better generation quality due to a more frequent interaction between the retriever and the language model. Despite the benefits, iterative RaLM usually encounters high overheads due to the frequent retrieval step. To this end, we propose RaLMSpec, a speculation-inspired framework that provides generic speed-up over iterative RaLM while preserving the same model outputs through speculative retrieval and batched verification. By further incorporating prefetching, optimal speculation stride scheduler, and asynchronous verification, RaLMSpec can automatically exploit the acceleration potential to the fullest. For naive iterative RaLM serving, extensive evaluations over three language models on four downstream QA datasets demonstrate that RaLMSpec can achieve a speed-up ratio of 1.75-2.39x, 1.04-1.39x, and 1.31-1.77x when the retriever is an exact dense retriever, approximate dense retriever, and sparse retriever respectively compared with the baseline. For KNN-LM serving, RaLMSpec can achieve a speed-up ratio up to 7.59x and 2.45x when the retriever is an exact dense retriever and approximate dense retriever, respectively, compared with the baseline.
A Tensor SVD-based Classification Algorithm Applied to fMRI Data
Oct 31, 2021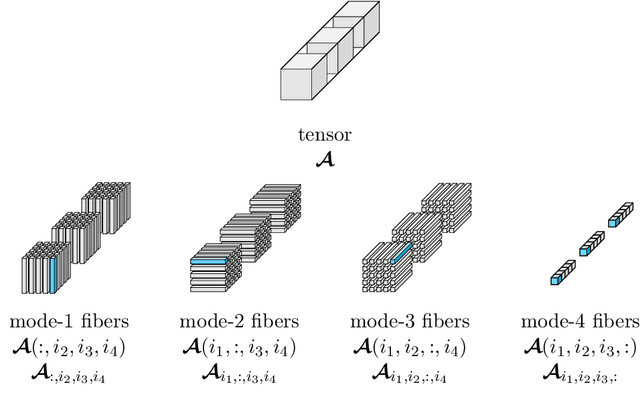
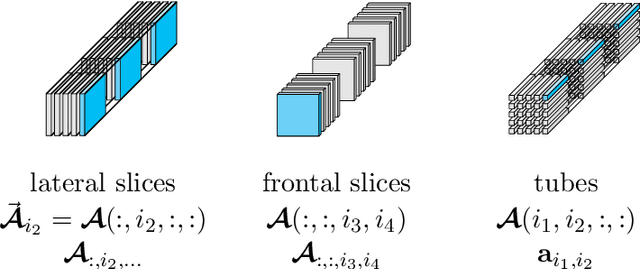
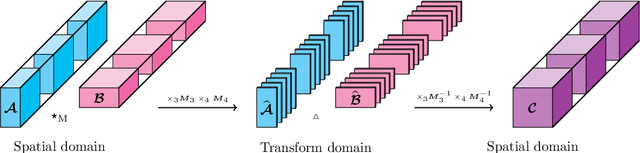
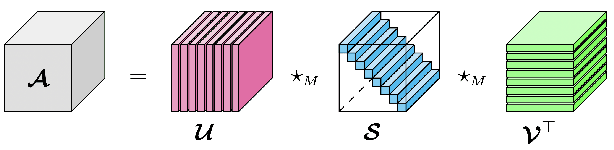
To analyze the abundance of multidimensional data, tensor-based frameworks have been developed. Traditionally, the matrix singular value decomposition (SVD) is used to extract the most dominant features from a matrix containing the vectorized data. While the SVD is highly useful for data that can be appropriately represented as a matrix, this step of vectorization causes us to lose the high-dimensional relationships intrinsic to the data. To facilitate efficient multidimensional feature extraction, we utilize a projection-based classification algorithm using the t-SVDM, a tensor analog of the matrix SVD. Our work extends the t-SVDM framework and the classification algorithm, both initially proposed for tensors of order 3, to any number of dimensions. We then apply this algorithm to a classification task using the StarPlus fMRI dataset. Our numerical experiments demonstrate that there exists a superior tensor-based approach to fMRI classification than the best possible equivalent matrix-based approach. Our results illustrate the advantages of our chosen tensor framework, provide insight into beneficial choices of parameters, and could be further developed for classification of more complex imaging data. We provide our Python implementation at https://github.com/elizabethnewman/tensor-fmri.