 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically Embedded Planning Problems: New Challenges for Reinforcement Learning
Sep 11, 2020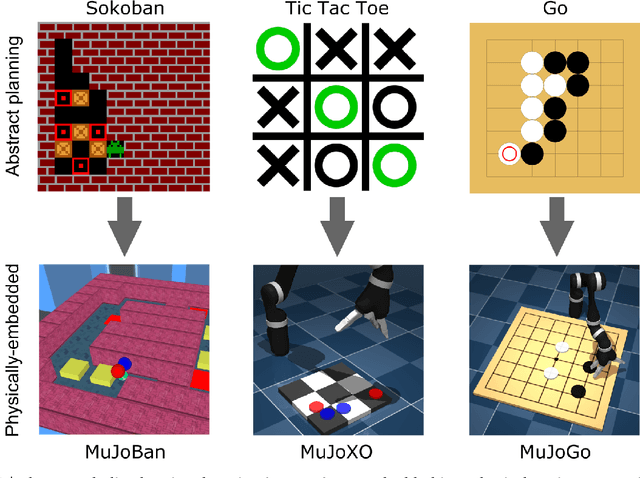


Recent work in deep reinforcement learning (RL) has produced algorithms capable of mastering challenging games such as Go, chess, or shogi. In these works the RL agent directly observes the natural state of the game and controls that state directly with its actions. However, when humans play such games, they do not just reason about the moves but also interact with their physical environment. They understand the state of the game by looking at the physical board in front of them and modify it by manipulating pieces using touch and fine-grained motor control. Mastering complicated physical systems with abstract goals is a central challenge for artificial intelligence, but it remains out of reach for existing RL algorithms. To encourage progress towards this goal we introduce a set of physically embedded planning problems and make them publicly available. We embed challenging symbolic tasks (Sokoban, tic-tac-toe, and Go) in a physics engine to produce a set of tasks that require perception, reasoning, and motor control over long time horizons. Although existing RL algorithms can tackle the symbolic versions of these tasks, we find that they struggle to master even the simplest of their physically embedded counterparts. As a first step towards characterizing the space of solution to these tasks, we introduce a strong baseline that uses a pre-trained expert game player to provide hints in the abstract space to an RL agent's policy while training it on the full sensorimotor control task. The resulting agent solves many of the tasks, underlining the need for methods that bridge the gap between abstract planning and embodied control.
Successor Features for Transfer in Reinforcement Learning
Apr 12, 2018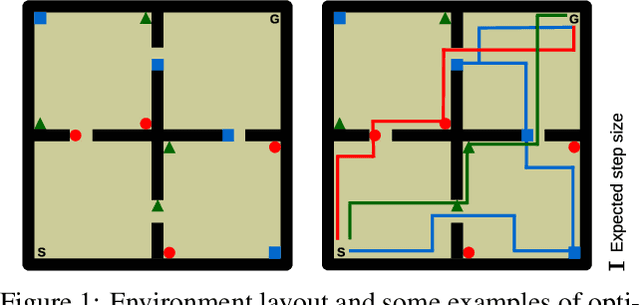
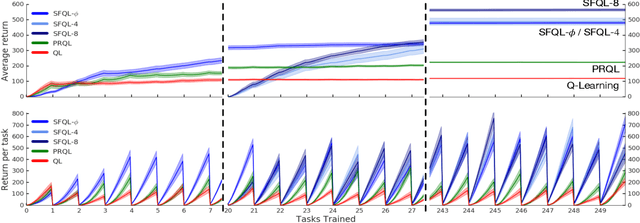
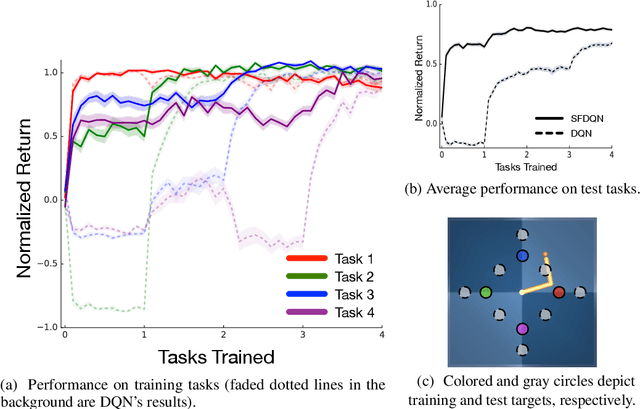
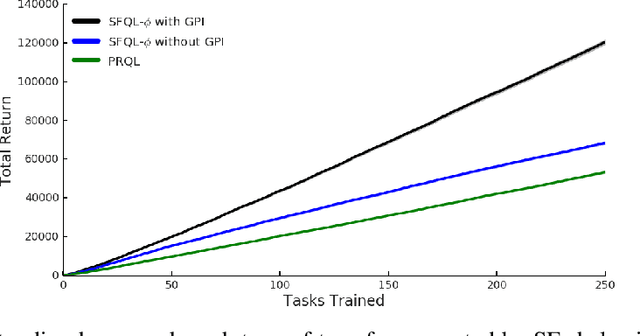
Transfer in reinforcement learning refers to the notion that generalization should occur not only within a task but also across tasks. We propose a transfer framework for the scenario where the reward function changes between tasks but the environment's dynamics remain the same. Our approach rests on two key ideas: "successor features", a value function representation that decouples the dynamics of the environment from the rewards, and "generalized policy improvement", a generalization of dynamic programming's policy improvement operation that considers a set of policies rather than a single one. Put together, the two ideas lead to an approach that integrates seamlessly within the reinforcement learning framework and allows the free exchange of information across tasks. The proposed method also provides performance guarantees for the transferred policy even before any learning has taken place. We derive two theorems that set our approach in firm theoretical ground and present experiments that show that it successfully promotes transfer in practice, significantly outperforming alternative methods in a sequence of navigation tasks and in the control of a simulated robotic arm.
Continuous control with deep reinforcement learning
Feb 29, 2016
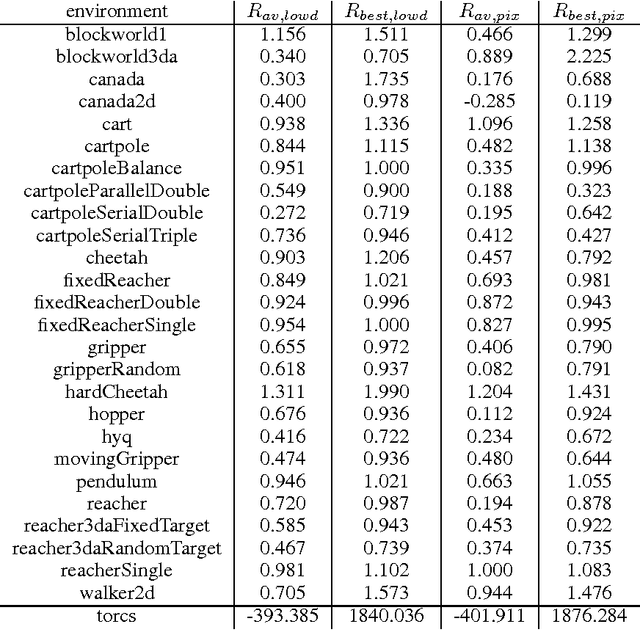
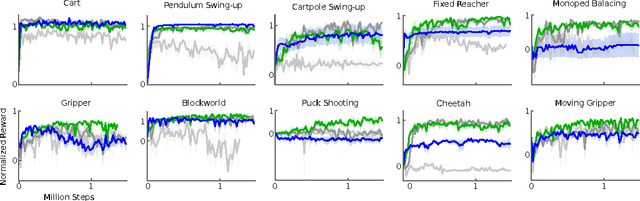
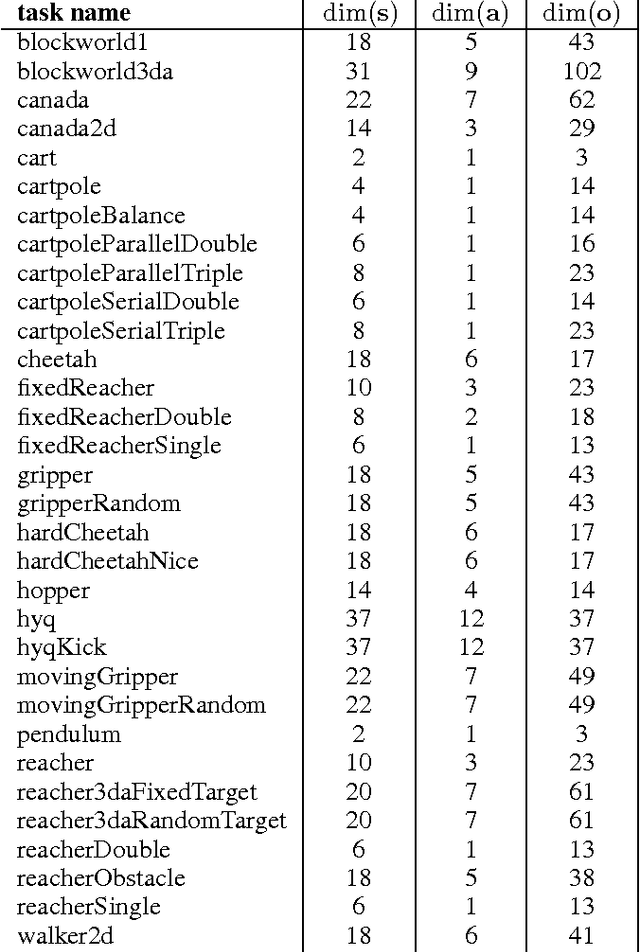
We adapt the ideas underlying the success of Deep Q-Learning to the continuous action domain. We present an actor-critic, model-free algorithm based on the deterministic policy gradient that can operate over continuous action spaces. Using the same learning algorithm, network architecture and hyper-parameters, our algorithm robustly solves more than 20 simulated physics tasks, including classic problems such as cartpole swing-up, dexterous manipulation, legged locomotion and car driving. Our algorithm is able to find policies whose performance is competitive with those found by a planning algorithm with full access to the dynamics of the domain and its derivatives. We further demonstrate that for many of the tasks the algorithm can learn policies end-to-end: directly from raw pixel inputs.