 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Stepping on the Edge: Curvature Aware Learning Rate Tuners
Jul 08, 2024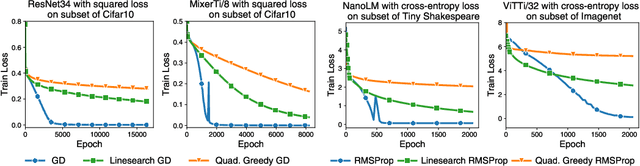
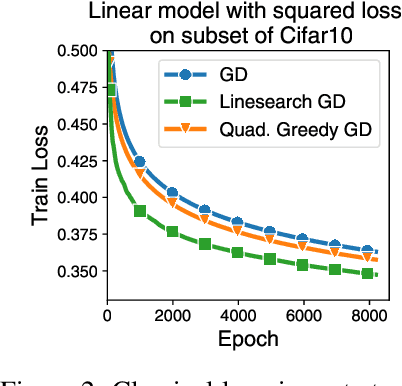
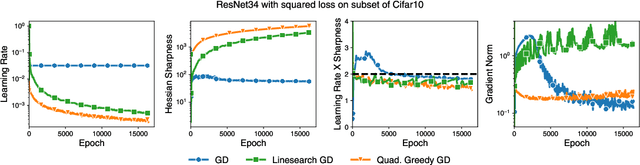
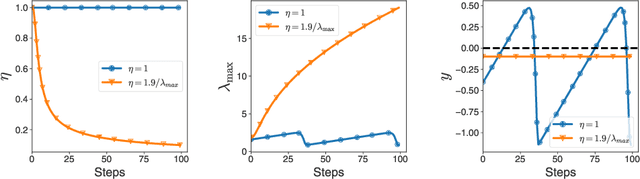
Curvature information -- particularly, the largest eigenvalue of the loss Hessian, known as the sharpness -- often forms the basis for learning rate tuners. However, recent work has shown that the curvature information undergoes complex dynamics during training, going from a phase of increasing sharpness to eventual stabilization. We analyze the closed-loop feedback effect between learning rate tuning and curvature. We find that classical learning rate tuners may yield greater one-step loss reduction, yet they ultimately underperform in the long term when compared to constant learning rates in the full batch regime. These models break the stabilization of the sharpness, which we explain using a simplified model of the joint dynamics of the learning rate and the curvature. To further investigate these effects, we introduce a new learning rate tuning method, Curvature Dynamics Aware Tuning (CDAT), which prioritizes long term curvature stabilization over instantaneous progress on the objective. In the full batch regime, CDAT shows behavior akin to prefixed warm-up schedules on deep learning objectives, outperforming tuned constant learning rates. In the mini batch regime, we observe that stochasticity introduces confounding effects that explain the previous success of some learning rate tuners at appropriate batch sizes. Our findings highlight the critical role of understanding the joint dynamics of the learning rate and curvature, beyond greedy minimization, to diagnose failures and design effective adaptive learning rate tuners.
Emergent Communication: Generalization and Overfitting in Lewis Games
Sep 30, 2022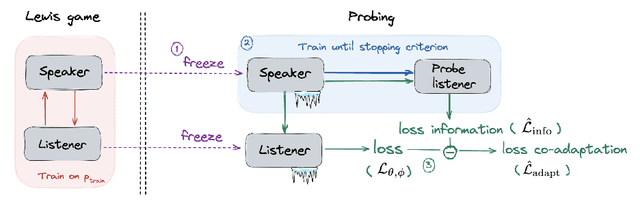

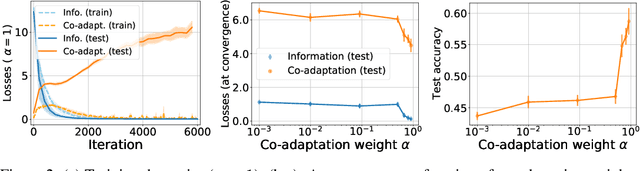

Lewis signaling games are a class of simple communication games for simulating the emergence of language. In these games, two agents must agree on a communication protocol in order to solve a cooperative task. Previous work has shown that agents trained to play this game with reinforcement learning tend to develop languages that display undesirable properties from a linguistic point of view (lack of generalization, lack of compositionality, etc). In this paper, we aim to provide better understanding of this phenomenon by analytically studying the learning problem in Lewis games. As a core contribution, we demonstrate that the standard objective in Lewis games can be decomposed in two components: a co-adaptation loss and an information loss. This decomposition enables us to surface two potential sources of overfitting, which we show may undermine the emergence of a structured communication protocol. In particular, when we control for overfitting on the co-adaptation loss, we recover desired properties in the emergent languages: they are more compositional and generalize better.
BYOL-Explore: Exploration by Bootstrapped Prediction
Jun 16, 2022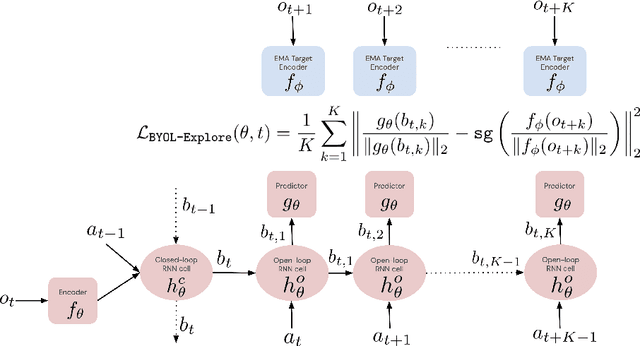
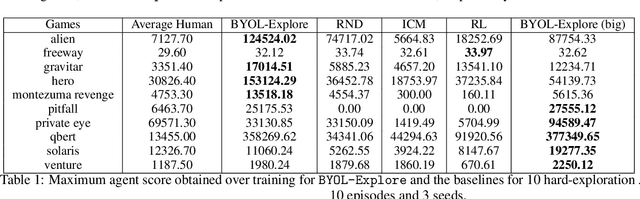

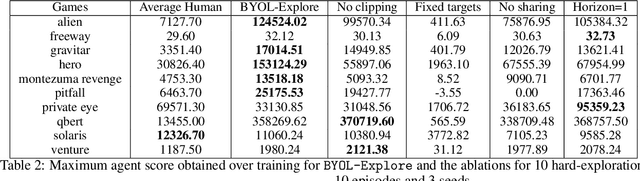
We present BYOL-Explore, a conceptually simple yet general approach for curiosity-driven exploration in visually-complex environments. BYOL-Explore learns a world representation, the world dynamics, and an exploration policy all-together by optimizing a single prediction loss in the latent space with no additional auxiliary objective. We show that BYOL-Explore is effective in DM-HARD-8, a challenging partially-observable continuous-action hard-exploration benchmark with visually-rich 3-D environments. On this benchmark, we solve the majority of the tasks purely through augmenting the extrinsic reward with BYOL-Explore s intrinsic reward, whereas prior work could only get off the ground with human demonstrations. As further evidence of the generality of BYOL-Explore, we show that it achieves superhuman performance on the ten hardest exploration games in Atari while having a much simpler design than other competitive agents.
Broaden Your Views for Self-Supervised Video Learning
Mar 30, 2021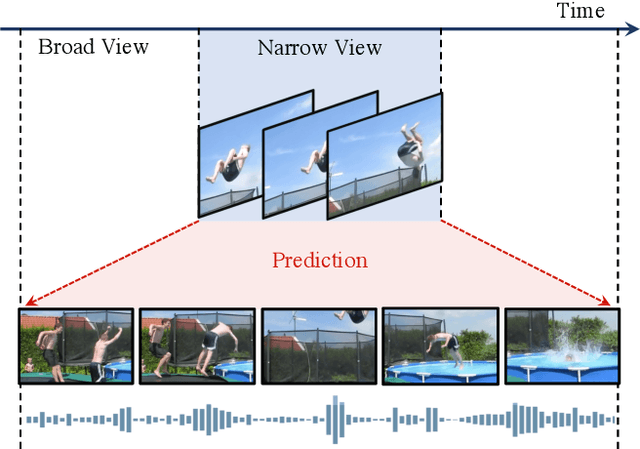
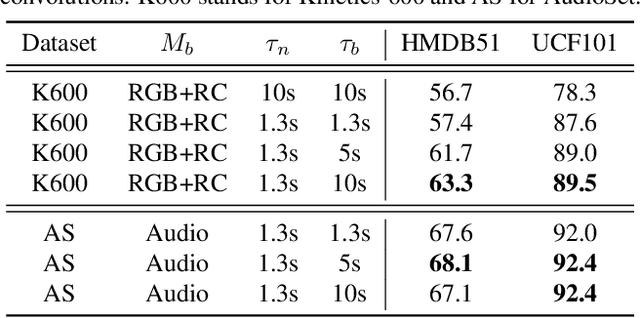
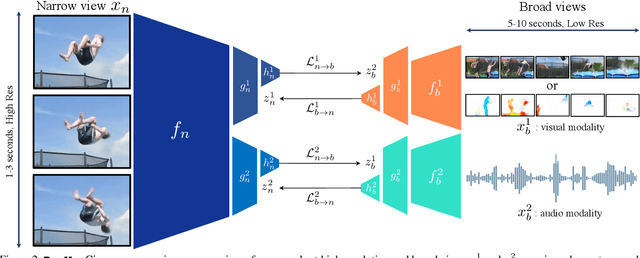
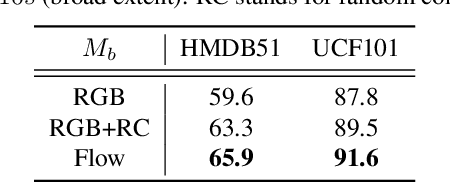
Most successful self-supervised learning methods are trained to align the representations of two independent views from the data. State-of-the-art methods in video are inspired by image techniques, where these two views are similarly extracted by cropping and augmenting the resulting crop. However, these methods miss a crucial element in the video domain: time. We introduce BraVe, a self-supervised learning framework for video. In BraVe, one of the views has access to a narrow temporal window of the video while the other view has a broad access to the video content. Our models learn to generalise from the narrow view to the general content of the video. Furthermore, BraVe processes the views with different backbones, enabling the use of alternative augmentations or modalities into the broad view such as optical flow, randomly convolved RGB frames, audio or their combinations. We demonstrate that BraVe achieves state-of-the-art results in self-supervised representation learning on standard video and audio classification benchmarks including UCF101, HMDB51, Kinetics, ESC-50 and AudioSet.
BYOL works even without batch statistics
Oct 20, 2020

Bootstrap Your Own Latent (BYOL) is a self-supervised learning approach for image representation. From an augmented view of an image, BYOL trains an online network to predict a target network representation of a different augmented view of the same image. Unlike contrastive methods, BYOL does not explicitly use a repulsion term built from negative pairs in its training objective. Yet, it avoids collapse to a trivial, constant representation. Thus, it has recently been hypothesized that batch normalization (BN) is critical to prevent collapse in BYOL. Indeed, BN flows gradients across batch elements, and could leak information about negative views in the batch, which could act as an implicit negative (contrastive) term. However, we experimentally show that replacing BN with a batch-independent normalization scheme (namely, a combination of group normalization and weight standardization) achieves performance comparable to vanilla BYOL ($73.9\%$ vs. $74.3\%$ top-1 accuracy under the linear evaluation protocol on ImageNet with ResNet-$50$). Our finding disproves the hypothesis that the use of batch statistics is a crucial ingredient for BYOL to learn useful representations.
Monte-Carlo Tree Search as Regularized Policy Optimization
Jul 24, 2020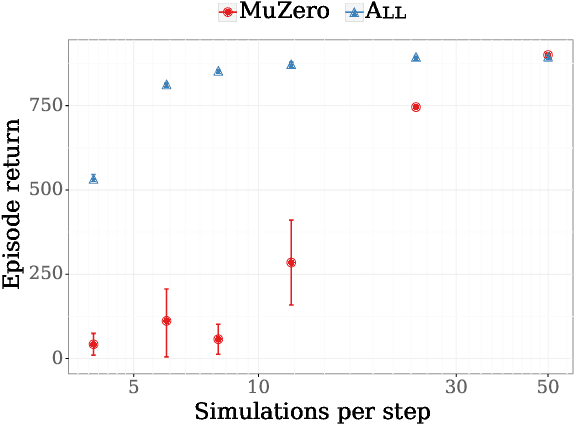
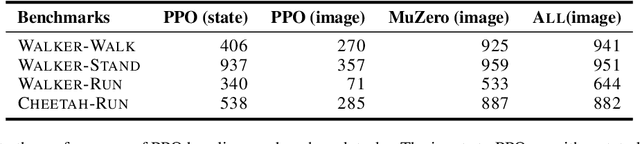
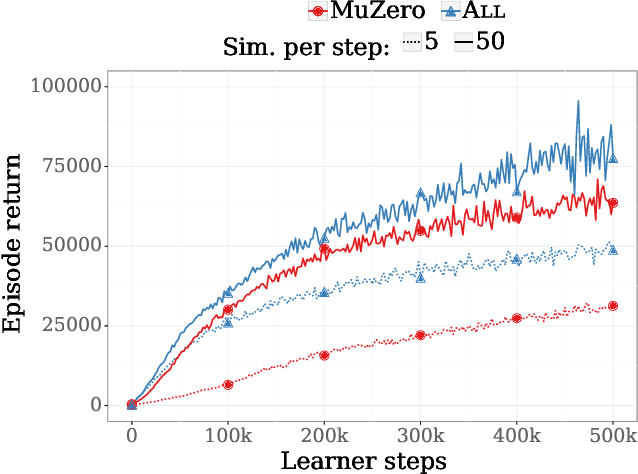
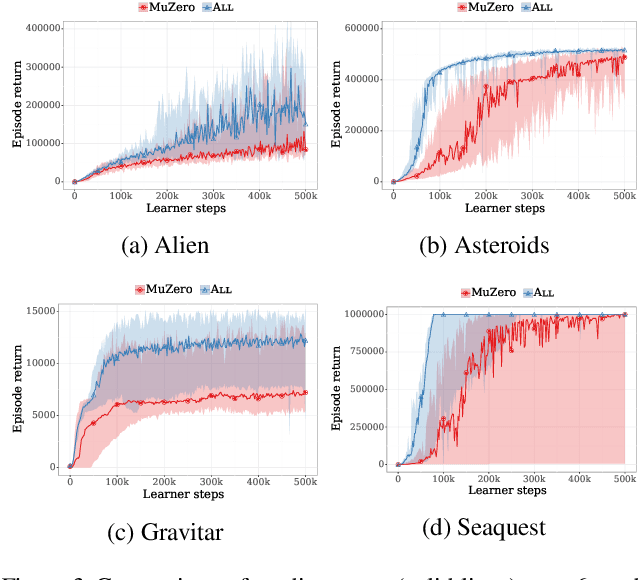
The combination of Monte-Carlo tree search (MCTS) with deep reinforcement learning has led to significant advances in artificial intelligence. However, AlphaZero, the current state-of-the-art MCTS algorithm, still relies on handcrafted heuristics that are only partially understood. In this paper, we show that AlphaZero's search heuristics, along with other common ones such as UCT, are an approximation to the solution of a specific regularized policy optimization problem. With this insight, we propose a variant of AlphaZero which uses the exact solution to this policy optimization problem, and show experimentally that it reliably outperforms the original algorithm in multiple domains.
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
Jun 13, 2020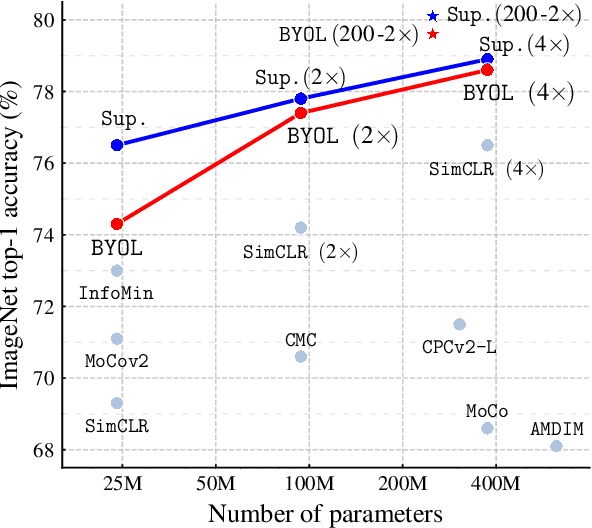

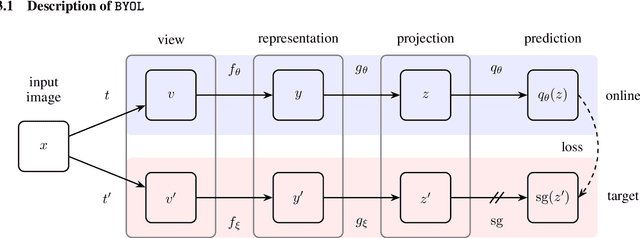
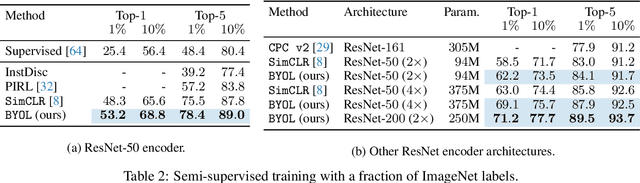
We introduce Bootstrap Your Own Latent (BYOL), a new approach to self-supervised image representation learning. BYOL relies on two neural networks, referred to as online and target networks, that interact and learn from each other. From an augmented view of an image, we train the online network to predict the target network representation of the same image under a different augmented view. At the same time, we update the target network with a slow-moving average of the online network. While state-of-the art methods intrinsically rely on negative pairs, BYOL achieves a new state of the art without them. BYOL reaches $74.3\%$ top-1 classification accuracy on ImageNet using the standard linear evaluation protocol with a ResNet-50 architecture and $79.6\%$ with a larger ResNet. We show that BYOL performs on par or better than the current state of the art on both transfer and semi-supervised benchmarks.
World Discovery Models
Mar 01, 2019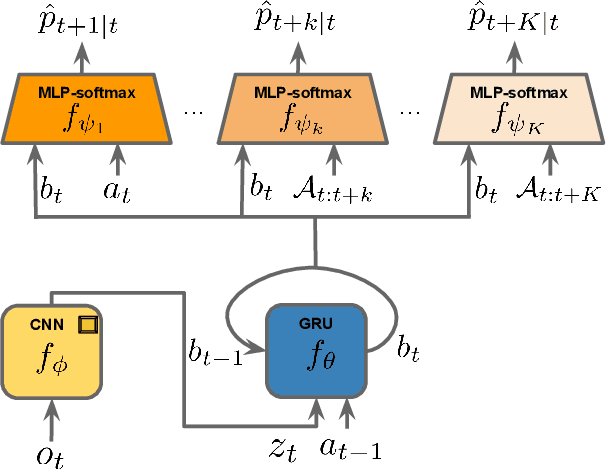
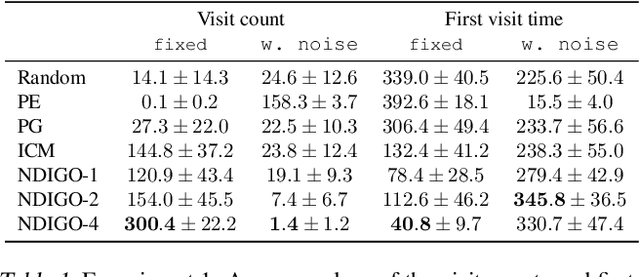

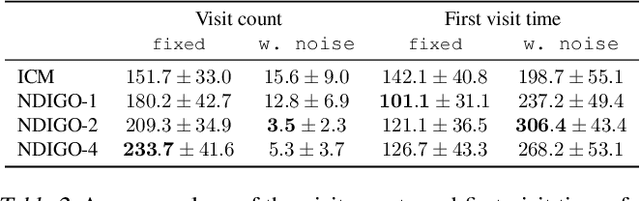
As humans we are driven by a strong desire for seeking novelty in our world. Also upon observing a novel pattern we are capable of refining our understanding of the world based on the new information---humans can discover their world. The outstanding ability of the human mind for discovery has led to many breakthroughs in science, art and technology. Here we investigate the possibility of building an agent capable of discovering its world using the modern AI technology. In particular we introduce NDIGO, Neural Differential Information Gain Optimisation, a self-supervised discovery model that aims at seeking new information to construct a global view of its world from partial and noisy observations. Our experiments on some controlled 2-D navigation tasks show that NDIGO outperforms state-of-the-art information-seeking methods in terms of the quality of the learned representation. The improvement in performance is particularly significant in the presence of white or structured noise where other information-seeking methods follow the noise instead of discovering their world.
Optimistic optimization of a Brownian
Jan 15, 2019We address the problem of optimizing a Brownian motion. We consider a (random) realization $W$ of a Brownian motion with input space in $[0,1]$. Given $W$, our goal is to return an $\epsilon$-approximation of its maximum using the smallest possible number of function evaluations, the sample complexity of the algorithm. We provide an algorithm with sample complexity of order $\log^2(1/\epsilon)$. This improves over previous results of Al-Mharmah and Calvin (1996) and Calvin et al. (2017) which provided only polynomial rates. Our algorithm is adaptive---each query depends on previous values---and is an instance of the optimism-in-the-face-of-uncertainty principle.
* 10 pages, 2 figures