 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Machine Learning to Robotics: Challenges and Opportunities for Embodied Intelligence
Oct 28, 2021
Machine learning has long since become a keystone technology, accelerating science and applications in a broad range of domains. Consequently, the notion of applying learning methods to a particular problem set has become an established and valuable modus operandi to advance a particular field. In this article we argue that such an approach does not straightforwardly extended to robotics -- or to embodied intelligence more generally: systems which engage in a purposeful exchange of energy and information with a physical environment. In particular, the purview of embodied intelligent agents extends significantly beyond the typical considerations of main-stream machine learning approaches, which typically (i) do not consider operation under conditions significantly different from those encountered during training; (ii) do not consider the often substantial, long-lasting and potentially safety-critical nature of interactions during learning and deployment; (iii) do not require ready adaptation to novel tasks while at the same time (iv) effectively and efficiently curating and extending their models of the world through targeted and deliberate actions. In reality, therefore, these limitations result in learning-based systems which suffer from many of the same operational shortcomings as more traditional, engineering-based approaches when deployed on a robot outside a well defined, and often narrow operating envelope. Contrary to viewing embodied intelligence as another application domain for machine learning, here we argue that it is in fact a key driver for the advancement of machine learning technology. In this article our goal is to highlight challenges and opportunities that are specific to embodied intelligence and to propose research directions which may significantly advance the state-of-the-art in robot learning.
Neural Production Systems
Mar 02, 2021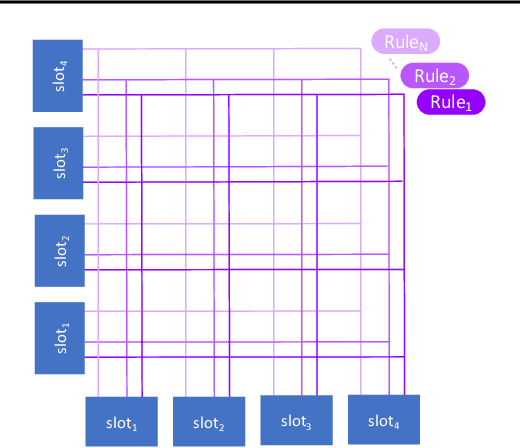

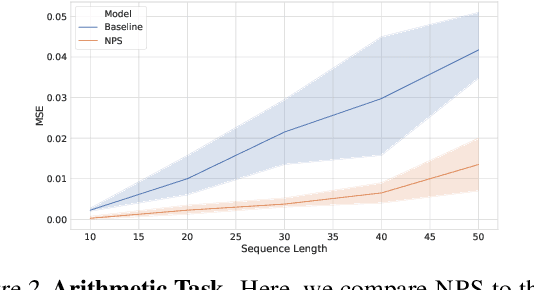
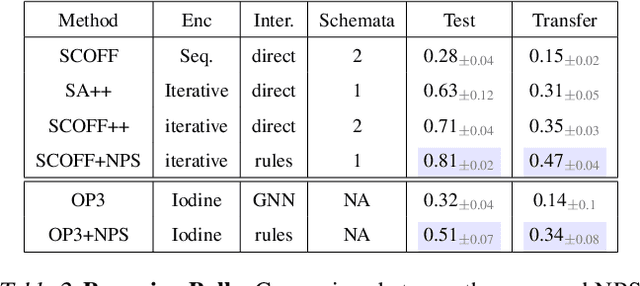
Visual environments are structured, consisting of distinct objects or entities. These entities have properties -- both visible and latent -- that determine the manner in which they interact with one another. To partition images into entities, deep-learning researchers have proposed structural inductive biases such as slot-based architectures. To model interactions among entities, equivariant graph neural nets (GNNs) are used, but these are not particularly well suited to the task for two reasons. First, GNNs do not predispose interactions to be sparse, as relationships among independent entities are likely to be. Second, GNNs do not factorize knowledge about interactions in an entity-conditional manner. As an alternative, we take inspiration from cognitive science and resurrect a classic approach, production systems, which consist of a set of rule templates that are applied by binding placeholder variables in the rules to specific entities. Rules are scored on their match to entities, and the best fitting rules are applied to update entity properties. In a series of experiments, we demonstrate that this architecture achieves a flexible, dynamic flow of control and serves to factorize entity-specific and rule-based information. This disentangling of knowledge achieves robust future-state prediction in rich visual environments, outperforming state-of-the-art methods using GNNs, and allows for the extrapolation from simple (few object) environments to more complex environments.
Neural Function Modules with Sparse Arguments: A Dynamic Approach to Integrating Information across Layers
Oct 15, 2020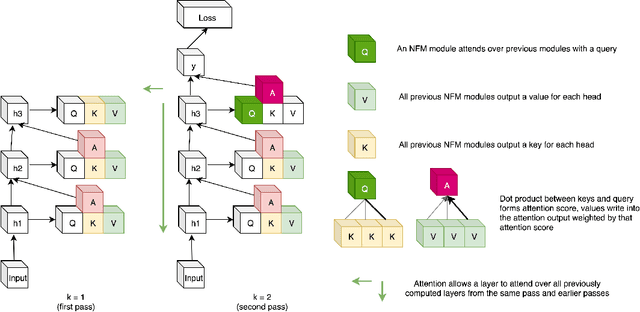


Feed-forward neural networks consist of a sequence of layers, in which each layer performs some processing on the information from the previous layer. A downside to this approach is that each layer (or module, as multiple modules can operate in parallel) is tasked with processing the entire hidden state, rather than a particular part of the state which is most relevant for that module. Methods which only operate on a small number of input variables are an essential part of most programming languages, and they allow for improved modularity and code re-usability. Our proposed method, Neural Function Modules (NFM), aims to introduce the same structural capability into deep learning. Most of the work in the context of feed-forward networks combining top-down and bottom-up feedback is limited to classification problems. The key contribution of our work is to combine attention, sparsity, top-down and bottom-up feedback, in a flexible algorithm which, as we show, improves the results in standard classification, out-of-domain generalization, generative modeling, and learning representations in the context of reinforcement learning.
Object Files and Schemata: Factorizing Declarative and Procedural Knowledge in Dynamical Systems
Jun 30, 2020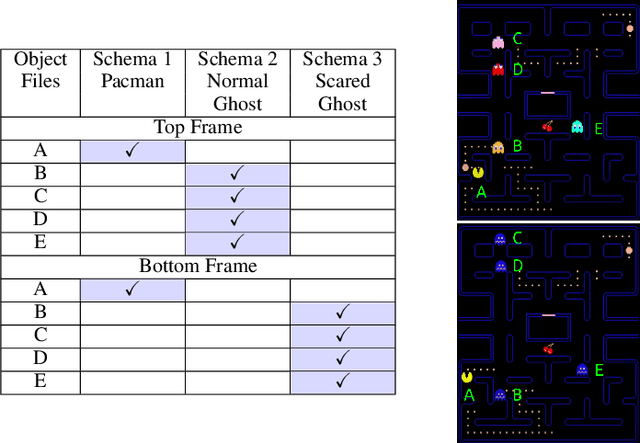
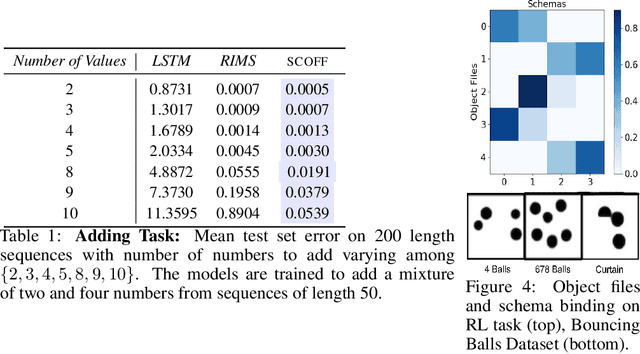
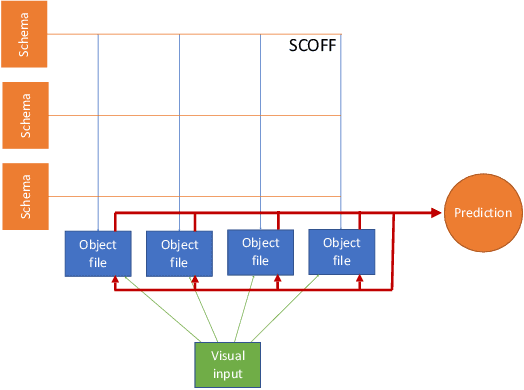

Modeling a structured, dynamic environment like a video game requires keeping track of the objects and their states (\emph{declarative} knowledge) as well as predicting how objects behave (\emph{procedural} knowledge). Black-box models with a monolithic hidden state often lack \emph{systematicity}: they fail to apply procedural knowledge consistently and uniformly. For example, in a video game, correct prediction of one enemy's trajectory does not ensure correct prediction of another's. We address this issue via an architecture that factorizes declarative and procedural knowledge and that imposes modularity within each form of knowledge. The architecture consists of active modules called \emph{object files} that maintain the state of a single object and invoke passive external knowledge sources called \emph{schemata} that prescribe state updates. To use a video game as an illustration, two enemies of the same type will share schemata but will each have their own object file to encode their distinct state (e.g., health, position). We propose to use attention to control the determination of which object files to update, the selection of schemata, and the propagation of information between object files. The resulting architecture is a drop-in replacement conforming to the same input-output interface as normal recurrent networks (e.g., LSTM, GRU) yet achieves substantially better generalization on environments that have factorized declarative and procedural knowledge, including a challenging intuitive physics benchmark.
CLOSURE: Assessing Systematic Generalization of CLEVR Models
Dec 12, 2019
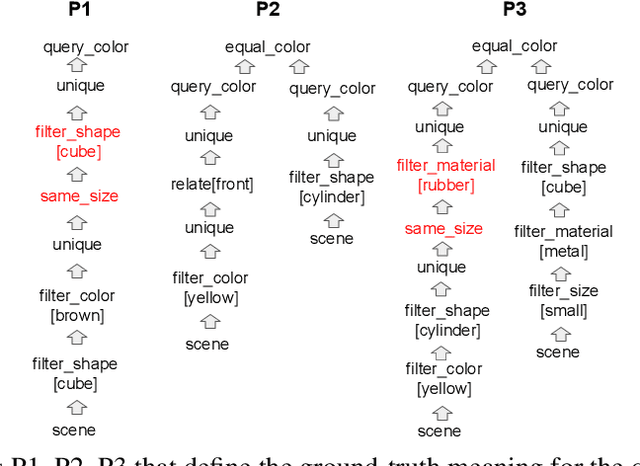
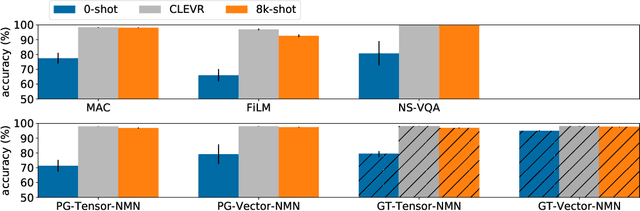
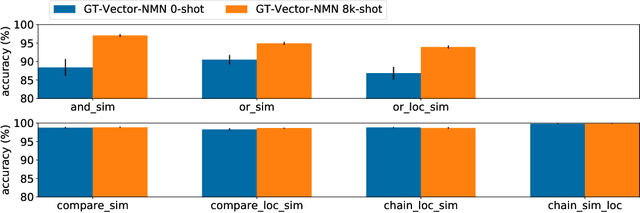
The CLEVR dataset of natural-looking questions about 3D-rendered scenes has recently received much attention from the research community. A number of models have been proposed for this task, many of which achieved very high accuracies of around 97-99%. In this work, we study how systematic the generalization of such models is, that is to which extent they are capable of handling novel combinations of known linguistic constructs. To this end, we test models' understanding of referring expressions based on matching object properties (such as e.g. "the object that is the same size as the red ball") in novel contexts. Our experiments on the thereby constructed CLOSURE benchmark show that state-of-the-art models often do not exhibit systematicity after being trained on CLEVR. Surprisingly, we find that an explicitly compositional Neural Module Network model also generalizes badly on CLOSURE, even when it has access to the ground-truth programs at test time. We improve the NMN's systematic generalization by developing a novel Vector-NMN module architecture with vector-valued inputs and outputs. Lastly, we investigate the extent to which few-shot transfer learning can help models that are pretrained on CLEVR to adapt to CLOSURE. Our few-shot learning experiments contrast the adaptation behavior of the models with intermediate discrete programs with that of the end-to-end continuous models.
Neocortical plasticity: an unsupervised cake but no free lunch
Nov 15, 2019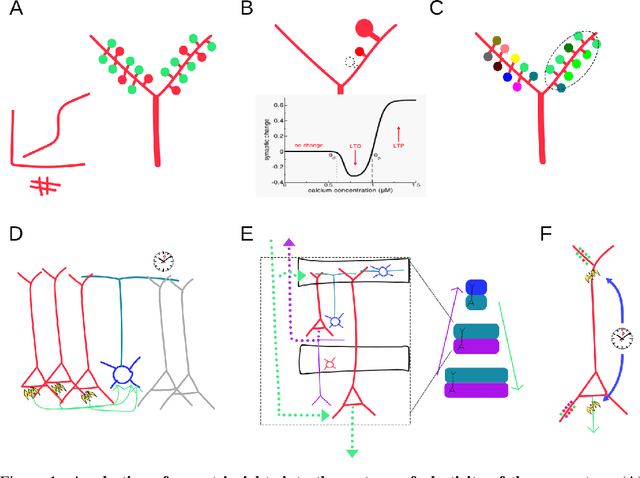
The fields of artificial intelligence and neuroscience have a long history of fertile bi-directional interactions. On the one hand, important inspiration for the development of artificial intelligence systems has come from the study of natural systems of intelligence, the mammalian neocortex in particular. On the other, important inspiration for models and theories of the brain have emerged from artificial intelligence research. A central question at the intersection of these two areas is concerned with the processes by which neocortex learns, and the extent to which they are analogous to the back-propagation training algorithm of deep networks. Matching the data efficiency, transfer and generalization properties of neocortical learning remains an area of active research in the field of deep learning. Recent advances in our understanding of neuronal, synaptic and dendritic physiology of the neocortex suggest new approaches for unsupervised representation learning, perhaps through a new class of objective functions, which could act alongside or in lieu of back-propagation. Such local learning rules have implicit rather than explicit objectives with respect to the training data, facilitating domain adaptation and generalization. Incorporating them into deep networks for representation learning could better leverage unlabelled datasets to offer significant improvements in data efficiency of downstream supervised readout learning, and reduce susceptibility to adversarial perturbations, at the cost of a more restricted domain of applicability.
Disentangling the independently controllable factors of variation by interacting with the world
Feb 26, 2018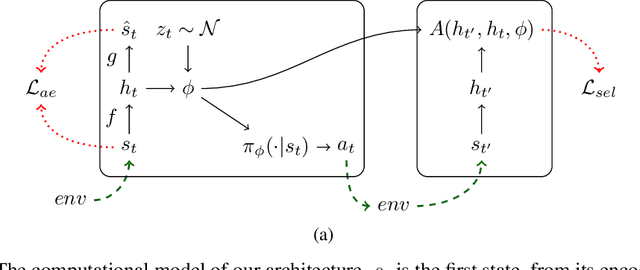
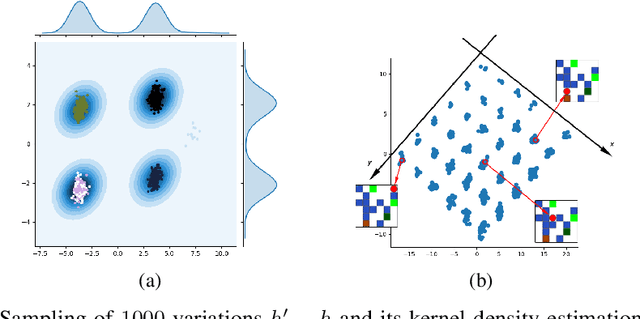
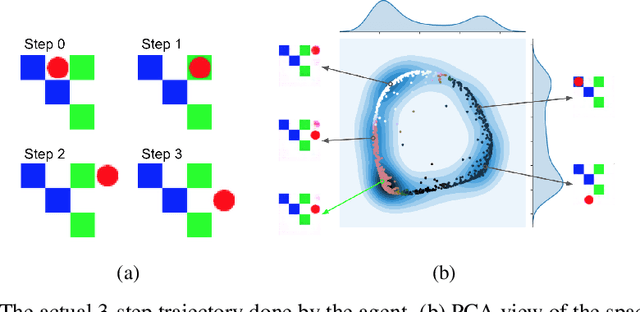
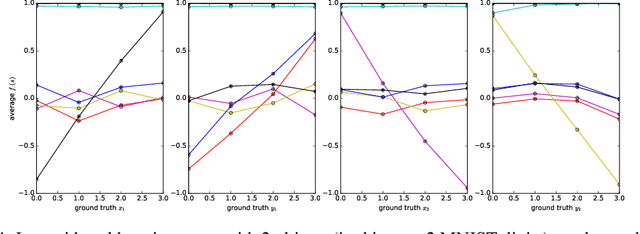
It has been postulated that a good representation is one that disentangles the underlying explanatory factors of variation. However, it remains an open question what kind of training framework could potentially achieve that. Whereas most previous work focuses on the static setting (e.g., with images), we postulate that some of the causal factors could be discovered if the learner is allowed to interact with its environment. The agent can experiment with different actions and observe their effects. More specifically, we hypothesize that some of these factors correspond to aspects of the environment which are independently controllable, i.e., that there exists a policy and a learnable feature for each such aspect of the environment, such that this policy can yield changes in that feature with minimal changes to other features that explain the statistical variations in the observed data. We propose a specific objective function to find such factors, and verify experimentally that it can indeed disentangle independently controllable aspects of the environment without any extrinsic reward signal.
Independently Controllable Factors
Aug 25, 2017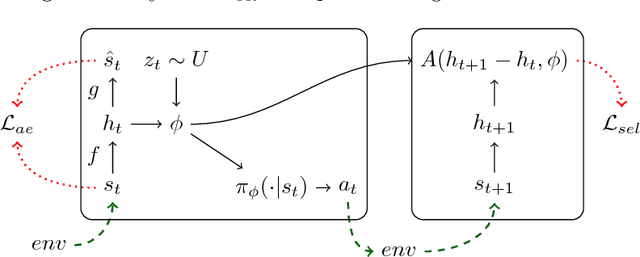
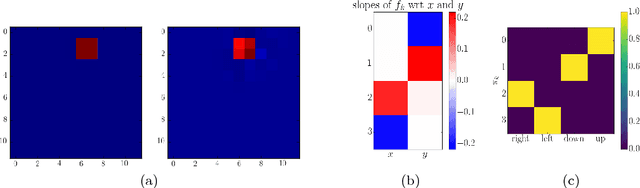
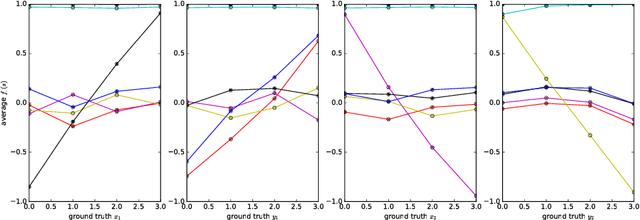
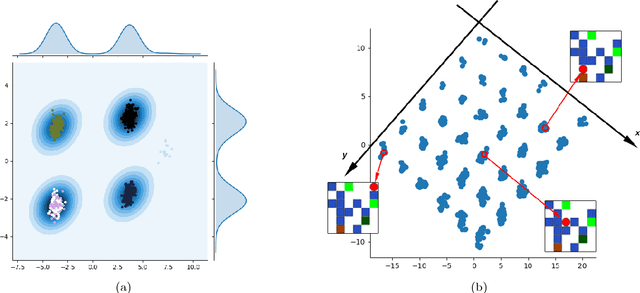
It has been postulated that a good representation is one that disentangles the underlying explanatory factors of variation. However, it remains an open question what kind of training framework could potentially achieve that. Whereas most previous work focuses on the static setting (e.g., with images), we postulate that some of the causal factors could be discovered if the learner is allowed to interact with its environment. The agent can experiment with different actions and observe their effects. More specifically, we hypothesize that some of these factors correspond to aspects of the environment which are independently controllable, i.e., that there exists a policy and a learnable feature for each such aspect of the environment, such that this policy can yield changes in that feature with minimal changes to other features that explain the statistical variations in the observed data. We propose a specific objective function to find such factors and verify experimentally that it can indeed disentangle independently controllable aspects of the environment without any extrinsic reward signal.