 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining CLIP's performance disparities on data from blind/low vision users
Dec 01, 2023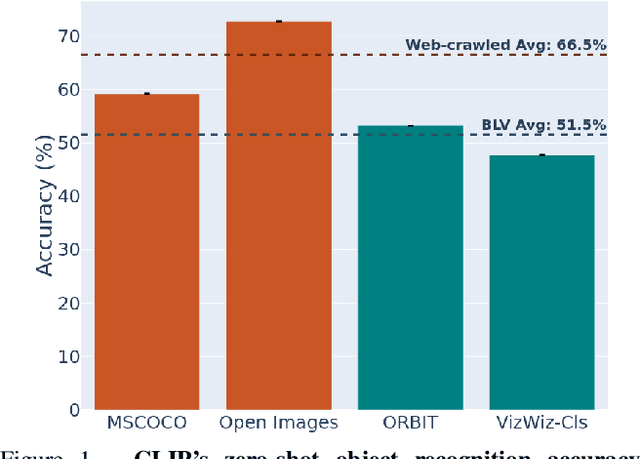
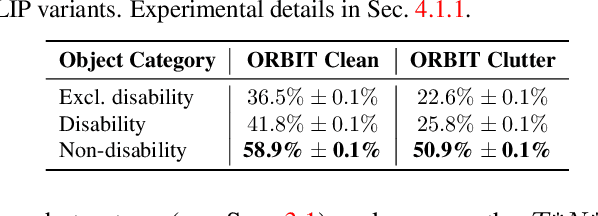
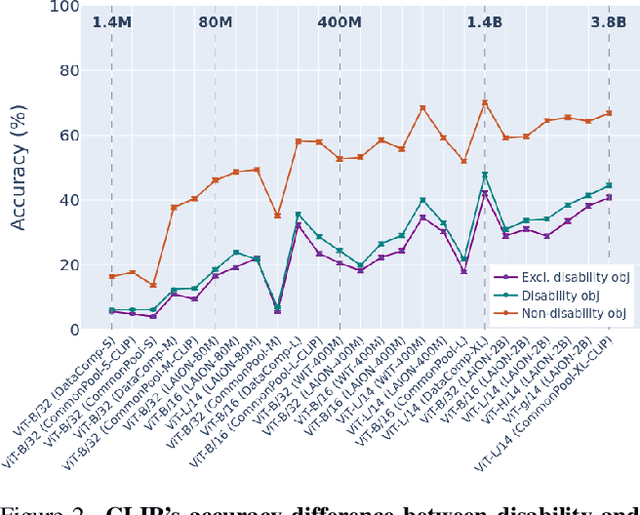
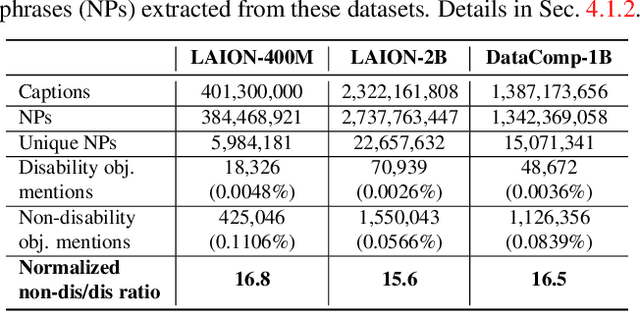
Large multi-modal models (LMMs) hold the potential to usher in a new era of automated visual assistance for people who are blind or low vision (BLV). Yet, these models have not been systematically evaluated on data captured by BLV users. We address this by empirically assessing CLIP, a widely-used LMM likely to underpin many assistive technologies. Testing 25 CLIP variants in a zero-shot classification task, we find that their accuracy is 15 percentage points lower on average for images captured by BLV users than web-crawled images. This disparity stems from CLIP's sensitivities to 1) image content (e.g. not recognizing disability objects as well as other objects); 2) image quality (e.g. not being robust to lighting variation); and 3) text content (e.g. not recognizing objects described by tactile adjectives as well as visual ones). We delve deeper with a textual analysis of three common pre-training datasets: LAION-400M, LAION-2B and DataComp-1B, showing that disability content is rarely mentioned. We then provide three examples that illustrate how the performance disparities extend to three downstream models underpinned by CLIP: OWL-ViT, CLIPSeg and DALL-E2. We find that few-shot learning with as few as 5 images can mitigate CLIP's quality-of-service disparities for BLV users in some scenarios, which we discuss alongside a set of other possible mitigations.
Algorithmic Bias and Data Bias: Understanding the Relation between Distributionally Robust Optimization and Data Curation
Jun 17, 2021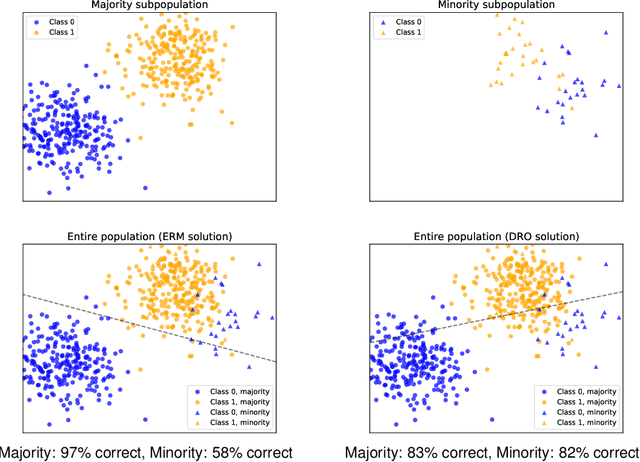
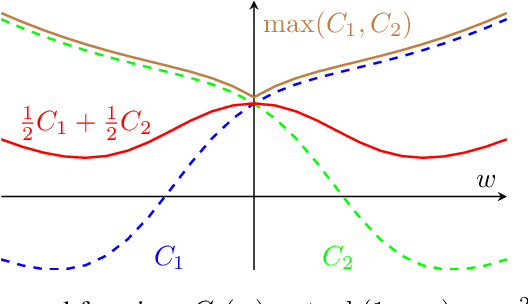
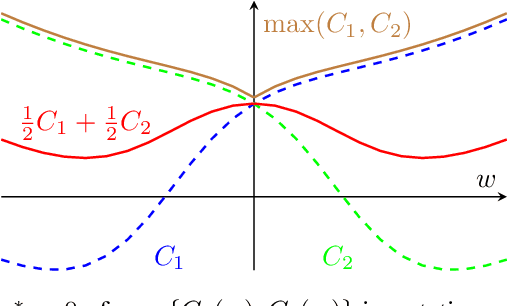
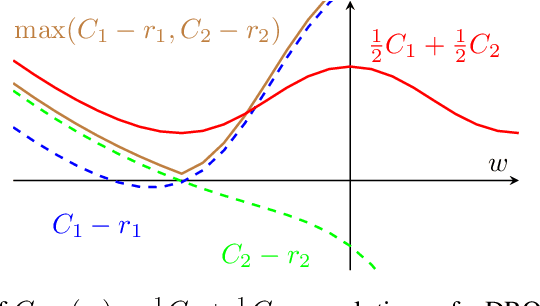
Machine learning systems based on minimizing average error have been shown to perform inconsistently across notable subsets of the data, which is not exposed by a low average error for the entire dataset. In consequential social and economic applications, where data represent people, this can lead to discrimination of underrepresented gender and ethnic groups. Given the importance of bias mitigation in machine learning, the topic leads to contentious debates on how to ensure fairness in practice (data bias versus algorithmic bias). Distributionally Robust Optimization (DRO) seemingly addresses this problem by minimizing the worst expected risk across subpopulations. We establish theoretical results that clarify the relation between DRO and the optimization of the same loss averaged on an adequately weighted training dataset. The results cover finite and infinite number of training distributions, as well as convex and non-convex loss functions. We show that neither DRO nor curating the training set should be construed as a complete solution for bias mitigation: in the same way that there is no universally robust training set, there is no universal way to setup a DRO problem and ensure a socially acceptable set of results. We then leverage these insights to provide a mininal set of practical recommendations for addressing bias with DRO. Finally, we discuss ramifications of our results in other related applications of DRO, using an example of adversarial robustness. Our results show that there is merit to both the algorithm-focused and the data-focused side of the bias debate, as long as arguments in favor of these positions are precisely qualified and backed by relevant mathematics known today.
Linear unit-tests for invariance discovery
Feb 22, 2021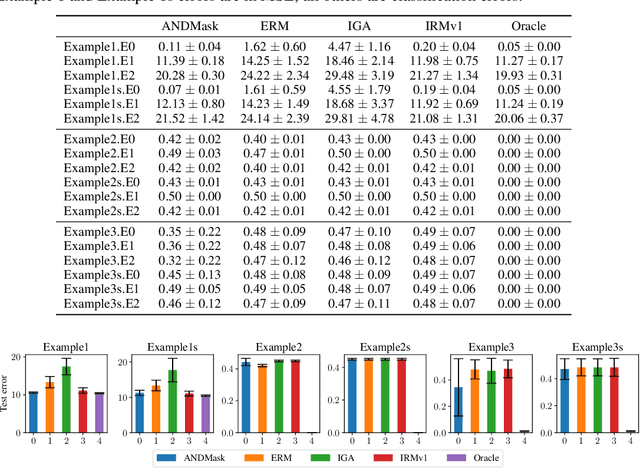
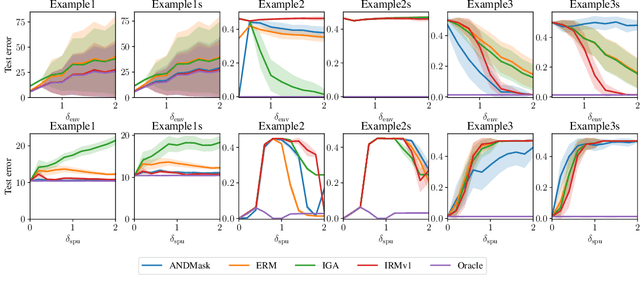
There is an increasing interest in algorithms to learn invariant correlations across training environments. A big share of the current proposals find theoretical support in the causality literature but, how useful are they in practice? The purpose of this note is to propose six linear low-dimensional problems -- unit tests -- to evaluate different types of out-of-distribution generalization in a precise manner. Following initial experiments, none of the three recently proposed alternatives passes all tests. By providing the code to automatically replicate all the results in this manuscript (https://www.github.com/facebookresearch/InvarianceUnitTests), we hope that our unit tests become a standard steppingstone for researchers in out-of-distribution generalization.
Inductive Bias and Language Expressivity in Emergent Communication
Dec 04, 2020
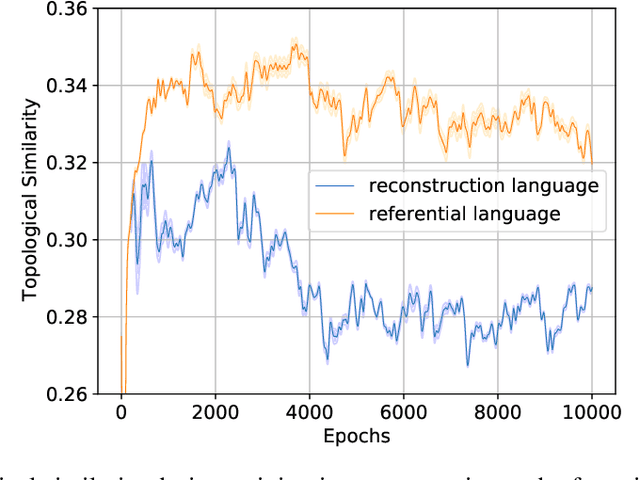

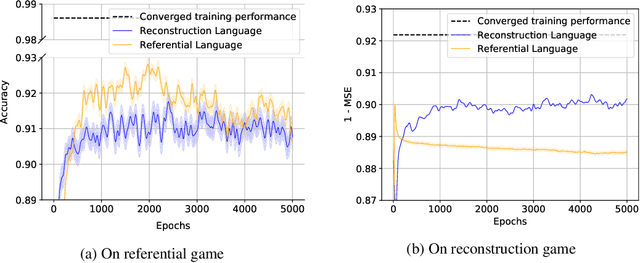
Referential games and reconstruction games are the most common game types for studying emergent languages. We investigate how the type of the language game affects the emergent language in terms of: i) language compositionality and ii) transfer of an emergent language to a task different from its origin, which we refer to as language expressivity. With empirical experiments on a handcrafted symbolic dataset, we show that languages emerged from different games have different compositionality and further different expressivity.
Neural Function Modules with Sparse Arguments: A Dynamic Approach to Integrating Information across Layers
Oct 15, 2020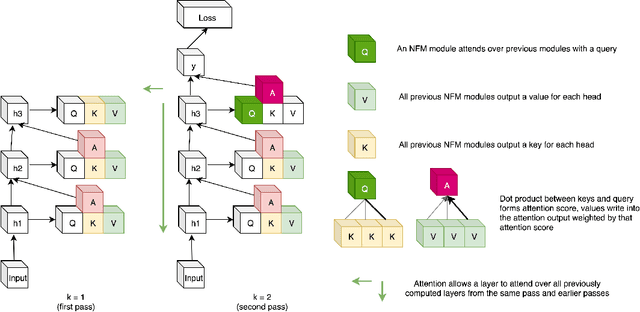


Feed-forward neural networks consist of a sequence of layers, in which each layer performs some processing on the information from the previous layer. A downside to this approach is that each layer (or module, as multiple modules can operate in parallel) is tasked with processing the entire hidden state, rather than a particular part of the state which is most relevant for that module. Methods which only operate on a small number of input variables are an essential part of most programming languages, and they allow for improved modularity and code re-usability. Our proposed method, Neural Function Modules (NFM), aims to introduce the same structural capability into deep learning. Most of the work in the context of feed-forward networks combining top-down and bottom-up feedback is limited to classification problems. The key contribution of our work is to combine attention, sparsity, top-down and bottom-up feedback, in a flexible algorithm which, as we show, improves the results in standard classification, out-of-domain generalization, generative modeling, and learning representations in the context of reinforcement learning.
Exploring Structural Inductive Biases in Emergent Communication
Feb 04, 2020
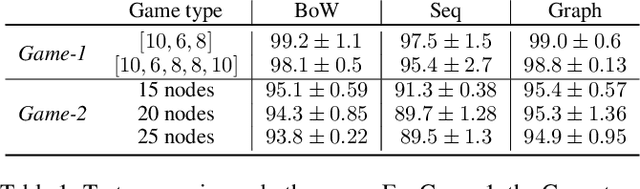
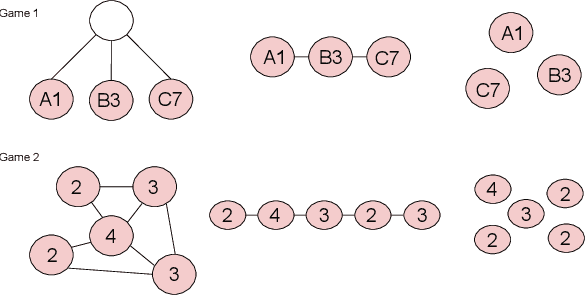
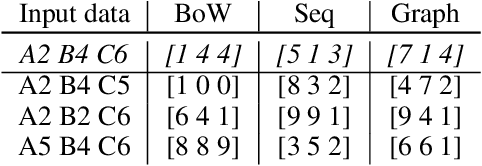
Human language and thought are characterized by the ability to systematically generate a potentially infinite number of complex structures (e.g., sentences) from a finite set of familiar components (e.g., words). Recent works in emergent communication have discussed the propensity of artificial agents to develop a systematically compositional language through playing co-operative referential games. The degree of structure in the input data was found to affect the compositionality of the emerged communication protocols. Thus, we explore various structural priors in multi-agent communication and propose a novel graph referential game. We compare the effect of structural inductive bias (bag-of-words, sequences and graphs) on the emergence of compositional understanding of the input concepts measured by topographic similarity and generalization to unseen combinations of familiar properties. We empirically show that graph neural networks induce a better compositional language prior and a stronger generalization to out-of-domain data. We further perform ablation studies that show the robustness of the emerged protocol in graph referential games.
Towards Graph Representation Learning in Emergent Communication
Feb 04, 2020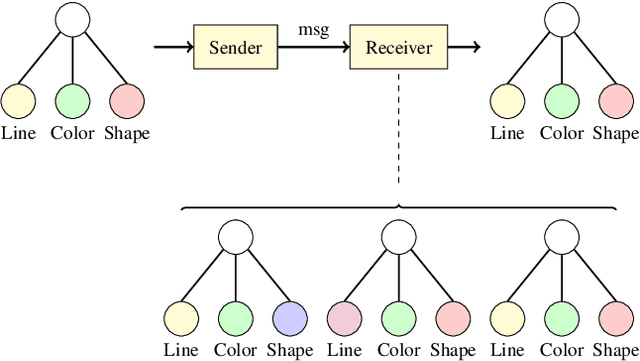

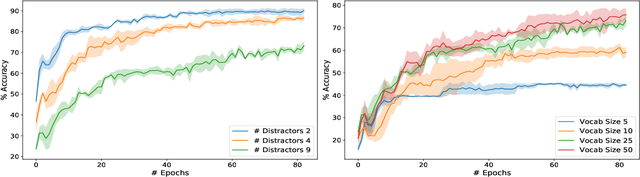
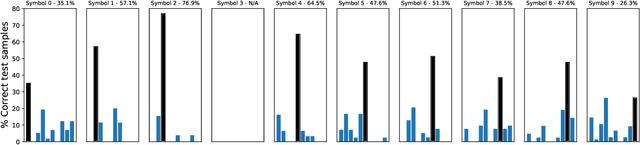
Recent findings in neuroscience suggest that the human brain represents information in a geometric structure (for instance, through conceptual spaces). In order to communicate, we flatten the complex representation of entities and their attributes into a single word or a sentence. In this paper we use graph convolutional networks to support the evolution of language and cooperation in multi-agent systems. Motivated by an image-based referential game, we propose a graph referential game with varying degrees of complexity, and we provide strong baseline models that exhibit desirable properties in terms of language emergence and cooperation. We show that the emerged communication protocol is robust, that the agents uncover the true factors of variation in the game, and that they learn to generalize beyond the samples encountered during training.
Bayesian Optimisation with Gaussian Processes for Premise Selection
Sep 18, 2019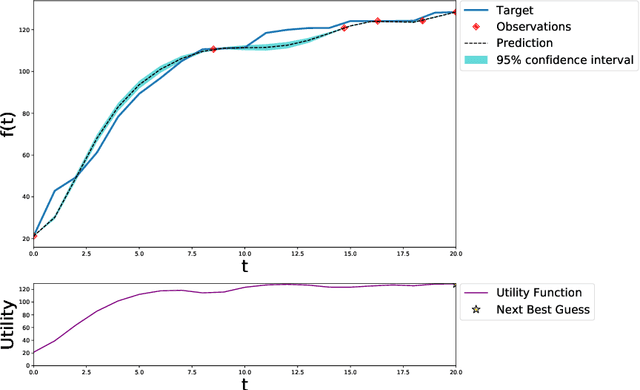
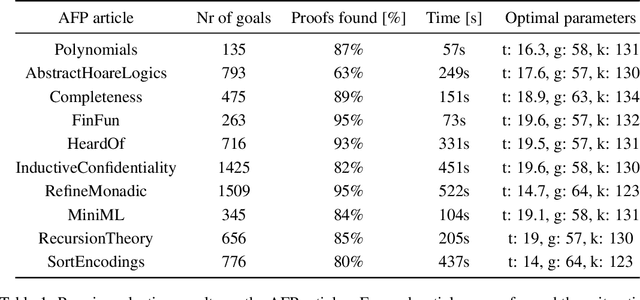
Heuristics in theorem provers are often parameterised. Modern theorem provers such as Vampire utilise a wide array of heuristics to control the search space explosion, thereby requiring optimisation of a large set of parameters. An exhaustive search in this multi-dimensional parameter space is intractable in most cases, yet the performance of the provers is highly dependent on the parameter assignment. In this work, we introduce a principled probablistic framework for heuristics optimisation in theorem provers. We present results using a heuristic for premise selection and The Archive of Formal Proofs (AFP) as a case study.
Geometric Graph Convolutional Neural Networks
Sep 11, 2019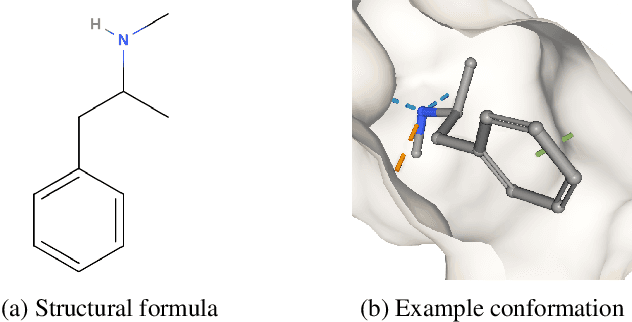
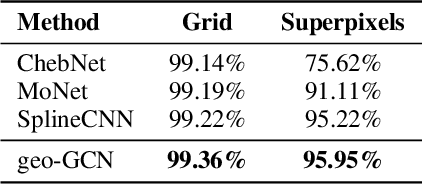
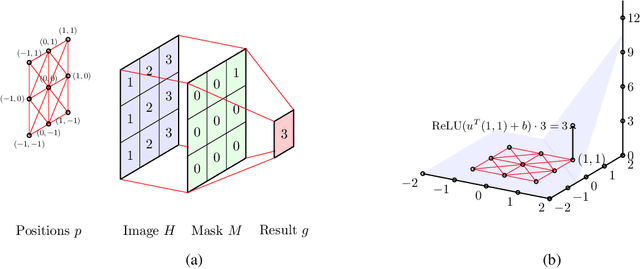
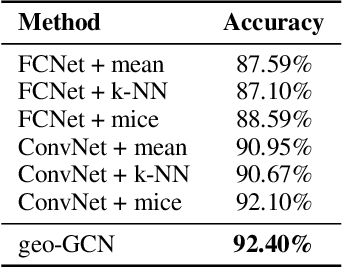
Graph Convolutional Networks (GCNs) have recently become the primary choice for learning from graph-structured data, superseding hash fingerprints in representing chemical compounds. However, GCNs lack the ability to take into account the ordering of node neighbors, even when there is a geometric interpretation of the graph vertices that provides an order based on their spatial positions. To remedy this issue, we propose Geometric Graph Convolutional Network (geo-GCN) which uses spatial features to efficiently learn from graphs that can be naturally located in space. Our contribution is threefold: we propose a GCN-inspired architecture which (i) leverages node positions, (ii) is a proper generalisation of both GCNs and Convolutional Neural Networks (CNNs), (iii) benefits from augmentation which further improves the performance and assures invariance with respect to the desired properties. Empirically, geo-GCN outperforms state-of-the-art graph-based methods on image classification and chemical tasks.
Completing partial recipes using item-based collaborative filtering to recommend ingredients
Jul 23, 2019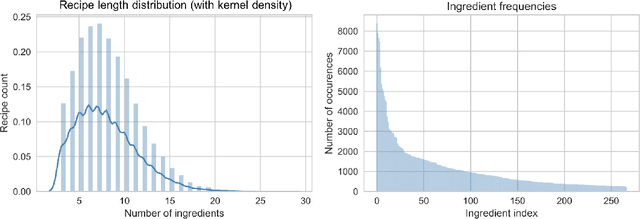
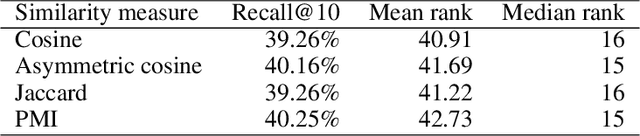

Increased public interest in healthy lifestyles has motivated the study of algorithms that encourage people to follow a healthy diet. Applying collaborative filtering to build recommendation systems in domains where only implicit feedback is available is also a rapidly growing research area. In this report we combine these two trends by developing a recommendation system to suggest ingredients that can be added to a partial recipe. We implement the item-based collaborative filtering algorithm using a high-dimensional, sparse dataset of recipes, which inherently contains only implicit feedback. We explore the effect of different similarity measures and dimensionality reduction on the quality of the recommendations, and find that our best method achieves a recall@10 of circa 40%.