 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Information Storage and Transfer in Multi-modal Large Language Models
Jun 06, 2024Understanding the mechanisms of information storage and transfer in Transformer-based models is important for driving model understanding progress. Recent work has studied these mechanisms for Large Language Models (LLMs), revealing insights on how information is stored in a model's parameters and how information flows to and from these parameters in response to specific prompts. However, these studies have not yet been extended to Multi-modal Large Language Models (MLLMs). Given their expanding capabilities and real-world use, we start by studying one aspect of these models -- how MLLMs process information in a factual visual question answering task. We use a constraint-based formulation which views a visual question as having a set of visual or textual constraints that the model's generated answer must satisfy to be correct (e.g. What movie directed by the director in this photo has won a Golden Globe?). Under this setting, we contribute i) a method that extends causal information tracing from pure language to the multi-modal setting, and ii) VQA-Constraints, a test-bed of 9.7K visual questions annotated with constraints. We use these tools to study two open-source MLLMs, LLaVa and multi-modal Phi-2. Our key findings show that these MLLMs rely on MLP and self-attention blocks in much earlier layers for information storage, compared to LLMs whose mid-layer MLPs are more important. We also show that a consistent small subset of visual tokens output by the vision encoder are responsible for transferring information from the image to these causal blocks. We validate these mechanisms by introducing MultEdit, a model-editing algorithm that can correct errors and insert new long-tailed information into MLLMs by targeting these causal blocks.
Explaining CLIP's performance disparities on data from blind/low vision users
Dec 01, 2023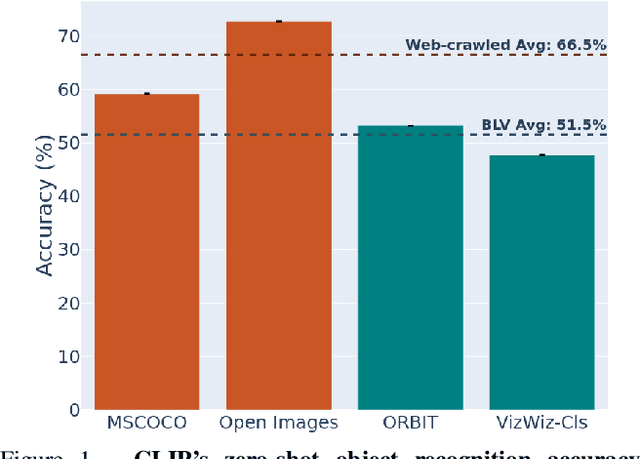
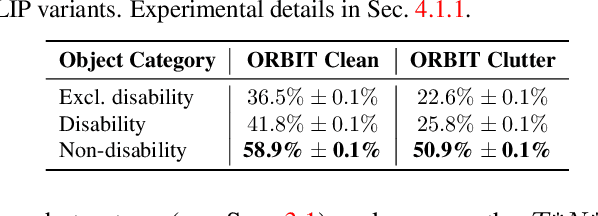
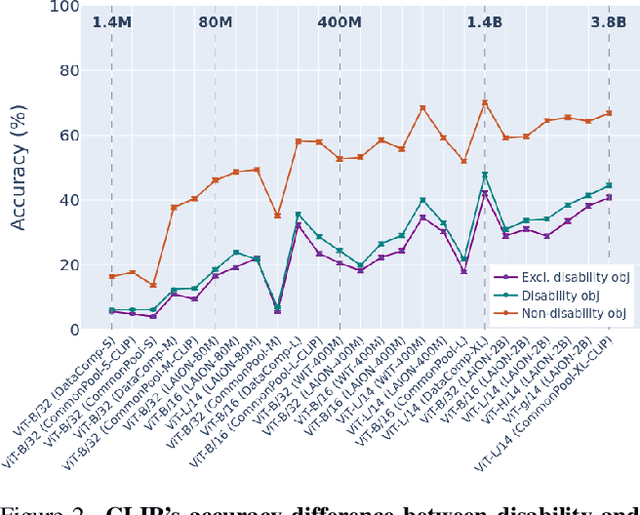
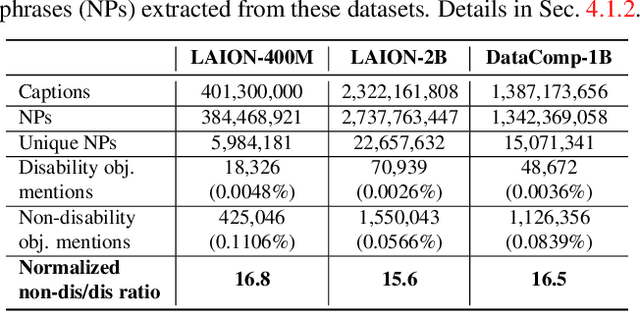
Large multi-modal models (LMMs) hold the potential to usher in a new era of automated visual assistance for people who are blind or low vision (BLV). Yet, these models have not been systematically evaluated on data captured by BLV users. We address this by empirically assessing CLIP, a widely-used LMM likely to underpin many assistive technologies. Testing 25 CLIP variants in a zero-shot classification task, we find that their accuracy is 15 percentage points lower on average for images captured by BLV users than web-crawled images. This disparity stems from CLIP's sensitivities to 1) image content (e.g. not recognizing disability objects as well as other objects); 2) image quality (e.g. not being robust to lighting variation); and 3) text content (e.g. not recognizing objects described by tactile adjectives as well as visual ones). We delve deeper with a textual analysis of three common pre-training datasets: LAION-400M, LAION-2B and DataComp-1B, showing that disability content is rarely mentioned. We then provide three examples that illustrate how the performance disparities extend to three downstream models underpinned by CLIP: OWL-ViT, CLIPSeg and DALL-E2. We find that few-shot learning with as few as 5 images can mitigate CLIP's quality-of-service disparities for BLV users in some scenarios, which we discuss alongside a set of other possible mitigations.