 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented Review Generation for Poisoning Recommender Systems
Aug 21, 2025Recent studies have shown that recommender systems (RSs) are highly vulnerable to data poisoning attacks, where malicious actors inject fake user profiles, including a group of well-designed fake ratings, to manipulate recommendations. Due to security and privacy constraints in practice, attackers typically possess limited knowledge of the victim system and thus need to craft profiles that have transferability across black-box RSs. To maximize the attack impact, the profiles often remains imperceptible. However, generating such high-quality profiles with the restricted resources is challenging. Some works suggest incorporating fake textual reviews to strengthen the profiles; yet, the poor quality of the reviews largely undermines the attack effectiveness and imperceptibility under the practical setting. To tackle the above challenges, in this paper, we propose to enhance the quality of the review text by harnessing in-context learning (ICL) capabilities of multimodal foundation models. To this end, we introduce a demonstration retrieval algorithm and a text style transfer strategy to augment the navie ICL. Specifically, we propose a novel practical attack framework named RAGAN to generate high-quality fake user profiles, which can gain insights into the robustness of RSs. The profiles are generated by a jailbreaker and collaboratively optimized on an instructional agent and a guardian to improve the attack transferability and imperceptibility. Comprehensive experiments on various real-world datasets demonstrate that RAGAN achieves the state-of-the-art poisoning attack performance.
Generating Clinically Realistic EHR Data via a Hierarchy- and Semantics-Guided Transformer
Feb 28, 2025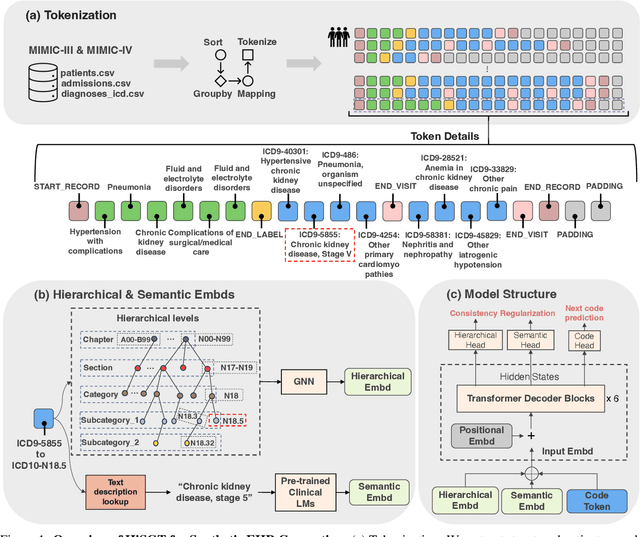
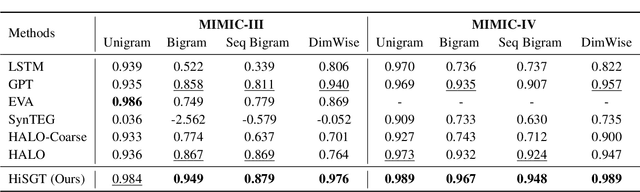
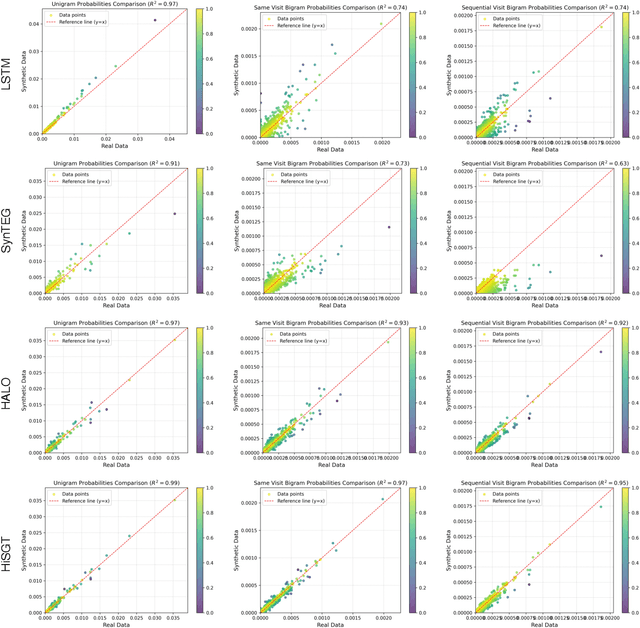
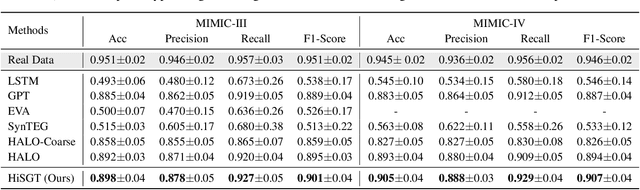
Generating realistic synthetic electronic health records (EHRs) holds tremendous promise for accelerating healthcare research, facilitating AI model development and enhancing patient privacy. However, existing generative methods typically treat EHRs as flat sequences of discrete medical codes. This approach overlooks two critical aspects: the inherent hierarchical organization of clinical coding systems and the rich semantic context provided by code descriptions. Consequently, synthetic patient sequences often lack high clinical fidelity and have limited utility in downstream clinical tasks. In this paper, we propose the Hierarchy- and Semantics-Guided Transformer (HiSGT), a novel framework that leverages both hierarchical and semantic information for the generative process. HiSGT constructs a hierarchical graph to encode parent-child and sibling relationships among clinical codes and employs a graph neural network to derive hierarchy-aware embeddings. These are then fused with semantic embeddings extracted from a pre-trained clinical language model (e.g., ClinicalBERT), enabling the Transformer-based generator to more accurately model the nuanced clinical patterns inherent in real EHRs. Extensive experiments on the MIMIC-III and MIMIC-IV datasets demonstrate that HiSGT significantly improves the statistical alignment of synthetic data with real patient records, as well as supports robust downstream applications such as chronic disease classification. By addressing the limitations of conventional raw code-based generative models, HiSGT represents a significant step toward clinically high-fidelity synthetic data generation and a general paradigm suitable for interpretable medical code representation, offering valuable applications in data augmentation and privacy-preserving healthcare analytics.
Adapting Large Multimodal Models to Distribution Shifts: The Role of In-Context Learning
May 20, 2024Recent studies indicate that large multimodal models (LMMs) are highly robust against natural distribution shifts, often surpassing previous baselines. Despite this, domain-specific adaptation is still necessary, particularly in specialized areas like healthcare. Due to the impracticality of fine-tuning LMMs given their vast parameter space, this work investigates in-context learning (ICL) as an effective alternative for enhancing LMMs' adaptability. We find that the success of ICL heavily relies on the choice of demonstration, mirroring challenges seen in large language models but introducing unique complexities for LMMs facing distribution shifts. Our study addresses this by evaluating an unsupervised ICL method, TopKNearestPR, which selects in-context examples through a nearest example search based on feature similarity. We uncover that its effectiveness is limited by the deficiencies of pre-trained vision encoders under distribution shift scenarios. To address these challenges, we propose InvariantSelectPR, a novel method leveraging Class-conditioned Contrastive Invariance (CCI) for more robust demonstration selection. Specifically, CCI enhances pre-trained vision encoders by improving their discriminative capabilities across different classes and ensuring invariance to domain-specific variations. This enhancement allows the encoders to effectively identify and retrieve the most informative examples, which are then used to guide LMMs in adapting to new query samples under varying distributions. Our experiments show that InvariantSelectPR substantially improves the adaptability of LMMs, achieving significant performance gains on benchmark datasets, with a 34.2%$\uparrow$ accuracy increase in 7-shot on Camelyon17 and 16.9%$\uparrow$ increase in 7-shot on HAM10000 compared to the baseline zero-shot performance.
HCVP: Leveraging Hierarchical Contrastive Visual Prompt for Domain Generalization
Jan 18, 2024



Domain Generalization (DG) endeavors to create machine learning models that excel in unseen scenarios by learning invariant features. In DG, the prevalent practice of constraining models to a fixed structure or uniform parameterization to encapsulate invariant features can inadvertently blend specific aspects. Such an approach struggles with nuanced differentiation of inter-domain variations and may exhibit bias towards certain domains, hindering the precise learning of domain-invariant features. Recognizing this, we introduce a novel method designed to supplement the model with domain-level and task-specific characteristics. This approach aims to guide the model in more effectively separating invariant features from specific characteristics, thereby boosting the generalization. Building on the emerging trend of visual prompts in the DG paradigm, our work introduces the novel \textbf{H}ierarchical \textbf{C}ontrastive \textbf{V}isual \textbf{P}rompt (HCVP) methodology. This represents a significant advancement in the field, setting itself apart with a unique generative approach to prompts, alongside an explicit model structure and specialized loss functions. Differing from traditional visual prompts that are often shared across entire datasets, HCVP utilizes a hierarchical prompt generation network enhanced by prompt contrastive learning. These generative prompts are instance-dependent, catering to the unique characteristics inherent to different domains and tasks. Additionally, we devise a prompt modulation network that serves as a bridge, effectively incorporating the generated visual prompts into the vision transformer backbone. Experiments conducted on five DG datasets demonstrate the effectiveness of HCVP, outperforming both established DG algorithms and adaptation protocols.
How Well Does GPT-4V Adapt to Distribution Shifts? A Preliminary Investigation
Dec 13, 2023



In machine learning, generalization against distribution shifts -- where deployment conditions diverge from the training scenarios -- is crucial, particularly in fields like climate modeling, biomedicine, and autonomous driving. The emergence of foundation models, distinguished by their extensive pretraining and task versatility, has led to an increased interest in their adaptability to distribution shifts. GPT-4V(ision) acts as the most advanced publicly accessible multimodal foundation model, with extensive applications across various domains, including anomaly detection, video understanding, image generation, and medical diagnosis. However, its robustness against data distributions remains largely underexplored. Addressing this gap, this study rigorously evaluates GPT-4V's adaptability and generalization capabilities in dynamic environments, benchmarking against prominent models like CLIP and LLaVA. We delve into GPT-4V's zero-shot generalization across 13 diverse datasets spanning natural, medical, and molecular domains. We further investigate its adaptability to controlled data perturbations and examine the efficacy of in-context learning as a tool to enhance its adaptation. Our findings delineate GPT-4V's capability boundaries in distribution shifts, shedding light on its strengths and limitations across various scenarios. Importantly, this investigation contributes to our understanding of how AI foundation models generalize to distribution shifts, offering pivotal insights into their adaptability and robustness. Code is publicly available at https://github.com/jameszhou-gl/gpt-4v-distribution-shift.
On the Opportunity of Causal Deep Generative Models: A Survey and Future Directions
Feb 03, 2023



Deep generative models have gained popularity in recent years due to their ability to accurately replicate inherent empirical distributions and yield novel samples. In particular, certain advances are proposed wherein the model engenders data examples following specified attributes. Nevertheless, several challenges still exist and are to be overcome, i.e., difficulty in extrapolating out-of-sample data and insufficient learning of disentangled representations. Structural causal models (SCMs), on the other hand, encapsulate the causal factors that govern a generative process and characterize a generative model based on causal relationships, providing crucial insights for addressing the current obstacles in deep generative models. In this paper, we present a comprehensive survey of Causal deep Generative Models (CGMs), which combine SCMs and deep generative models in a way that boosts several trustworthy properties such as robustness, fairness, and interpretability. We provide an overview of the recent advances in CGMs, categorize them based on generative types, and discuss how causality is introduced into the family of deep generative models. We also explore potential avenues for future research in this field.
Learning to Infer Counterfactuals: Meta-Learning for Estimating Multiple Imbalanced Treatment Effects
Aug 13, 2022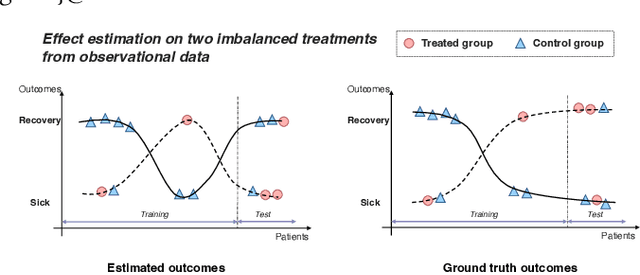
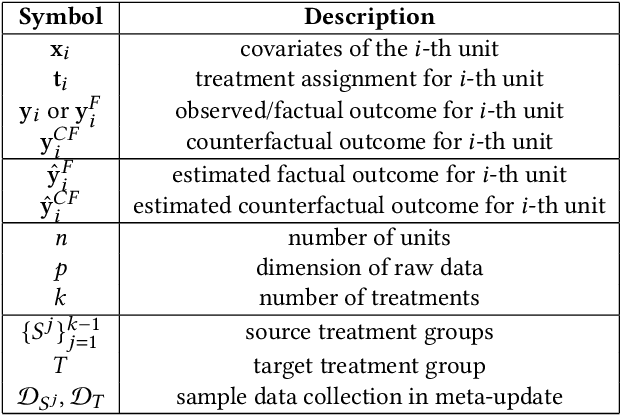
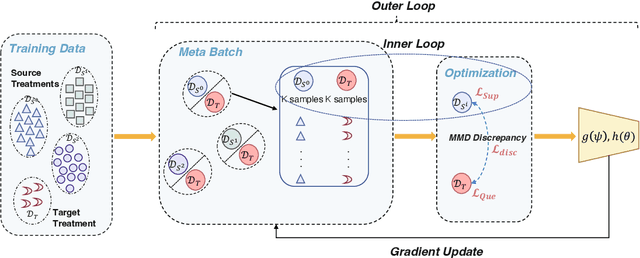
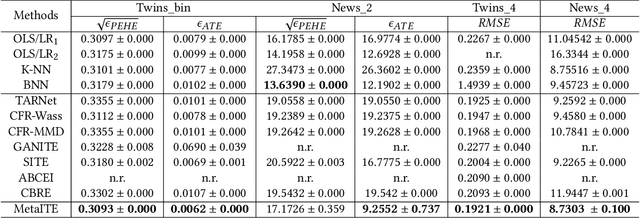
We regularly consider answering counterfactual questions in practice, such as "Would people with diabetes take a turn for the better had they choose another medication?". Observational studies are growing in significance in answering such questions due to their widespread accumulation and comparatively easier acquisition than Randomized Control Trials (RCTs). Recently, some works have introduced representation learning and domain adaptation into counterfactual inference. However, most current works focus on the setting of binary treatments. None of them considers that different treatments' sample sizes are imbalanced, especially data examples in some treatment groups are relatively limited due to inherent user preference. In this paper, we design a new algorithmic framework for counterfactual inference, which brings an idea from Meta-learning for Estimating Individual Treatment Effects (MetaITE) to fill the above research gaps, especially considering multiple imbalanced treatments. Specifically, we regard data episodes among treatment groups in counterfactual inference as meta-learning tasks. We train a meta-learner from a set of source treatment groups with sufficient samples and update the model by gradient descent with limited samples in target treatment. Moreover, we introduce two complementary losses. One is the supervised loss on multiple source treatments. The other loss which aligns latent distributions among various treatment groups is proposed to reduce the discrepancy. We perform experiments on two real-world datasets to evaluate inference accuracy and generalization ability. Experimental results demonstrate that the model MetaITE matches/outperforms state-of-the-art methods.
Interventional Recommendation with Contrastive Counterfactual Learning for Better Understanding User Preferences
Aug 13, 2022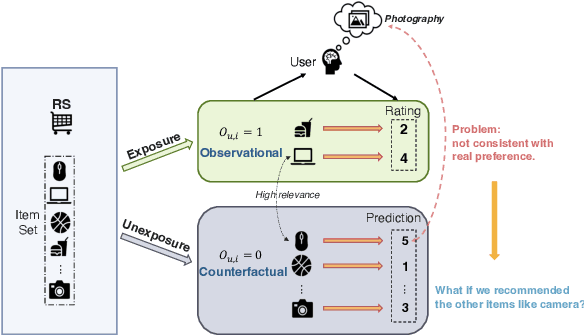
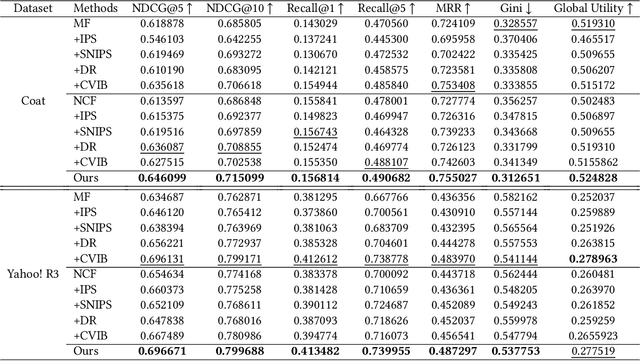
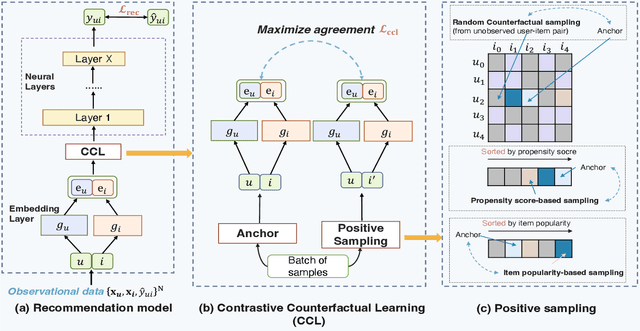
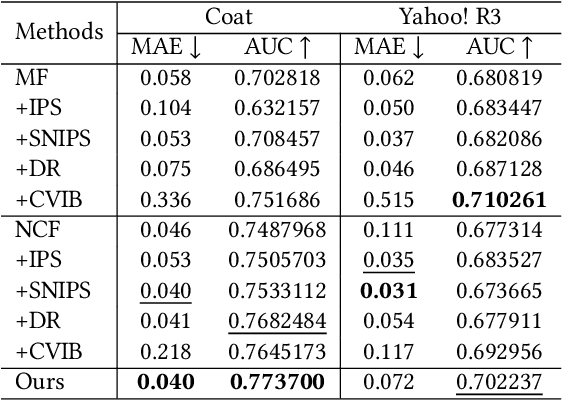
Recently, there has been a surging interest in formulating recommendations in the context of causal inference. The studies regard the recommendation as an intervention in causal inference and frame the users' preferences as interventional effects to improve recommender systems' generalization. Many studies in the field of causal inference for recommender systems have been focusing on utilizing propensity scores from the causal community that reduce the bias while inducing additional variance. Alternatively, some studies suggest the existence of a set of unbiased data from randomized controlled trials while it requires to satisfy certain assumptions that may be challenging in practice. In this paper, we first design a causal graph representing recommender systems' data generation and propagation process. Then, we reveal that the underlying exposure mechanism biases the maximum likelihood estimation (MLE) on observational feedback. In order to figure out users' preferences in terms of causality behind data, we leverage the back-door adjustment and do-calculus, which induces an interventional recommendation model (IREC). Furthermore, considering the confounder may be inaccessible for measurement, we propose a contrastive counterfactual learning method (CCL) for simulating the intervention. In addition, we present two extra novel sampling strategies and show an intriguing finding that sampling from counterfactual sets contributes to superior performance. We perform extensive experiments on two real-world datasets to evaluate and analyze the performance of our model IREC-CCL on unbiased test sets. Experimental results demonstrate our model outperforms the state-of-the-art methods.
Cycle-Balanced Representation Learning For Counterfactual Inference
Oct 29, 2021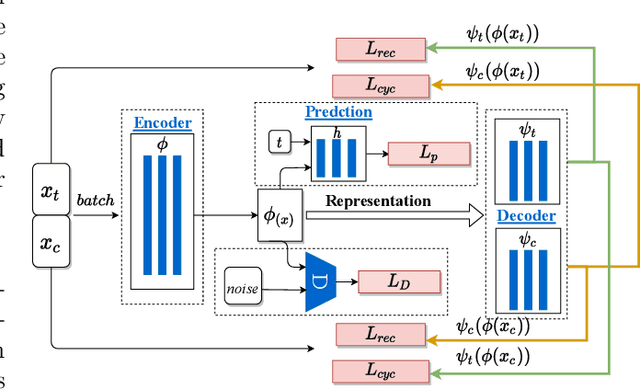
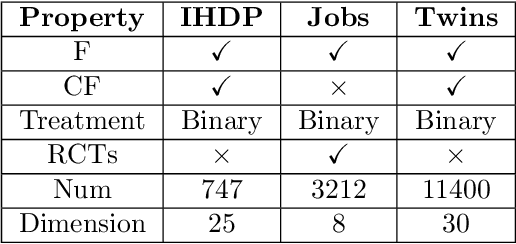
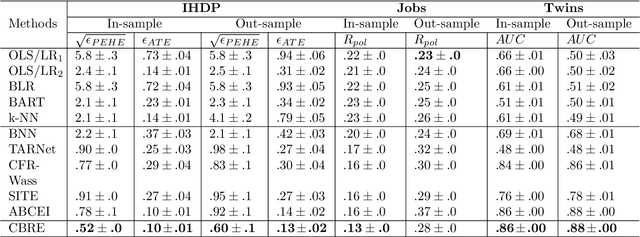
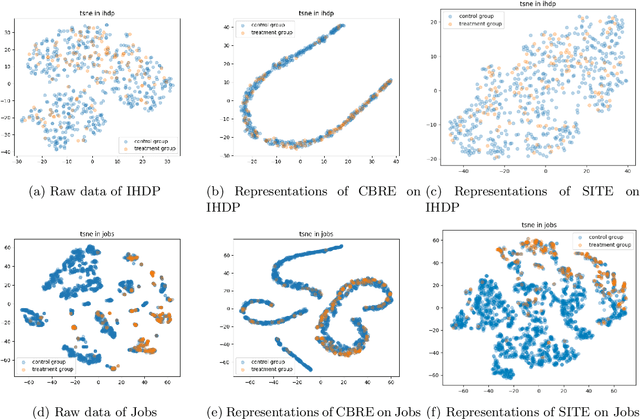
With the widespread accumulation of observational data, researchers obtain a new direction to learn counterfactual effects in many domains (e.g., health care and computational advertising) without Randomized Controlled Trials(RCTs). However, observational data suffer from inherent missing counterfactual outcomes, and distribution discrepancy between treatment and control groups due to behaviour preference. Motivated by recent advances of representation learning in the field of domain adaptation, we propose a novel framework based on Cycle-Balanced REpresentation learning for counterfactual inference (CBRE), to solve above problems. Specifically, we realize a robust balanced representation for different groups using adversarial training, and meanwhile construct an information loop, such that preserve original data properties cyclically, which reduces information loss when transforming data into latent representation space.Experimental results on three real-world datasets demonstrate that CBRE matches/outperforms the state-of-the-art methods, and it has a great potential to be applied to counterfactual inference.
A Survey of Deep Reinforcement Learning in Recommender Systems: A Systematic Review and Future Directions
Sep 09, 2021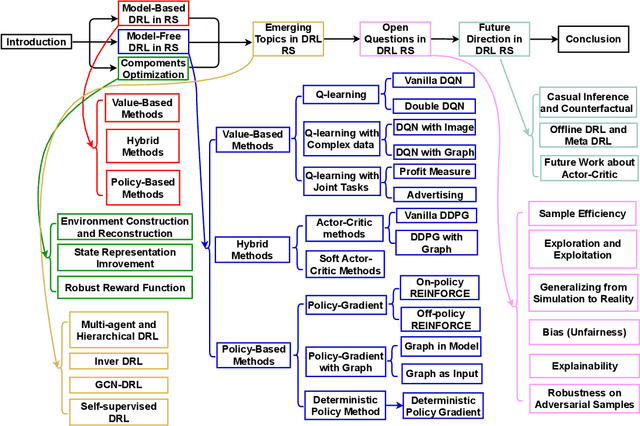

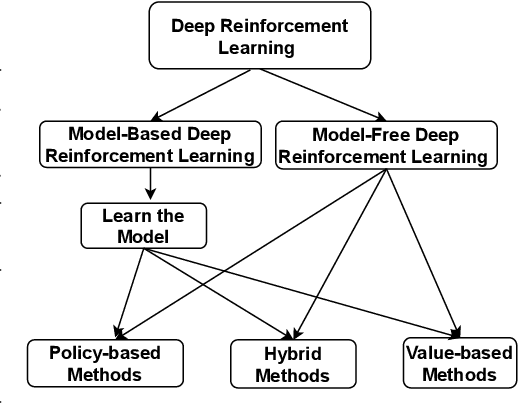
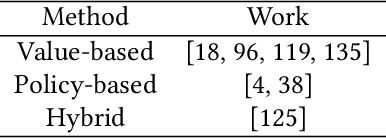
In light of the emergence of deep reinforcement learning (DRL) in recommender systems research and several fruitful results in recent years, this survey aims to provide a timely and comprehensive overview of the recent trends of deep reinforcement learning in recommender systems. We start with the motivation of applying DRL in recommender systems. Then, we provide a taxonomy of current DRL-based recommender systems and a summary of existing methods. We discuss emerging topics and open issues, and provide our perspective on advancing the domain. This survey serves as introductory material for readers from academia and industry into the topic and identifies notable opportunities for further research.