 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Teacher-Students for Deep Safe Semi-Supervised Learning under Class Mismatch
May 25, 2024
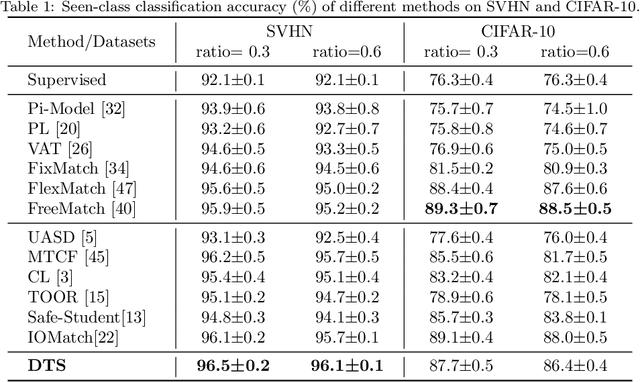
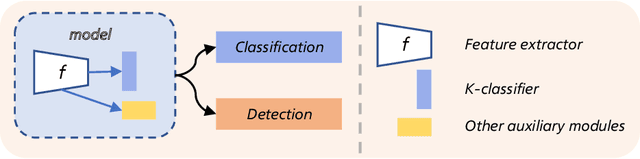
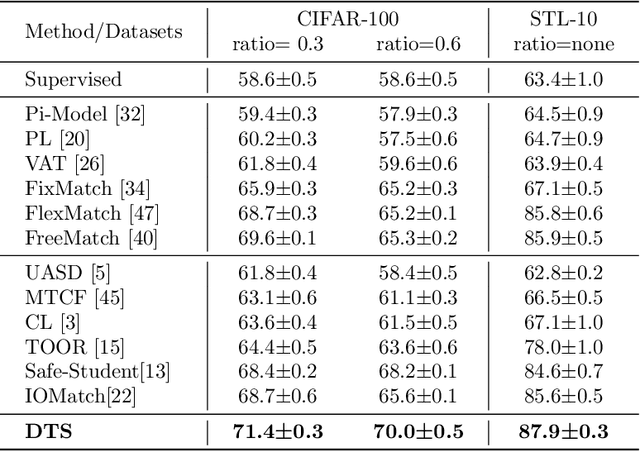
Semi-supervised learning can significantly boost model performance by leveraging unlabeled data, particularly when labeled data is scarce. However, real-world unlabeled data often contain unseen-class samples, which can hinder the classification of seen classes. To address this issue, mainstream safe SSL methods suggest detecting and discarding unseen-class samples from unlabeled data. Nevertheless, these methods typically employ a single-model strategy to simultaneously tackle both the classification of seen classes and the detection of unseen classes. Our research indicates that such an approach may lead to conflicts during training, resulting in suboptimal model optimization. Inspired by this, we introduce a novel framework named Diverse Teacher-Students (\textbf{DTS}), which uniquely utilizes dual teacher-student models to individually and effectively handle these two tasks. DTS employs a novel uncertainty score to softly separate unseen-class and seen-class data from the unlabeled set, and intelligently creates an additional ($K$+1)-th class supervisory signal for training. By training both teacher-student models with all unlabeled samples, DTS can enhance the classification of seen classes while simultaneously improving the detection of unseen classes. Comprehensive experiments demonstrate that DTS surpasses baseline methods across a variety of datasets and configurations. Our code and models can be publicly accessible on the link https://github.com/Zhanlo/DTS.
CLIP-driven Outliers Synthesis for few-shot OOD detection
Mar 30, 2024
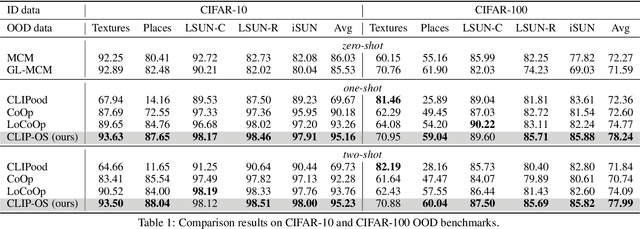
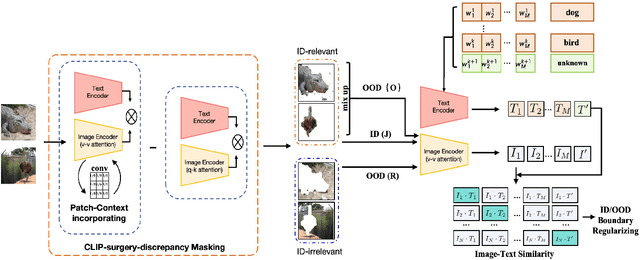
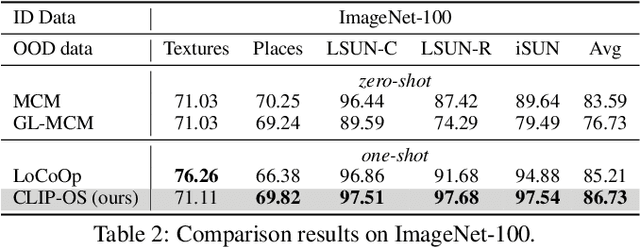
Few-shot OOD detection focuses on recognizing out-of-distribution (OOD) images that belong to classes unseen during training, with the use of only a small number of labeled in-distribution (ID) images. Up to now, a mainstream strategy is based on large-scale vision-language models, such as CLIP. However, these methods overlook a crucial issue: the lack of reliable OOD supervision information, which can lead to biased boundaries between in-distribution (ID) and OOD. To tackle this problem, we propose CLIP-driven Outliers Synthesis~(CLIP-OS). Firstly, CLIP-OS enhances patch-level features' perception by newly proposed patch uniform convolution, and adaptively obtains the proportion of ID-relevant information by employing CLIP-surgery-discrepancy, thus achieving separation between ID-relevant and ID-irrelevant. Next, CLIP-OS synthesizes reliable OOD data by mixing up ID-relevant features from different classes to provide OOD supervision information. Afterward, CLIP-OS leverages synthetic OOD samples by unknown-aware prompt learning to enhance the separability of ID and OOD. Extensive experiments across multiple benchmarks demonstrate that CLIP-OS achieves superior few-shot OOD detection capability.
How Well Does GPT-4V Adapt to Distribution Shifts? A Preliminary Investigation
Dec 13, 2023



In machine learning, generalization against distribution shifts -- where deployment conditions diverge from the training scenarios -- is crucial, particularly in fields like climate modeling, biomedicine, and autonomous driving. The emergence of foundation models, distinguished by their extensive pretraining and task versatility, has led to an increased interest in their adaptability to distribution shifts. GPT-4V(ision) acts as the most advanced publicly accessible multimodal foundation model, with extensive applications across various domains, including anomaly detection, video understanding, image generation, and medical diagnosis. However, its robustness against data distributions remains largely underexplored. Addressing this gap, this study rigorously evaluates GPT-4V's adaptability and generalization capabilities in dynamic environments, benchmarking against prominent models like CLIP and LLaVA. We delve into GPT-4V's zero-shot generalization across 13 diverse datasets spanning natural, medical, and molecular domains. We further investigate its adaptability to controlled data perturbations and examine the efficacy of in-context learning as a tool to enhance its adaptation. Our findings delineate GPT-4V's capability boundaries in distribution shifts, shedding light on its strengths and limitations across various scenarios. Importantly, this investigation contributes to our understanding of how AI foundation models generalize to distribution shifts, offering pivotal insights into their adaptability and robustness. Code is publicly available at https://github.com/jameszhou-gl/gpt-4v-distribution-shift.
Topological Structure Learning for Weakly-Supervised Out-of-Distribution Detection
Sep 16, 2022



Out-of-distribution (OOD) detection is the key to deploying models safely in the open world. For OOD detection, collecting sufficient in-distribution (ID) labeled data is usually more time-consuming and costly than unlabeled data. When ID labeled data is limited, the previous OOD detection methods are no longer superior due to their high dependence on the amount of ID labeled data. Based on limited ID labeled data and sufficient unlabeled data, we define a new setting called Weakly-Supervised Out-of-Distribution Detection (WSOOD). To solve the new problem, we propose an effective method called Topological Structure Learning (TSL). Firstly, TSL uses a contrastive learning method to build the initial topological structure space for ID and OOD data. Secondly, TSL mines effective topological connections in the initial topological space. Finally, based on limited ID labeled data and mined topological connections, TSL reconstructs the topological structure in a new topological space to increase the separability of ID and OOD instances. Extensive studies on several representative datasets show that TSL remarkably outperforms the state-of-the-art, verifying the validity and robustness of our method in the new setting of WSOOD.