 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaDA2.0: Scaling Up Diffusion Language Models to 100B
Dec 24, 2025This paper presents LLaDA2.0 -- a tuple of discrete diffusion large language models (dLLM) scaling up to 100B total parameters through systematic conversion from auto-regressive (AR) models -- establishing a new paradigm for frontier-scale deployment. Instead of costly training from scratch, LLaDA2.0 upholds knowledge inheritance, progressive adaption and efficiency-aware design principle, and seamless converts a pre-trained AR model into dLLM with a novel 3-phase block-level WSD based training scheme: progressive increasing block-size in block diffusion (warm-up), large-scale full-sequence diffusion (stable) and reverting back to compact-size block diffusion (decay). Along with post-training alignment with SFT and DPO, we obtain LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B), two instruction-tuned Mixture-of-Experts (MoE) variants optimized for practical deployment. By preserving the advantages of parallel decoding, these models deliver superior performance and efficiency at the frontier scale. Both models were open-sourced.
Knocking-Heads Attention
Oct 27, 2025Multi-head attention (MHA) has become the cornerstone of modern large language models, enhancing representational capacity through parallel attention heads. However, increasing the number of heads inherently weakens individual head capacity, and existing attention mechanisms - whether standard MHA or its variants like grouped-query attention (GQA) and grouped-tied attention (GTA) - simply concatenate outputs from isolated heads without strong interaction. To address this limitation, we propose knocking-heads attention (KHA), which enables attention heads to "knock" on each other - facilitating cross-head feature-level interactions before the scaled dot-product attention. This is achieved by applying a shared, diagonally-initialized projection matrix across all heads. The diagonal initialization preserves head-specific specialization at the start of training while allowing the model to progressively learn integrated cross-head representations. KHA adds only minimal parameters and FLOPs and can be seamlessly integrated into MHA, GQA, GTA, and other attention variants. We validate KHA by training a 6.1B parameter MoE model (1.01B activated) on 1T high-quality tokens. Compared to baseline attention mechanisms, KHA brings superior and more stable training dynamics, achieving better performance across downstream tasks.
Grove MoE: Towards Efficient and Superior MoE LLMs with Adjugate Experts
Aug 11, 2025The Mixture of Experts (MoE) architecture is a cornerstone of modern state-of-the-art (SOTA) large language models (LLMs). MoE models facilitate scalability by enabling sparse parameter activation. However, traditional MoE architecture uses homogeneous experts of a uniform size, activating a fixed number of parameters irrespective of input complexity and thus limiting computational efficiency. To overcome this limitation, we introduce Grove MoE, a novel architecture incorporating experts of varying sizes, inspired by the heterogeneous big.LITTLE CPU architecture. This architecture features novel adjugate experts with a dynamic activation mechanism, enabling model capacity expansion while maintaining manageable computational overhead. Building on this architecture, we present GroveMoE-Base and GroveMoE-Inst, 33B-parameter LLMs developed by applying an upcycling strategy to the Qwen3-30B-A3B-Base model during mid-training and post-training. GroveMoE models dynamically activate 3.14-3.28B parameters based on token complexity and achieve performance comparable to SOTA open-source models of similar or even larger size.
UBER: Uncertainty-Based Evolution with Large Language Models for Automatic Heuristic Design
Dec 30, 2024



NP-hard problem-solving traditionally relies on heuristics, but manually crafting effective heuristics for complex problems remains challenging. While recent work like FunSearch has demonstrated that large language models (LLMs) can be leveraged for heuristic design in evolutionary algorithm (EA) frameworks, their potential is not fully realized due to its deficiency in exploitation and exploration. We present UBER (Uncertainty-Based Evolution for Refinement), a method that enhances LLM+EA methods for automatic heuristic design by integrating uncertainty on top of the FunSearch framework. UBER introduces two key innovations: an Uncertainty-Inclusive Evolution Process (UIEP) for adaptive exploration-exploitation balance, and a principled Uncertainty-Inclusive Island Reset (UIIS) strategy for maintaining population diversity. Through extensive experiments on challenging NP-complete problems, UBER demonstrates significant improvements over FunSearch. Our work provides a new direction for the synergy of LLMs and EA, advancing the field of automatic heuristic design.
Value Residual Learning For Alleviating Attention Concentration In Transformers
Oct 23, 2024Transformers can capture long-range dependencies using self-attention, allowing tokens to attend to all others directly. However, stacking multiple attention layers leads to attention concentration. One natural way to address this issue is to use cross-layer attention, allowing information from earlier layers to be directly accessible to later layers. However, this approach is computationally expensive. To address this problem, we propose Transformer with residual value (ResFormer) which approximates cross-layer attention through adding a residual connection from the values of the the first layer to all subsequent layers. Based on this method, one variant is the Transformer with single layer value (SVFormer), where all layers share the same value embedding from first layer, reducing the KV cache by nearly 50%. Comprehensive empirical evidence demonstrates that ResFormer mitigates attention concentration problem in deeper layers and enhances representation across most layers, outperforming the vanilla Transformer, DenseFormer, and NeuTRENO in training error as well as downstream tasks. SVFormer trains significantly faster than the vanilla Transformer and performs better than other methods like GQA and CLA, with performance influenced by sequence length and cumulative learning rate.
Dynamics of Instruction Tuning: Each Ability of Large Language Models Has Its Own Growth Pace
Oct 30, 2023


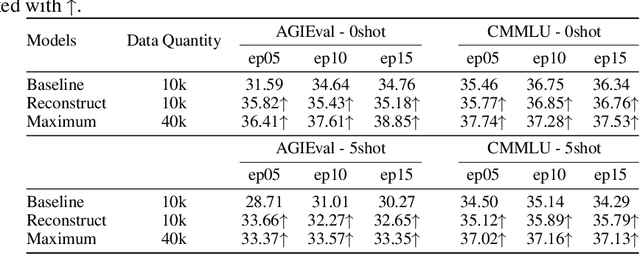
Instruction tuning is a burgeoning method to elicit the general intelligence of Large Language Models (LLMs). However, the creation of instruction data is still largely heuristic, leading to significant variation in quality and distribution across existing datasets. Experimental conclusions drawn from these datasets are also inconsistent, with some studies emphasizing the importance of scaling instruction numbers, while others argue that a limited number of samples suffice. To better understand data construction guidelines, we deepen our focus from the overall model performance to the growth of each underlying ability, such as creative writing, code generation, and logical reasoning. We systematically investigate the effects of data volume, parameter size, and data construction methods on the development of various abilities, using hundreds of model checkpoints (7b to 33b) fully instruction-tuned on a new collection of over 40k human-curated instruction data. This proposed dataset is stringently quality-controlled and categorized into ten distinct LLM abilities. Our study reveals three primary findings: (i) Despite data volume and parameter scale directly impacting models' overall performance, some abilities are more responsive to their increases and can be effectively trained using limited data, while some are highly resistant to these changes. (ii) Human-curated data strongly outperforms synthetic data from GPT-4 in efficiency and can constantly enhance model performance with volume increases, but is unachievable with synthetic data. (iii) Instruction data brings powerful cross-ability generalization, with evaluation results on out-of-domain data mirroring the first two observations. Furthermore, we demonstrate how these findings can guide more efficient data constructions, leading to practical performance improvements on public benchmarks.