 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics of Instruction Tuning: Each Ability of Large Language Models Has Its Own Growth Pace
Oct 30, 2023


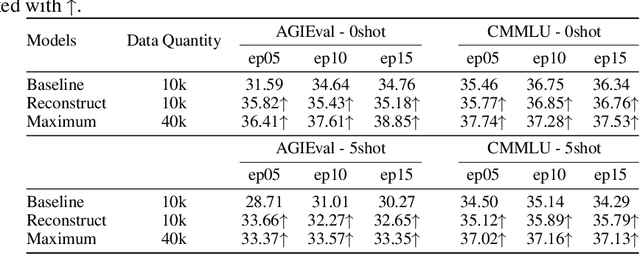
Instruction tuning is a burgeoning method to elicit the general intelligence of Large Language Models (LLMs). However, the creation of instruction data is still largely heuristic, leading to significant variation in quality and distribution across existing datasets. Experimental conclusions drawn from these datasets are also inconsistent, with some studies emphasizing the importance of scaling instruction numbers, while others argue that a limited number of samples suffice. To better understand data construction guidelines, we deepen our focus from the overall model performance to the growth of each underlying ability, such as creative writing, code generation, and logical reasoning. We systematically investigate the effects of data volume, parameter size, and data construction methods on the development of various abilities, using hundreds of model checkpoints (7b to 33b) fully instruction-tuned on a new collection of over 40k human-curated instruction data. This proposed dataset is stringently quality-controlled and categorized into ten distinct LLM abilities. Our study reveals three primary findings: (i) Despite data volume and parameter scale directly impacting models' overall performance, some abilities are more responsive to their increases and can be effectively trained using limited data, while some are highly resistant to these changes. (ii) Human-curated data strongly outperforms synthetic data from GPT-4 in efficiency and can constantly enhance model performance with volume increases, but is unachievable with synthetic data. (iii) Instruction data brings powerful cross-ability generalization, with evaluation results on out-of-domain data mirroring the first two observations. Furthermore, we demonstrate how these findings can guide more efficient data constructions, leading to practical performance improvements on public benchmarks.
Understanding In-Context Learning from Repetitions
Oct 10, 2023

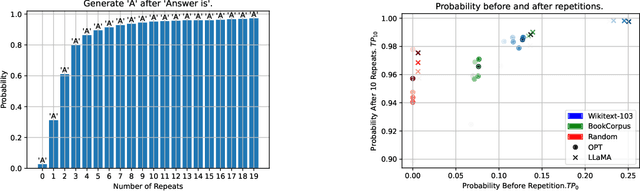

This paper explores the elusive mechanism underpinning in-context learning in Large Language Models (LLMs). Our work provides a novel perspective by examining in-context learning via the lens of surface repetitions. We quantitatively investigate the role of surface features in text generation, and empirically establish the existence of \emph{token co-occurrence reinforcement}, a principle that strengthens the relationship between two tokens based on their contextual co-occurrences. By investigating the dual impacts of these features, our research illuminates the internal workings of in-context learning and expounds on the reasons for its failures. This paper provides an essential contribution to the understanding of in-context learning and its potential limitations, providing a fresh perspective on this exciting capability.
Global-Selector: A New Benchmark Dataset and Model Architecture for Multi-turn Response Selection
Jun 02, 2021



As an essential component of dialogue systems, multi-turn response selection aims to pick out the optimal response among a set of candidates to improve the dialogue fluency. In this paper, we investigate three problems of current response selection approaches, especially for generation-based conversational agents: (i) Existing approaches are often formulated as a sentence scoring problem, which does not consider relationships between responses. (ii) Existing models tend to select undesirable candidates that have large overlaps with the dialogue history. (iii) Negative instances in training are mainly constructed by random sampling from the corpus, whereas generated candidates in practice typically have a closer distribution. To address the above problems, we create a new dataset called ConvAI2+ and propose a new response selector called Global-Selector. Experimental results show that Global-Selector trained on ConvAI2+ have noticeable improvements in both accuracy and inference speed.