 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics of Instruction Tuning: Each Ability of Large Language Models Has Its Own Growth Pace
Oct 30, 2023


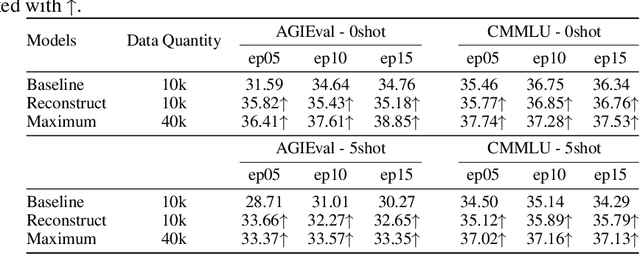
Instruction tuning is a burgeoning method to elicit the general intelligence of Large Language Models (LLMs). However, the creation of instruction data is still largely heuristic, leading to significant variation in quality and distribution across existing datasets. Experimental conclusions drawn from these datasets are also inconsistent, with some studies emphasizing the importance of scaling instruction numbers, while others argue that a limited number of samples suffice. To better understand data construction guidelines, we deepen our focus from the overall model performance to the growth of each underlying ability, such as creative writing, code generation, and logical reasoning. We systematically investigate the effects of data volume, parameter size, and data construction methods on the development of various abilities, using hundreds of model checkpoints (7b to 33b) fully instruction-tuned on a new collection of over 40k human-curated instruction data. This proposed dataset is stringently quality-controlled and categorized into ten distinct LLM abilities. Our study reveals three primary findings: (i) Despite data volume and parameter scale directly impacting models' overall performance, some abilities are more responsive to their increases and can be effectively trained using limited data, while some are highly resistant to these changes. (ii) Human-curated data strongly outperforms synthetic data from GPT-4 in efficiency and can constantly enhance model performance with volume increases, but is unachievable with synthetic data. (iii) Instruction data brings powerful cross-ability generalization, with evaluation results on out-of-domain data mirroring the first two observations. Furthermore, we demonstrate how these findings can guide more efficient data constructions, leading to practical performance improvements on public benchmarks.
Enhancing Grammatical Error Correction Systems with Explanations
May 25, 2023Grammatical error correction systems improve written communication by detecting and correcting language mistakes. To help language learners better understand why the GEC system makes a certain correction, the causes of errors (evidence words) and the corresponding error types are two key factors. To enhance GEC systems with explanations, we introduce EXPECT, a large dataset annotated with evidence words and grammatical error types. We propose several baselines and anlysis to understand this task. Furthermore, human evaluation verifies our explainable GEC system's explanations can assist second-language learners in determining whether to accept a correction suggestion and in understanding the associated grammar rule.
Deep Robotic Prediction with hierarchical RGB-D Fusion
Sep 17, 2019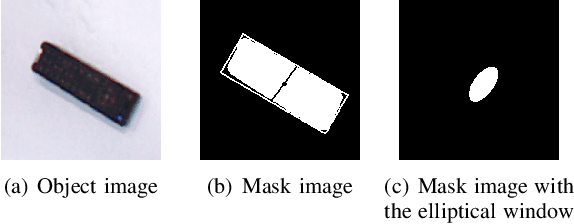
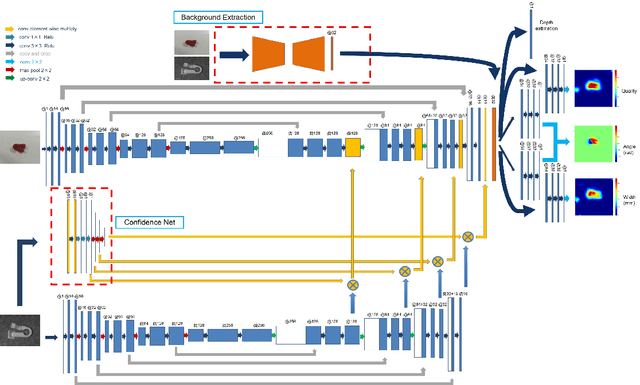


Robotic arm grasping is a fundamental operation in robotic control task goals. Most current methods for robotic grasping focus on RGB-D policy in the table surface scenario or 3D point cloud analysis and inference in the 3D space. Comparing to these methods, we propose a novel real-time multimodal hierarchical encoder-decoder neural network that fuses RGB and depth data to realize robotic humanoid grasping in 3D space with only partial observation. The quantification of raw depth data's uncertainty and depth estimation fusing RGB is considered. We develop a general labeling method to label ground-truth on common RGB-D datasets. We evaluate the effectiveness and performance of our method on a physical robot setup and our method achieves over 90\% success rate in both table surface and 3D space scenarios.