 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Robotic Prediction with hierarchical RGB-D Fusion
Paper and Code
Sep 17, 2019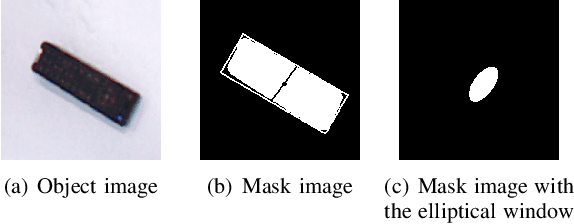
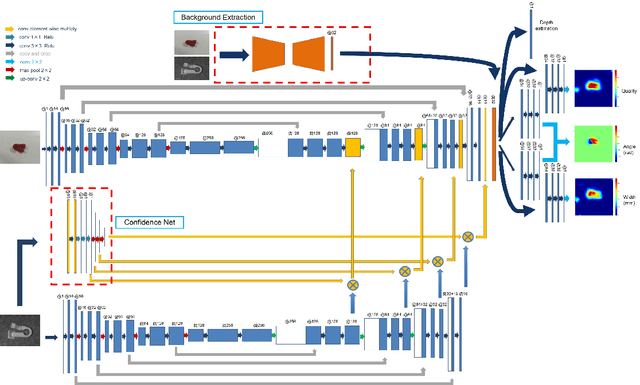


Robotic arm grasping is a fundamental operation in robotic control task goals. Most current methods for robotic grasping focus on RGB-D policy in the table surface scenario or 3D point cloud analysis and inference in the 3D space. Comparing to these methods, we propose a novel real-time multimodal hierarchical encoder-decoder neural network that fuses RGB and depth data to realize robotic humanoid grasping in 3D space with only partial observation. The quantification of raw depth data's uncertainty and depth estimation fusing RGB is considered. We develop a general labeling method to label ground-truth on common RGB-D datasets. We evaluate the effectiveness and performance of our method on a physical robot setup and our method achieves over 90\% success rate in both table surface and 3D space scenarios.