 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Clustering: A Comprehensive Survey
Oct 09, 2022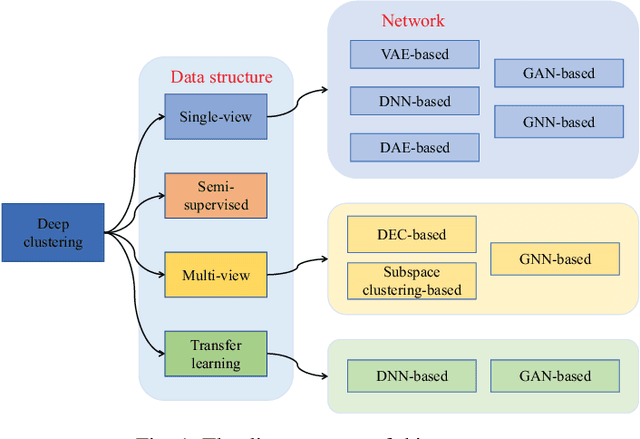
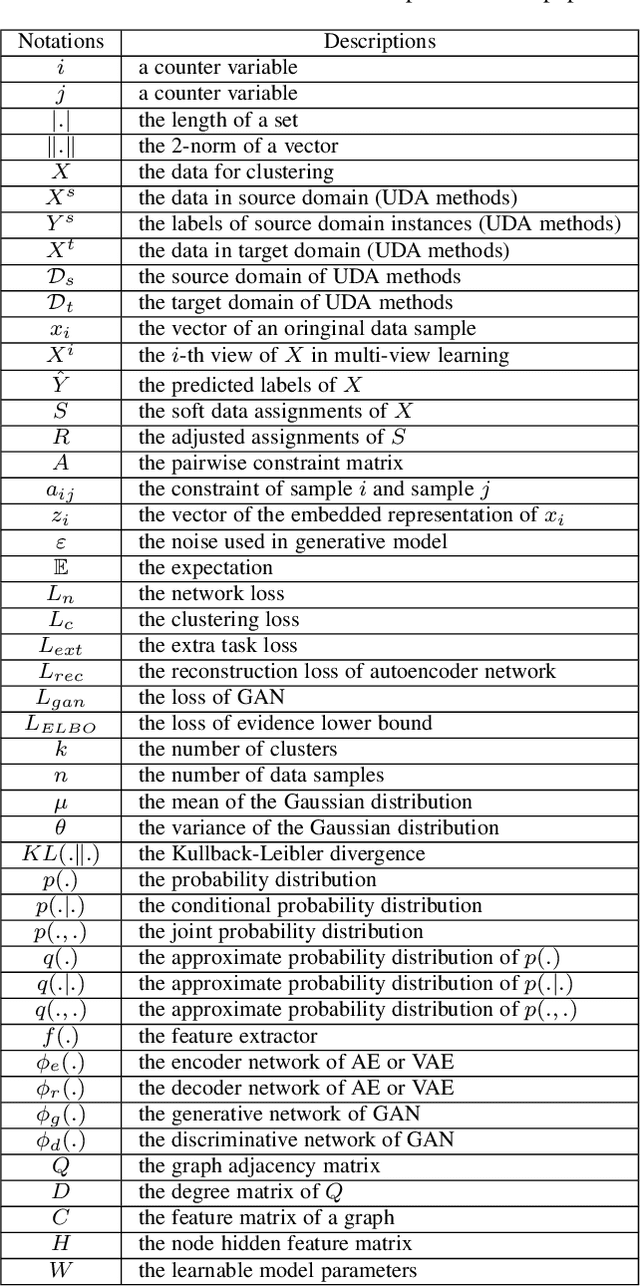
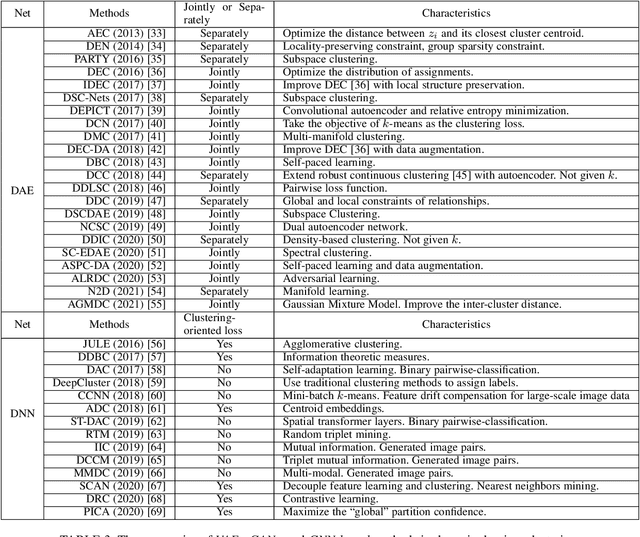
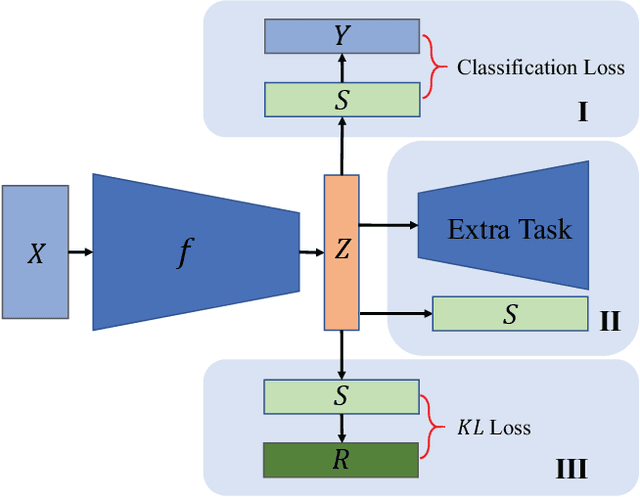
Cluster analysis plays an indispensable role in machine learning and data mining. Learning a good data representation is crucial for clustering algorithms. Recently, deep clustering, which can learn clustering-friendly representations using deep neural networks, has been broadly applied in a wide range of clustering tasks. Existing surveys for deep clustering mainly focus on the single-view fields and the network architectures, ignoring the complex application scenarios of clustering. To address this issue, in this paper we provide a comprehensive survey for deep clustering in views of data sources. With different data sources and initial conditions, we systematically distinguish the clustering methods in terms of methodology, prior knowledge, and architecture. Concretely, deep clustering methods are introduced according to four categories, i.e., traditional single-view deep clustering, semi-supervised deep clustering, deep multi-view clustering, and deep transfer clustering. Finally, we discuss the open challenges and potential future opportunities in different fields of deep clustering.
Self-supervised Discriminative Feature Learning for Multi-view Clustering
Mar 28, 2021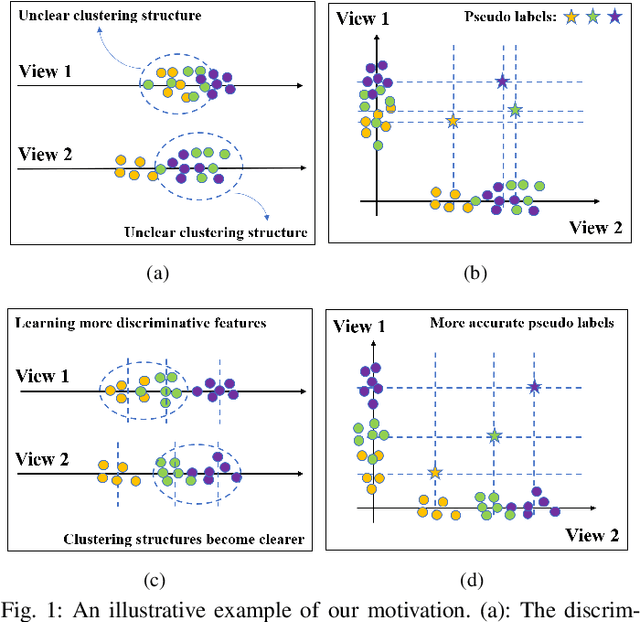
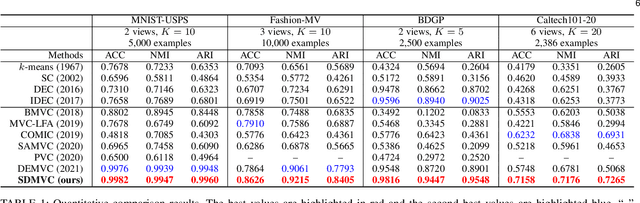
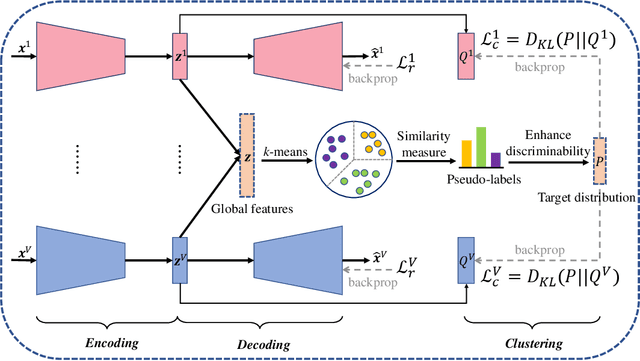
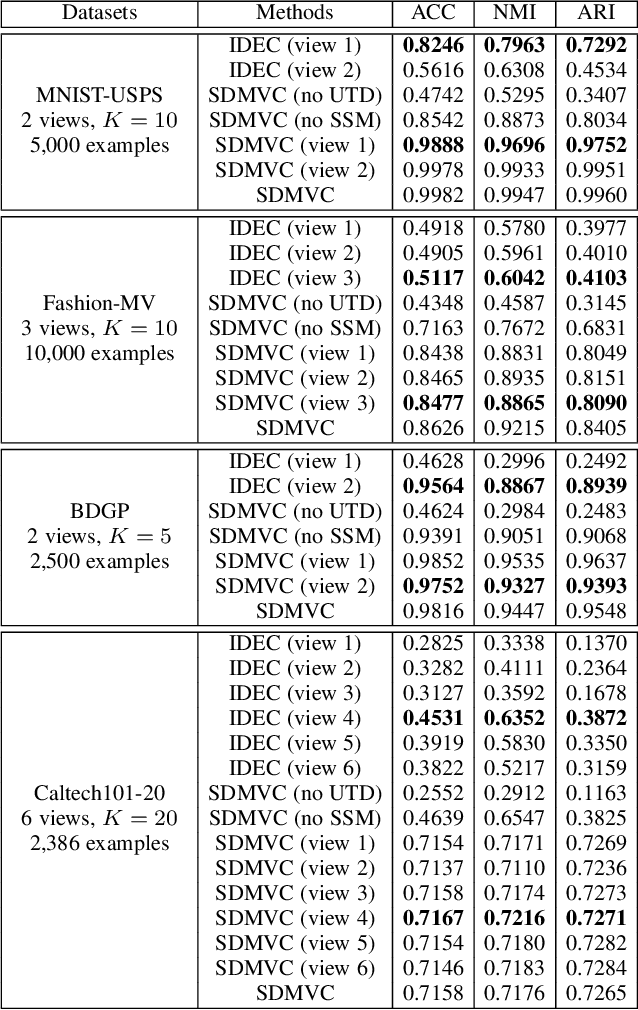
Multi-view clustering is an important research topic due to its capability to utilize complementary information from multiple views. However, there are few methods to consider the negative impact caused by certain views with unclear clustering structures, resulting in poor multi-view clustering performance. To address this drawback, we propose self-supervised discriminative feature learning for multi-view clustering (SDMVC). Concretely, deep autoencoders are applied to learn embedded features for each view independently. To leverage the multi-view complementary information, we concatenate all views' embedded features to form the global features, which can overcome the negative impact of some views' unclear clustering structures. In a self-supervised manner, pseudo-labels are obtained to build a unified target distribution to perform multi-view discriminative feature learning. During this process, global discriminative information can be mined to supervise all views to learn more discriminative features, which in turn are used to update the target distribution. Besides, this unified target distribution can make SDMVC learn consistent cluster assignments, which accomplishes the clustering consistency of multiple views while preserving their features' diversity. Experiments on various types of multi-view datasets show that SDMVC achieves state-of-the-art performance.