 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Approach for Effective Multi-View Clustering with Information-Theoretic Perspective
Sep 25, 2023



Multi-view clustering (MVC) is a popular technique for improving clustering performance using various data sources. However, existing methods primarily focus on acquiring consistent information while often neglecting the issue of redundancy across multiple views. This study presents a new approach called Sufficient Multi-View Clustering (SUMVC) that examines the multi-view clustering framework from an information-theoretic standpoint. Our proposed method consists of two parts. Firstly, we develop a simple and reliable multi-view clustering method SCMVC (simple consistent multi-view clustering) that employs variational analysis to generate consistent information. Secondly, we propose a sufficient representation lower bound to enhance consistent information and minimise unnecessary information among views. The proposed SUMVC method offers a promising solution to the problem of multi-view clustering and provides a new perspective for analyzing multi-view data. To verify the effectiveness of our model, we conducted a theoretical analysis based on the Bayes Error Rate, and experiments on multiple multi-view datasets demonstrate the superior performance of SUMVC.
Deep Multi-View Subspace Clustering with Anchor Graph
May 11, 2023



Deep multi-view subspace clustering (DMVSC) has recently attracted increasing attention due to its promising performance. However, existing DMVSC methods still have two issues: (1) they mainly focus on using autoencoders to nonlinearly embed the data, while the embedding may be suboptimal for clustering because the clustering objective is rarely considered in autoencoders, and (2) existing methods typically have a quadratic or even cubic complexity, which makes it challenging to deal with large-scale data. To address these issues, in this paper we propose a novel deep multi-view subspace clustering method with anchor graph (DMCAG). To be specific, DMCAG firstly learns the embedded features for each view independently, which are used to obtain the subspace representations. To significantly reduce the complexity, we construct an anchor graph with small size for each view. Then, spectral clustering is performed on an integrated anchor graph to obtain pseudo-labels. To overcome the negative impact caused by suboptimal embedded features, we use pseudo-labels to refine the embedding process to make it more suitable for the clustering task. Pseudo-labels and embedded features are updated alternately. Furthermore, we design a strategy to keep the consistency of the labels based on contrastive learning to enhance the clustering performance. Empirical studies on real-world datasets show that our method achieves superior clustering performance over other state-of-the-art methods.
Deep Clustering: A Comprehensive Survey
Oct 09, 2022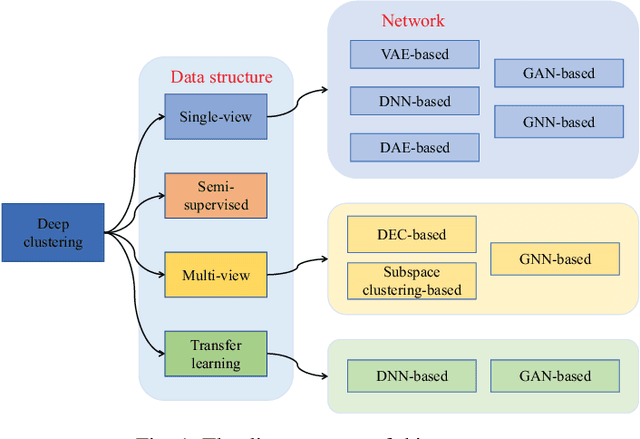
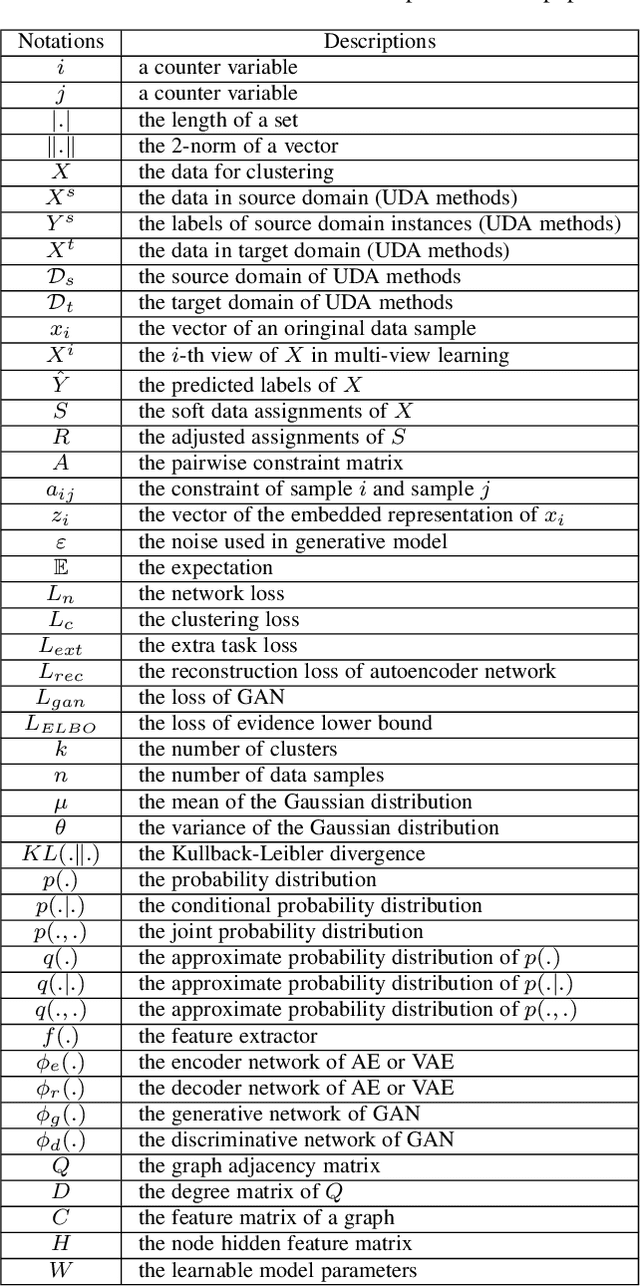
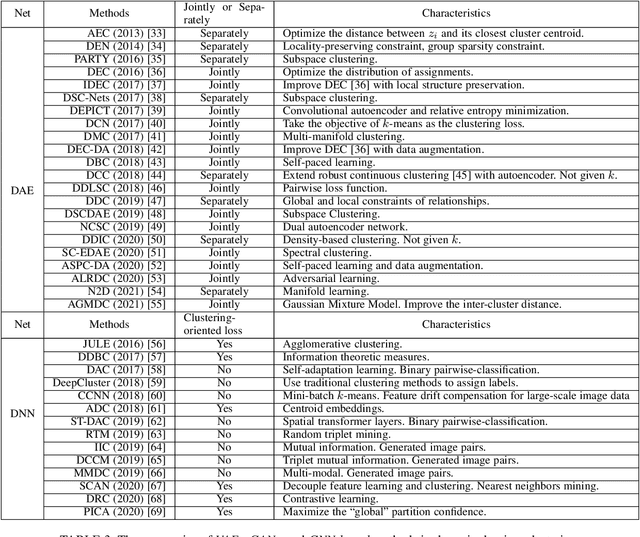
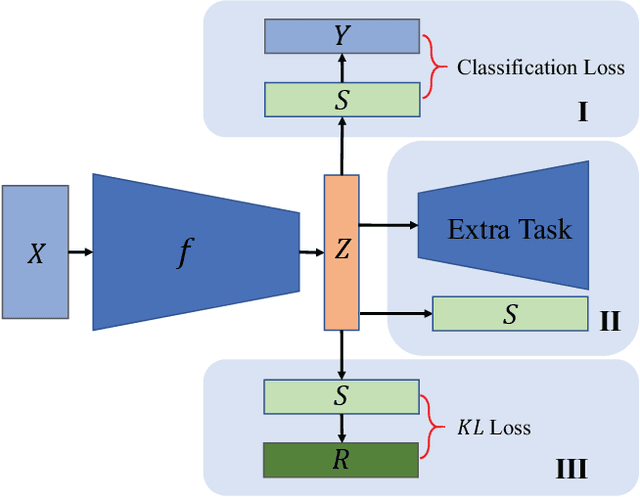
Cluster analysis plays an indispensable role in machine learning and data mining. Learning a good data representation is crucial for clustering algorithms. Recently, deep clustering, which can learn clustering-friendly representations using deep neural networks, has been broadly applied in a wide range of clustering tasks. Existing surveys for deep clustering mainly focus on the single-view fields and the network architectures, ignoring the complex application scenarios of clustering. To address this issue, in this paper we provide a comprehensive survey for deep clustering in views of data sources. With different data sources and initial conditions, we systematically distinguish the clustering methods in terms of methodology, prior knowledge, and architecture. Concretely, deep clustering methods are introduced according to four categories, i.e., traditional single-view deep clustering, semi-supervised deep clustering, deep multi-view clustering, and deep transfer clustering. Finally, we discuss the open challenges and potential future opportunities in different fields of deep clustering.