 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeltaLM: Encoder-Decoder Pre-training for Language Generation and Translation by Augmenting Pretrained Multilingual Encoders
Paper and Code
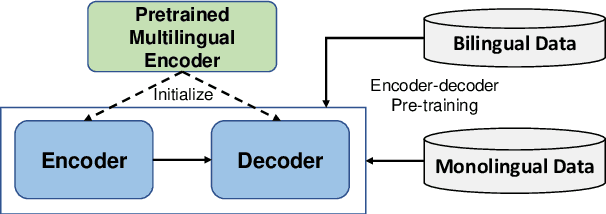

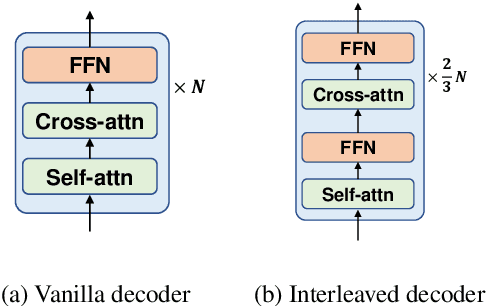
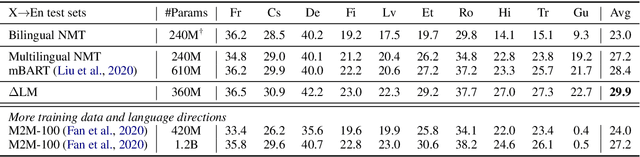
While pretrained encoders have achieved success in various natural language understanding (NLU) tasks, there is a gap between these pretrained encoders and natural language generation (NLG). NLG tasks are often based on the encoder-decoder framework, where the pretrained encoders can only benefit part of it. To reduce this gap, we introduce DeltaLM, a pretrained multilingual encoder-decoder model that regards the decoder as the task layer of off-the-shelf pretrained encoders. Specifically, we augment the pretrained multilingual encoder with a decoder and pre-train it in a self-supervised way. To take advantage of both the large-scale monolingual data and bilingual data, we adopt the span corruption and translation span corruption as the pre-training tasks. Experiments show that DeltaLM outperforms various strong baselines on both natural language generation and translation tasks, including machine translation, abstractive text summarization, data-to-text, and question generation.