 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Test-Time Compute Allocation via Learned Heuristics over Categorical Structure
Feb 03, 2026Test-time computation has become a primary driver of progress in large language model (LLM) reasoning, but it is increasingly bottlenecked by expensive verification. In many reasoning systems, a large fraction of verifier calls are spent on redundant or unpromising intermediate hypotheses. We study reasoning under a \emph{verification-cost-limited} setting and ask how verification effort should be allocated across intermediate states. We propose a state-level selective verification framework that combines (i) deterministic feasibility gating over a structured move interface, (ii) pre-verification ranking using a hybrid of learned state-distance and residual scoring, and (iii) adaptive allocation of verifier calls based on local uncertainty. Unlike solution-level best-of-$N$ or uniform intermediate verification, our method distributes verification where it is most informative. On the \textsc{MATH} benchmark, our approach achieves higher accuracy than best-of-$N$, majority voting, and beam search while using 44\% fewer verifier calls.
Active Epistemic Control for Query-Efficient Verified Planning
Feb 03, 2026Planning in interactive environments is challenging under partial observability: task-critical preconditions (e.g., object locations or container states) may be unknown at decision time, yet grounding them through interaction is costly. Learned world models can cheaply predict missing facts, but prediction errors can silently induce infeasible commitments. We present \textbf{Active Epistemic Control (AEC)}, an epistemic-categorical planning layer that integrates model-based belief management with categorical feasibility checks. AEC maintains a strict separation between a \emph{grounded fact store} used for commitment and a \emph{belief store} used only for pruning candidate plans. At each step, it either queries the environment to ground an unresolved predicate when uncertainty is high or predictions are ambiguous, or simulates the predicate to filter hypotheses when confidence is sufficient. Final commitment is gated by grounded precondition coverage and an SQ-BCP pullback-style compatibility check, so simulated beliefs affect efficiency but cannot directly certify feasibility. Experiments on ALFWorld and ScienceWorld show that AEC achieves competitive success with fewer replanning rounds than strong LLM-agent baselines.
Fuzzy Categorical Planning: Autonomous Goal Satisfaction with Graded Semantic Constraints
Jan 27, 2026Natural-language planning often involves vague predicates (e.g., suitable substitute, stable enough) whose satisfaction is inherently graded. Existing category-theoretic planners provide compositional structure and pullback-based hard-constraint verification, but treat applicability as crisp, forcing thresholding that collapses meaningful distinctions and cannot track quality degradation across multi-step plans. We propose Fuzzy Category-theoretic Planning (FCP), which annotates each action (morphism) with a degree in [0,1], composes plan quality via a t-norm Lukasiewicz, and retains crisp executability checks via pullback verification. FCP grounds graded applicability from language using an LLM with k-sample median aggregation and supports meeting-in-the-middle search using residuum-based backward requirements. We evaluate on (i) public PDDL3 preference/oversubscription benchmarks and (ii) RecipeNLG-Subs, a missing-substitute recipe-planning benchmark built from RecipeNLG with substitution candidates from Recipe1MSubs and FoodKG. FCP improves success and reduces hard-constraint violations on RecipeNLG-Subs compared to LLM-only and ReAct-style baselines, while remaining competitive with classical PDDL3 planners.
Teaching LLMs to Ask: Self-Querying Category-Theoretic Planning for Under-Specified Reasoning
Jan 27, 2026Inference-time planning with large language models frequently breaks under partial observability: when task-critical preconditions are not specified at query time, models tend to hallucinate missing facts or produce plans that violate hard constraints. We introduce \textbf{Self-Querying Bidirectional Categorical Planning (SQ-BCP)}, which explicitly represents precondition status (\texttt{Sat}/\texttt{Viol}/\texttt{Unk}) and resolves unknowns via (i) targeted self-queries to an oracle/user or (ii) \emph{bridging} hypotheses that establish the missing condition through an additional action. SQ-BCP performs bidirectional search and invokes a pullback-based verifier as a categorical certificate of goal compatibility, while using distance-based scores only for ranking and pruning. We prove that when the verifier succeeds and hard constraints pass deterministic checks, accepted plans are compatible with goal requirements; under bounded branching and finite resolution depth, SQ-BCP finds an accepting plan when one exists. Across WikiHow and RecipeNLG tasks with withheld preconditions, SQ-BCP reduces resource-violation rates to \textbf{14.9\%} and \textbf{5.8\%} (vs.\ \textbf{26.0\%} and \textbf{15.7\%} for the best baseline), while maintaining competitive reference quality.
GoMS: Graph of Molecule Substructure Network for Molecule Property Prediction
Dec 13, 2025While graph neural networks have shown remarkable success in molecular property prediction, current approaches like the Equivariant Subgraph Aggregation Networks (ESAN) treat molecules as bags of independent substructures, overlooking crucial relationships between these components. We present Graph of Molecule Substructures (GoMS), a novel architecture that explicitly models the interactions and spatial arrangements between molecular substructures. Unlike ESAN's bag-based representation, GoMS constructs a graph where nodes represent subgraphs and edges capture their structural relationships, preserving critical topological information about how substructures are connected and overlap within the molecule. Through extensive experiments on public molecular datasets, we demonstrate that GoMS outperforms ESAN and other baseline methods, with particularly improvements for large molecules containing more than 100 atoms. The performance gap widens as molecular size increases, demonstrating GoMS's effectiveness for modeling industrial-scale molecules. Our theoretical analysis demonstrates that GoMS can distinguish molecules with identical subgraph compositions but different spatial arrangements. Our approach shows particular promise for materials science applications involving complex molecules where properties emerge from the interplay between multiple functional units. By capturing substructure relationships that are lost in bag-based approaches, GoMS represents a significant advance toward scalable and interpretable molecular property prediction for real-world applications.
Patch-aware Vector Quantized Codebook Learning for Unsupervised Visual Defect Detection
Jan 15, 2025


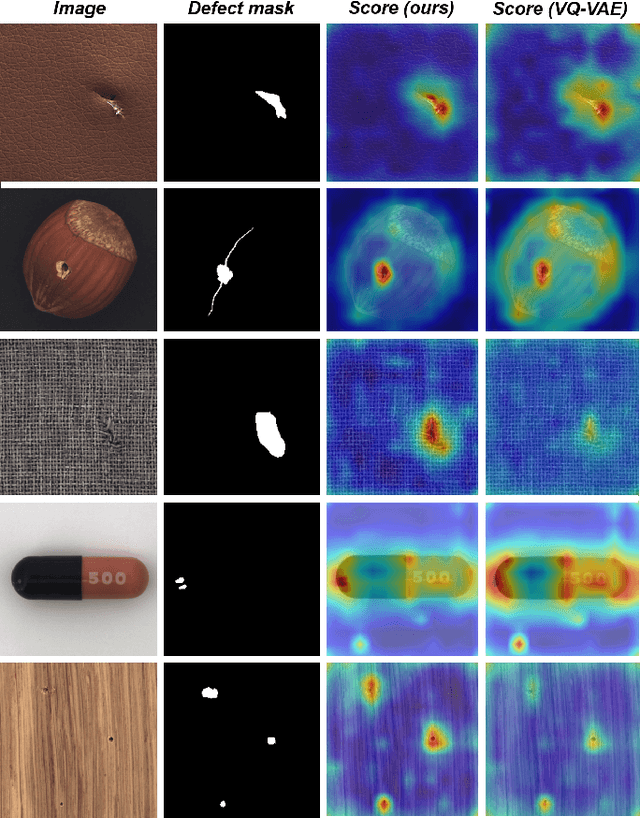
Unsupervised visual defect detection is critical in industrial applications, requiring a representation space that captures normal data features while detecting deviations. Achieving a balance between expressiveness and compactness is challenging; an overly expressive space risks inefficiency and mode collapse, impairing detection accuracy. We propose a novel approach using an enhanced VQ-VAE framework optimized for unsupervised defect detection. Our model introduces a patch-aware dynamic code assignment scheme, enabling context-sensitive code allocation to optimize spatial representation. This strategy enhances normal-defect distinction and improves detection accuracy during inference. Experiments on MVTecAD, BTAD, and MTSD datasets show our method achieves state-of-the-art performance.
Efficient Generation of Molecular Clusters with Dual-Scale Equivariant Flow Matching
Oct 10, 2024Amorphous molecular solids offer a promising alternative to inorganic semiconductors, owing to their mechanical flexibility and solution processability. The packing structure of these materials plays a crucial role in determining their electronic and transport properties, which are key to enhancing the efficiency of devices like organic solar cells (OSCs). However, obtaining these optoelectronic properties computationally requires molecular dynamics (MD) simulations to generate a conformational ensemble, a process that can be computationally expensive due to the large system sizes involved. Recent advances have focused on using generative models, particularly flow-based models as Boltzmann generators, to improve the efficiency of MD sampling. In this work, we developed a dual-scale flow matching method that separates training and inference into coarse-grained and all-atom stages and enhances both the accuracy and efficiency of standard flow matching samplers. We demonstrate the effectiveness of this method on a dataset of Y6 molecular clusters obtained through MD simulations, and we benchmark its efficiency and accuracy against single-scale flow matching methods.
SHAPNN: Shapley Value Regularized Tabular Neural Network
Sep 15, 2023We present SHAPNN, a novel deep tabular data modeling architecture designed for supervised learning. Our approach leverages Shapley values, a well-established technique for explaining black-box models. Our neural network is trained using standard backward propagation optimization methods, and is regularized with realtime estimated Shapley values. Our method offers several advantages, including the ability to provide valid explanations with no computational overhead for data instances and datasets. Additionally, prediction with explanation serves as a regularizer, which improves the model's performance. Moreover, the regularized prediction enhances the model's capability for continual learning. We evaluate our method on various publicly available datasets and compare it with state-of-the-art deep neural network models, demonstrating the superior performance of SHAPNN in terms of AUROC, transparency, as well as robustness to streaming data.
Error-aware Quantization through Noise Tempering
Dec 11, 2022



Quantization has become a predominant approach for model compression, enabling deployment of large models trained on GPUs onto smaller form-factor devices for inference. Quantization-aware training (QAT) optimizes model parameters with respect to the end task while simulating quantization error, leading to better performance than post-training quantization. Approximation of gradients through the non-differentiable quantization operator is typically achieved using the straight-through estimator (STE) or additive noise. However, STE-based methods suffer from instability due to biased gradients, whereas existing noise-based methods cannot reduce the resulting variance. In this work, we incorporate exponentially decaying quantization-error-aware noise together with a learnable scale of task loss gradient to approximate the effect of a quantization operator. We show this method combines gradient scale and quantization noise in a better optimized way, providing finer-grained estimation of gradients at each weight and activation layer's quantizer bin size. Our controlled noise also contains an implicit curvature term that could encourage flatter minima, which we show is indeed the case in our experiments. Experiments training ResNet architectures on the CIFAR-10, CIFAR-100 and ImageNet benchmarks show that our method obtains state-of-the-art top-1 classification accuracy for uniform (non mixed-precision) quantization, out-performing previous methods by 0.5-1.2% absolute.
SQuAT: Sharpness- and Quantization-Aware Training for BERT
Oct 13, 2022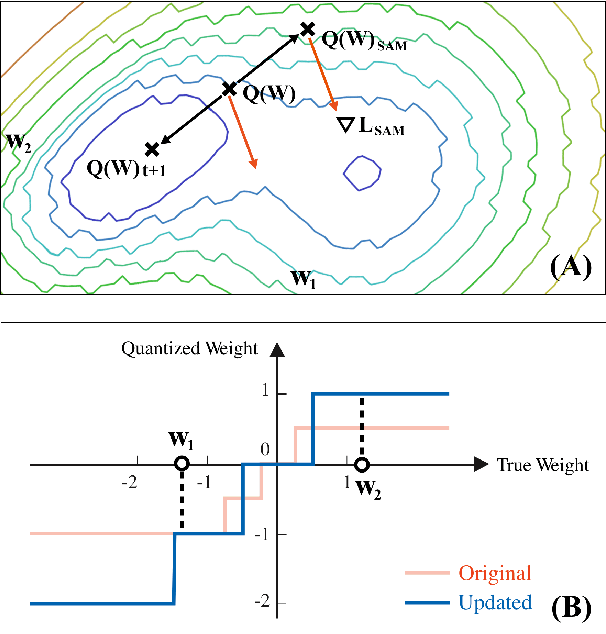
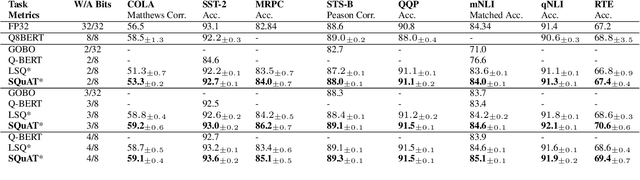
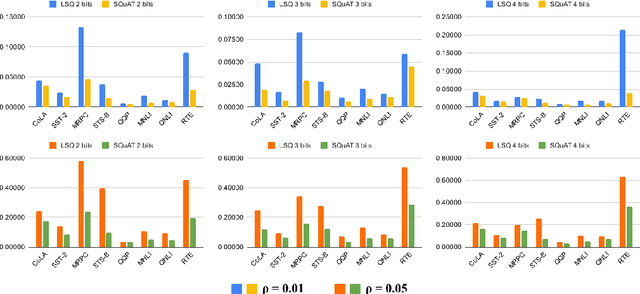
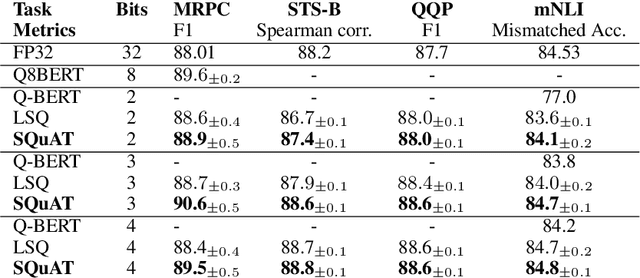
Quantization is an effective technique to reduce memory footprint, inference latency, and power consumption of deep learning models. However, existing quantization methods suffer from accuracy degradation compared to full-precision (FP) models due to the errors introduced by coarse gradient estimation through non-differentiable quantization layers. The existence of sharp local minima in the loss landscapes of overparameterized models (e.g., Transformers) tends to aggravate such performance penalty in low-bit (2, 4 bits) settings. In this work, we propose sharpness- and quantization-aware training (SQuAT), which would encourage the model to converge to flatter minima while performing quantization-aware training. Our proposed method alternates training between sharpness objective and step-size objective, which could potentially let the model learn the most suitable parameter update magnitude to reach convergence near-flat minima. Extensive experiments show that our method can consistently outperform state-of-the-art quantized BERT models under 2, 3, and 4-bit settings on GLUE benchmarks by 1%, and can sometimes even outperform full precision (32-bit) models. Our experiments on empirical measurement of sharpness also suggest that our method would lead to flatter minima compared to other quantization methods.