 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Closed-model Adversarial Examples with Bayesian Neural Modeling for Enhanced End-to-End Speech Recognition
Feb 17, 2022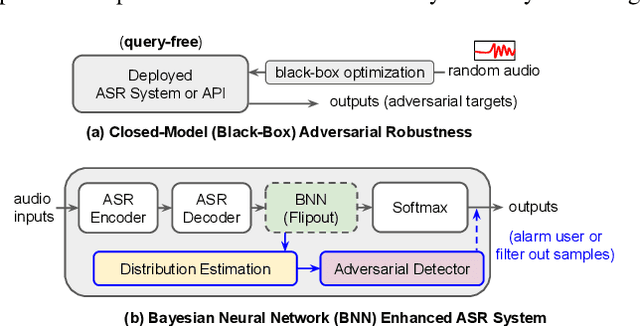

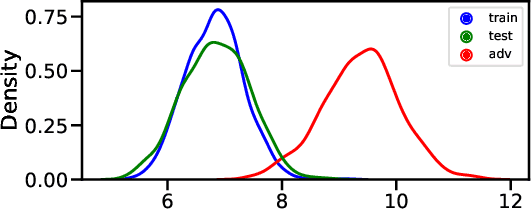
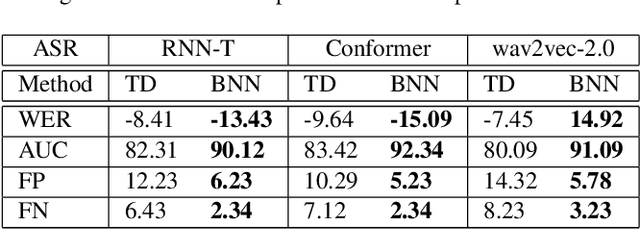
In this work, we aim to enhance the system robustness of end-to-end automatic speech recognition (ASR) against adversarially-noisy speech examples. We focus on a rigorous and empirical "closed-model adversarial robustness" setting (e.g., on-device or cloud applications). The adversarial noise is only generated by closed-model optimization (e.g., evolutionary and zeroth-order estimation) without accessing gradient information of a targeted ASR model directly. We propose an advanced Bayesian neural network (BNN) based adversarial detector, which could model latent distributions against adaptive adversarial perturbation with divergence measurement. We further simulate deployment scenarios of RNN Transducer, Conformer, and wav2vec-2.0 based ASR systems with the proposed adversarial detection system. Leveraging the proposed BNN based detection system, we improve detection rate by +2.77 to +5.42% (relative +3.03 to +6.26%) and reduce the word error rate by 5.02 to 7.47% on LibriSpeech datasets compared to the current model enhancement methods against the adversarial speech examples.
Adversarial Music: Real World Audio Adversary Against Wake-word Detection System
Dec 06, 2019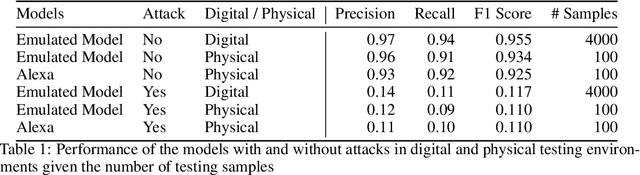
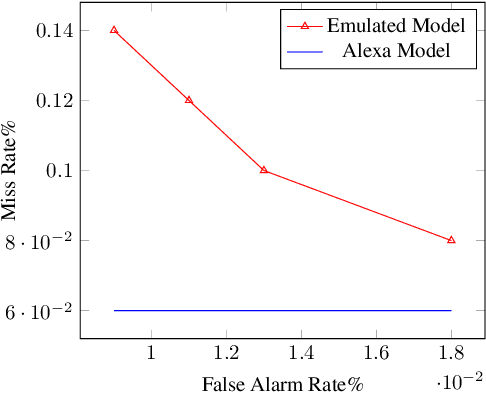

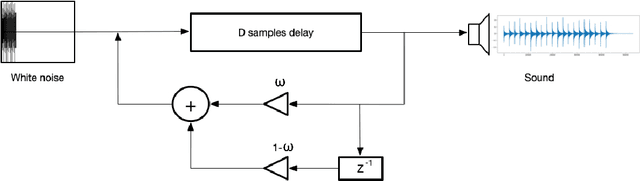
Voice Assistants (VAs) such as Amazon Alexa or Google Assistant rely on wake-word detection to respond to people's commands, which could potentially be vulnerable to audio adversarial examples. In this work, we target our attack on the wake-word detection system, jamming the model with some inconspicuous background music to deactivate the VAs while our audio adversary is present. We implemented an emulated wake-word detection system of Amazon Alexa based on recent publications. We validated our models against the real Alexa in terms of wake-word detection accuracy. Then we computed our audio adversaries with consideration of expectation over transform and we implemented our audio adversary with a differentiable synthesizer. Next, we verified our audio adversaries digitally on hundreds of samples of utterances collected from the real world. Our experiments show that we can effectively reduce the recognition F1 score of our emulated model from 93.4% to 11.0%. Finally, we tested our audio adversary over the air, and verified it works effectively against Alexa, reducing its F1 score from 92.5% to 11.0%.; We also verified that non-adversarial music does not disable Alexa as effectively as our music at the same sound level. To the best of our knowledge, this is the first real-world adversarial attack against a commercial-grade VA wake-word detection system. Our code and demo videos can be accessed at \url{https://www.junchengbillyli.com/AdversarialMusic}
* 9 pages, In Proceedings of NeurIPS 2019 Conference