 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASR2K: Speech Recognition for Around 2000 Languages without Audio
Paper and Code

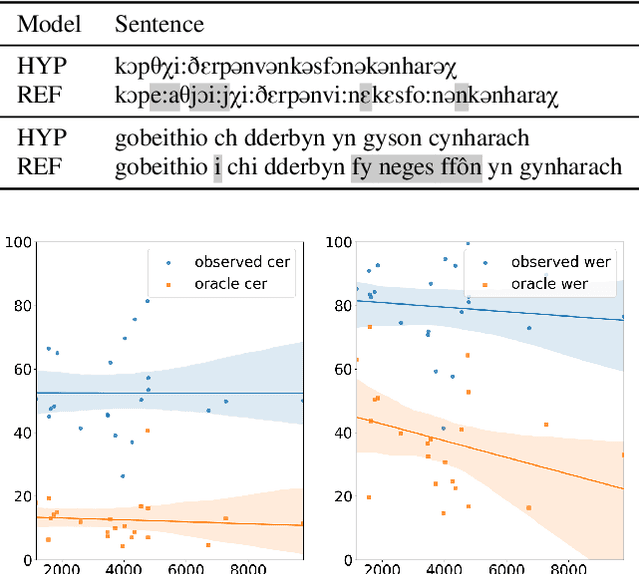
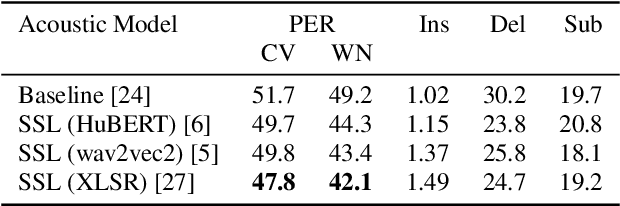
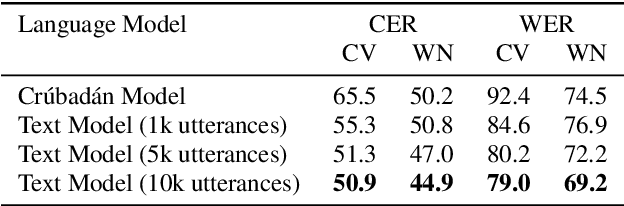
Most recent speech recognition models rely on large supervised datasets, which are unavailable for many low-resource languages. In this work, we present a speech recognition pipeline that does not require any audio for the target language. The only assumption is that we have access to raw text datasets or a set of n-gram statistics. Our speech pipeline consists of three components: acoustic, pronunciation, and language models. Unlike the standard pipeline, our acoustic and pronunciation models use multilingual models without any supervision. The language model is built using n-gram statistics or the raw text dataset. We build speech recognition for 1909 languages by combining it with Crubadan: a large endangered languages n-gram database. Furthermore, we test our approach on 129 languages across two datasets: Common Voice and CMU Wilderness dataset. We achieve 50% CER and 74% WER on the Wilderness dataset with Crubadan statistics only and improve them to 45% CER and 69% WER when using 10000 raw text utterances.